来源:内容由半导体行业观察(ID:icbank)
编译自datanami
,谢谢。
硬件初创公司 d-Matrix 日前表示,在获得4400 万美元的A 轮融资后,公司继续开发一种新颖的“小芯片”架构,该架构将6 纳米芯片嵌入 SRAM 内存模块中来加速 AI 工作负载。其目标是为当今的大型语言模型提供一个数量级的推理效率提升,这些模型正在推动自然语言处理 (NLP) 可以做的事情。
众所周知,
OpenAI
的 GPT-3、
微软
的 MT-NLG 和
谷歌
的 BERT等
大型语言模型
的流行,是过去 10 年来 AI 最重要的发展之一。由于它们的大小和复杂性,这些transformer模型可以在以前不可能的水平上展示对人类语言的理解。他们还可以很好地生成文本,以至于《纽约时报》最近写道,他们
很快就会出书
。
采用这些transformer模型的激增引起了大公司的注意,它们依赖它们进行各种尝试,包括创建更好的聊天机器人、更好的文档处理系统和更好的内容审核等等。但是为这个人工智能提供最后一英里的连接是一个越来越受到关注的难题。
尤其是,人工智能推理问题引起了两位具有半导体行业背景的工程师的注意,其中包括之前在
英特尔工作的 CEO Sid Sheth,以及在德州仪器 (
Texas Instruments
) 工作过的 CTO Sudeep Bhoja 。在 2019 年共同创立
d-Matrix
之前,两人都曾在 Inphi(现为
Marvell
)和
Broadcom工作过。
“我们认为这将持续很长时间,”Sheth 谈到现在支持 Alexa 和 Siri 的大型语言模型时说。“我们认为,在接下来的 5 到 10 年里,人们基本上会被transformers所吸引,而这将成为未来 5 到 10 年人工智能计算的主要工作量。”
但是有一个问题。虽然今天的大型语言模型在训练部分由 GPU 提供了良好的服务,但推理部分的最佳计算架构尚未定义。如今,许多客户都在 CPU 上运行推理工作负载,但随着模型变得越来越大,这变得越来越不可行。Sheth 说,这让客户陷入了困境。
大型语言模型是为 NLP 工作负载设计的一种神经网络
“我认为客户想要弄清楚的是,[CPU] 效率不高,所以我应该跳到 GPU 上吗?还是应该跳到加速器上?” Sheth 告诉Datanami。“如果我要直接跳转到加速器并跳过 GPU,那么我应该跳转到的正确加速器架构是什么?这就是我们专注的地方。”
无论出现什么架构,Sheth 都怀疑它会是 GPU。他说,虽然 GPU 在推理方面取得了进展,但它们并不适合工作负载。
“GPU 从来没有真正为推理而构建,”他说。“它真的是为训练而建造的。这一切都与高性能计算有关。推理是关于高效计算的。”
d-Matrix 在 2019 年做的第一件事是确定 Sheth 和 Bhoja 想到的新内存处理架构将使用哪种内存。虽然 DRAM 已经成熟并适用于各种计算,但将数据移入和移出 DRAM 的成本实在是太高了,尤其是当具有数十亿参数的现代语言模型中的所有权重都需要保存在内存中时支持优化计算所需的矩阵数学。
“例如,DRAM 访问量约为每字节 60 皮焦耳,计算量为 50 到 60 飞焦耳。这是三个数量级[更高],”Bhoja 告诉Datanami。“所以你不想从 DRAM 中移动一些东西并计算一次。您希望在内存中进行计算。而 DRAM 工艺在这方面并不是很擅长。”
Bhoja 继续说,闪存方面出现了一些有趣的发展。“这比 DRAM 有趣一点。所以你要做的就是将权重存储在闪存单元上,然后在闪存单元上进行计算,”他说。“但随着这些大型语言模型变得非常大,不可能构建可以将所有这些、所有权重放在一个地方的闪存单元。”
最终,两人找不到可重新编程且高效的闪存技术,因此他们一直在寻找。
“新的内存类型很有趣,RRAM [电阻式 RAM] 和 MRAM [磁阻式 RAM],”Bhoja 说。“但他们还没有完全到那里。因此,当我们审视一切时,SRAM 是唯一足够成熟的技术。它可用于主流 CMOS 工艺。我们不必重新发明流程。我们可以在内存中混合计算,然后就可以解决了。”
SRAM 或静态随机存取存储器比 DRAM 更快且更昂贵。它通常用于 CPU 的高速缓存和内部寄存器,而 DRAM 通常用于主存储器。虽然 SRAM 与 DRAM 一样在断电时会丢失其数据,但 SRAM 还具有不需要像 DRAM 那样定期刷新的优点。
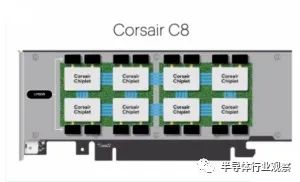
d-Matrix 开发了一种名为 Nighthawk 的概念验证,以证明其 SRAM 内存计算实际上可以工作。Nighthawk 展示了 d-Matrix 的“chiplet”方法的可行性,它将芯片嵌入到 SRAM 模块中,这些模块位于插入 PCI 总线的卡上。
d-Matrix 计划以多种方式打包其 IP,包括软件、PCIe 卡
“我们有 SRAM,我们基本上将模型的权重存储在我们的 SRAM 阵列中,然后我们在 SRAM 中进行计算,”Bhoja 说。“我们将计算和内存混合在一起。DRAM 不是理想的工艺。SRAM 是理想的工艺。”
Bhoja 说,DRAM 和 SRAM 之间存在权衡。就纯内存架构而言,DRAM 更好。但当你想混合内存和计算时,SRAM 更好,他说。
“DRAM 晶体管的密度要高得多,”他说。“SRAM 处理器更大,因此芯片可以更大。这是我们看到的加速Transformer 的唯一方法。”
Bhoja 说,Transformer 模型很大,处理单个句子需要大量计算。他说,配备 8 个 A100 GPU 的 Nvidia DGX 机器可以在 GPT-3 上每秒解析半个句子。在每瓦特的基础上,GPT-3 的推理需求是每瓦特每秒 8 个句子。
“所以我们正在尝试构建定制硅来解决这个问题,即转换Transformer 的能源效率问题,”他说。“你可以训练的东西和你可以部署的东西之间有很大的差距。”
该公司已经完成了其 Nighthawk 小芯片架构的首次概念验证。该公司已与
台积电
签订合同,以开发这些采用 6 纳米工艺的小芯片。Bhoja 说,测试表明,d-Matrix 的 SRAM 技术在推理工作负载方面的效率是 Nvidia A100 GPU 的 10 倍。
d-Matrix 还开发了名为 Jayhawk 的芯片对芯片互连,这将允许将配备 Nighthawk 小芯片的多个服务器串在一起以进行横向扩展或纵向扩展处理。
“既然这两个关键的 IP 部分都已得到证实,该团队正忙于执行……Corsair,这是将在客户处部署的产品,”Sheth 说。
Sheth 表示,d-Matrix 今天宣布的 A 系列 4400 万美元将有助于开发 Corsair,该项目应在 2023 年下半年准备就绪。
A 系列投资由美国风险投资公司 Playground Global 牵头,M12(微软风险基金)和 SK 海力士参与。这些新投资者加入了现有投资者 Nautilus Venture Partners、Marvell Technology和 Entrada Ventures 的行列。
Playground Global 的风险合伙人 Sasha Ostojic 表示,很明显需要在 AI 计算效率方面取得突破,以服务于新兴市场的超大规模和边缘数据中心市场的推理。
“d-Matrix 是一种新颖的、可防御的技术,它可以超越传统的 CPU 和 GPU,通过其软件堆栈解锁并最大限度地提高能效和利用率,”Ostojic 在新闻稿中说。“与这支经验丰富的运营商团队合作,构建这种急需的、不折不扣的技术,我们感到无比兴奋。”
虽然它的硬件目标是超大规模,但该计划要求 d-Matrix 最终提供一个小型服务器,即使是中小型企业也可以部署它来运行他们的 AI 工作负载。
★ 点击文末
【阅读原文】
,可查看本篇原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3017内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!