
[原创] 从Hotchips 2020看芯片界热点
台积电(TSMC) 7纳米
会议所有的报告都是基于已经tape out的芯片,有的是新鲜热辣刚刚出炉,有的是已经投入应用。纵观所有的报告芯片,最先想到的关键词就是 TSMC 7纳米。包括Marvel, AMD, Nvidia, Microsoft, Xilinx和Barefoot的芯片都是用 TSMC 7nm FinFet 工艺,有的片子现在用的工艺不是这个工艺,但主讲人也特别提及到下一代芯片会用TSMC 7nm. 这也反映出来TSMC在工艺上的主导地位,他家的最新工艺基本上就是行业高性能芯片的首选。在这里提一句题外话,前一段时间财富全球前500出炉的时候,TSMC的盈利率在500企业中排名第一,达到31%, 比第二名的巴菲特Berkshire Hathaway投资公司还高。TSMC作为一个传统制造业企业,创造了这个盈利率成绩实在是让人刮目相看,也是巨大的研发投入做到行业第一带来的巨大回报的典型商业成功案例。
表 : 各家芯片的工艺统计

Intel 仍是业界的龙头
Intel这一两年来真是流年不利,10nm工艺虽然在起初公布的时候和TSMC 7nm集成度相当,但是在良率上一直存在问题导致10nm产品一拖再拖难产。而在移动cpu市场上更加被AMD侵蚀,往日的X86 CPU江湖大佬地位岌岌可危。这次会议第一天的主题演讲(Key Note)还是由Intel的首席架构师 Raja Koduri主讲。这样的安排除了是因为Intel是会议的唯一最高长铑级(Rhodium) 赞助商外,业界对Intel还是相当的敬重的,希望Intel在后摩尔时代能带领行业继续前进。Raja的演讲的确是高屋建瓴,回顾过去,展望将来,摩尔定律没死!而在演讲末尾展示出来的一些从器件到封装各级的集成度仍然还有巨大提升的空间,而且这些集成已经是在实验室实现了的。当然了,量产良率和成本是另一回事。大家听到这些消息还是大大的被打了鸡血的。这篇主题演讲还时不时提及刚刚宣布离职的cpu设计大佬Jim Keller, 让人唏嘘不已。要知道这个主题演讲本来是安排给Jim Keller主讲的,因为Jim突然离职而临时换了人。
而在产品方面,Intel也不负众望,推出了下一代 Tiger Lake 移动CPU, Xe架构的GPU, Agilex FPGA 和Tofino2高速交换机芯片。每一样都是拳头主打,性能直接硬拼对手。其中重头戏是Tiger Lake CPU, 在问答的时候Intel几乎避开所有的问题,只说待到九月2号正式发布的时候才有更多具体资料。到时候Intel会不会推出一款 12/16 cores的移动CPU抢回笔记本的地盘?让我们拭目以待。
RISC-V
RISC-V架构提出多年,而且在技术上被抱以厚望。但是这些年工业界的推动力明显不够,目前的商业化状态还是让人比较失望的。可喜的是在Hotchips这样的行业会议上人们仍然没有忘记它。这次会议有两篇RISC-V的演讲,一是阿里巴巴的玄铁-910, 另一个是苏黎世联邦理工学院的4096 cores MantiCore. 玄铁-910采用TSMC 12纳米的工艺,运行主频可达2.5GHz. 阿里巴巴也开发出来了自己的RISC-V编译器进一步优化系统性能,在 EEMBC 和 nBench 大部分项目性能指标上都超越了 Arm Cortex A73. 而MantiCore是靠多Core并行并提高了浮点计算的效率,fp64 效率是其它几个芯片的数倍,而fp32效率也普遍比其它CPU/GPU要高。这个芯片将在ML领域上大有可为。
会议里也有好几个 ARM 架构的芯片演讲, 作为当前市场的主导者,ARM的市场占有率还是完全超越 RISC-V 架构的。而软银要出售ARM的消息目前还不明朗, Nvidia收购的呼声很高。笔者认为,ARM目前作为一家独立运营公司,其商业模式是license自家的arm 架构。ARM和其客户之间并没有什么产品层面的竞争。但如果一家芯片公司Nvidia收购arm之后,势必会改变这种势态。不排除Nvidia的竞争者为了区分自己的产品而撇弃ARM而选择其它架构。这样看来如果收购成功,说不定能成为RISC V 在工业界推广的一大契机。
AI, ML
AI和ML的硬件化概念已经提出来了一段时间,但是强劲的市场需要还是把这两个领域留在芯片热点。这次会议的第二天的主题演讲也是留给了AI巨头DeepMind公司的 Dan Belov. 这篇主题演讲回顾了AI 发展的过去和目前遇到的瓶颈,也深入讲解了一下当前的 Encoder -> Processor -> Decoder 的 通用ML 架构。同时也感慨当前硬件的算力赶不上 AI 发展的需要,而软件方面仍然低效。2020年 AI 的一个应用会不会是编译器的优化呢?让我们拭目以待。

而会议也特别安排了两个 ML 的专题,分别为 ML traning 和 ML interence. 各家都展现出各自的看家本领。其中有Google家的 TPU v2 和 TPU v3, 把 Tensorflow的算力进一步大大提升。其中 TPU v2开始把 单处理器模式的 TPU v1 扩展到可以堆和的超级计算机模式。而 TPU v3则在 v2的基础上提高了 30%的主频, 30%的HBM带宽,100%的 HBM 容量。另外还有 Cerebras公司的单硅片AI 芯片, 整个芯片就是一块12寸硅片,也是当前最大的芯片记录。而最后一篇演讲则是 LightMatter 公司的光处理 AI 芯片,这颗芯片看到传统硅工艺的限制而独辟蹊径用片上光处理来做 AI 运算。光运算展示了在延迟和处理容量上的巨大优势,虽然目前应用还有不少限制,但也不妨是AI 芯片的另一个出路。值得一提的是在两个ML专题中,业界传奇人物伯克利大学教授 David Patterson 在 Slack 频道里非常活跃,对演讲人提出了不少很详细的问题。这也说明了学术界对AI/ML方向的特别关注。
GPU
疫情推高了一大批游戏公司的股价,而电子游戏在现代人的眼光里也渐渐改变。大家对电子游戏的看法也越来越正面,年轻一代对游戏设计的热情也是越来越高。可以预计在不远的将来,游戏将是人类生活的重要部分。这次会议的GPU部分有三大巨头露面,分别是Intel, Nvidia和微软Xbox。这里重点提一下Xbox的最新一代GPU. 这个GPU继承了上一代的架构,里面嵌入8块AMD设计的 Zen2 CPU Core 3.8GHz。而GPU本身运行在1.825GHz, 处理能力达 12TFLOPS FP32, 并带有 3328个流处理器。而DRAM则采用了16GB 的 GDDR6. 有意思的是这个芯片的内部版图和上一代非常类似,而芯片面积也是差不多。
Xbox GPU架构
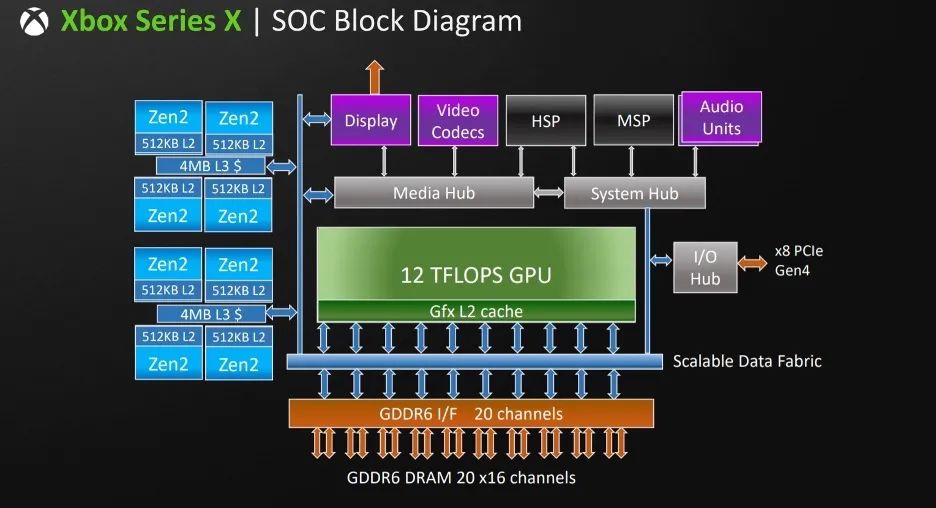
Scalable, Software, System
Hotchips虽然是芯片设计领域的会议,但是大部分演讲并不是简单地停留在芯片上,而花了不少篇幅讲到软件和系统级的集成。一位演讲者说,芯片离开了软件和系统就什么都做不了。以芯片为核心的一套高效的软硬件结合系统才是可以商业推广应用的优秀系统。会议里也多次提到可扩展式的设计,也是分别体现在系统的各个层面上: 芯片架构内部比如可以放置1, 2, 4个处理单元,并用高效的片上网络把这些单元链接起来; 在封装层面也是可以把好几个芯片和 HBM/DDR 封装在一起;在系统集成上更是可以用高带宽的网络把大量芯片集结在一起组成一个巨大的处理网格。
中国元素
华人在世界半导体行业一直占着重要地位,近几年随着国内半导体产业的强劲发展,本土的芯片公司也开始发力,频频在顶级芯片会议上露面。这次的会议阿里巴巴交出了三张完美的答卷:玄铁-910 RISC-V core, 含光800 NPU和Bare Metal云端服务器的X-Dragon架构。而百度也展现了昆仑 AI 处理器系统。值得一提的是华人电子工程教授谢源教授也是整个会议的主委之一,同时也是其中一个板块的主持人。各个华人的面孔也见证了中国半导体特别在高性能芯片设计领域占有一席之地,期望即将迎来腾飞的局面。
结语
虽然Hotchips的主题只覆盖芯片领域的一小部分,但是总体上每一个演讲里的芯片都是在该领域内最好的产品并体现了世界一流的设计水平。两天的大会下来,各个精彩的演讲真是让所有参与者大饱眼福。这次的会议只租了一个工作室做直播间,各个报告是用视频发放到与会者,同时大会设立Slack频道让与会者和演讲者互动,主持人会把大家在Slack里面的问题挑出来让演讲者回应。这次的网络会议也是给出了一个很好的在线研讨会的模式。虽然偶尔有一点网络连接异常导致的短暂中断,但总体上不管是演讲还是交流互动都是非常高效的。笔者参加会议下来也是收获颇丰。如果读者对这次Hotchips会议的某一个具体主题感兴趣,也可联系笔者做更详细的介绍。
半导体行业观察收集了Hotchips 2020年的部分演讲slide,您可以把本篇文章转载到朋友圈,并回复“hotchips PPT”到半导体行业观察公众号后台,获取下载链接。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2415期内容,欢迎关注。
推荐阅读
★ 晶圆代工全面爆发
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
晶圆|蓝牙 | 5G|EDA|华为|英伟达|封装|手机芯片
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号