亚马逊服务器芯片详解,性价比吊打竞争对手
2020-03-11
14:00:12
来源: 半导体行业观察
来源:内容由半导体行业观察(ID:icbank)翻译自「
anandtech
」,作者:Andrei Frumusanu,谢谢。
自亚马逊发布其第一代基于Graviton Arm的处理器内核以来已经一年半了,它在AWS EC2中作为所谓的“ A1”实例公开提供。尽管该处理器在性能上并没有给人留下深刻的印象,但这释放了他们未来几年的信号和跨出了第一步。
今年,亚马逊在加倍努力,在去年12月宣布了新的Graviton2处理器,他们计划在未来几个月内公开EC2。在最新一代处理器上,他们采用了Arm的新型Neoverse N1 CPU微体系结构和网状互连,这是我们在一年多前详细介绍的面向基础架构的组合平台。该平台是对先前基于Arm的服务器尝试的一次重大突破,Amazon的目标无非是领先竞争地位。
亚马逊为云服务设计定制SoC的努力始于2015年,当时该公司收购了以色列的初创公司Annapurna Labs。Annapurna以前曾致力于以网络为中心的Arm SoC,这些 SoC主要用于NAS设备等产品。在亚马逊的领导下,该团队的任务是创建定制的Arm服务器级芯片,而新的Graviton2是他们的首次重磅尝试。
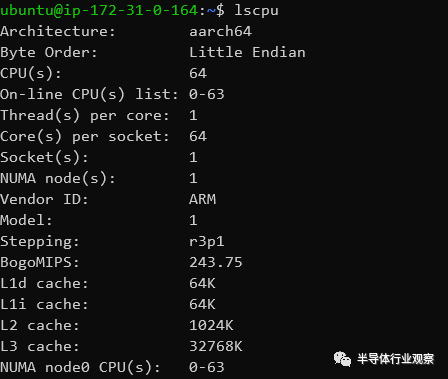
那么,Graviton2是什么?它是一款64核单片服务器芯片设计,使用了Arm的新Neoverse N1内核(移动Cortex-A76内核的微体系结构派生产品)以及Arm的CMN-600网格互连。这是一个非常简单的设计,基本上与该公司一年前提出的Arm的64核参考N1平台几乎相同。但亚马逊也确实为其带来了一些差异,例如Graviton2的CPU内核的时钟频率较低,为2.5GHz,并且仅将32MB而不是64MB的L3高速缓存包含到网状互连中。该系统由8通道DDR-3200存储器控制器支持,并且SoC支持64个PCIe4通道用于I / O。它是N1平台的相对教科书般设计实现,在TSMC的7nm工艺节点上制造。
Graviton2的潜力当然是由新的N1内核实现的。我们已经看到了Cortex-A76 在去年的移动系统级芯片上的惊人表现,N1微架构有望带来更好的性能和服务器级功能,所有同时保持Arm公司产品在移动领域取得成功的关键——高能源效率。N1内核保持非常纤薄和高效,在Graviton2中实现1MB L2缓存,预计只用到1.4mm²的硅空间,并且在亚马逊新芯片到达的2.5GHz频率下,每个内核具有约1W的出色电源效率。。
尽管我们能够在云端测试新芯片组,但该公司仍在为此其设计的某些方面的神秘。为此在我们的文章中,Amazon不太愿意透露SoC的总功耗。Arm预计64核2.6GHz实施的功耗约为105W,以及Ampere最近披露的其80核3GHz N1服务器芯片的功耗为210W,考虑到该芯片的时钟频率更为保守,我们估计Graviton2必须在估计值低至80瓦之间,而悲观的投影则介于110瓦之间。
鉴于Amazon的Graviton2是专门为满足亚马逊需求而设计的垂直集成产品,因此我们有必要在其预期的环境中测试新芯片组(除此之外,它还无法以其他任何方式使用!)。在过去的几周中,我们已经获得了对Amazon Web Services(AWS)弹性计算云(EC2)新的基于Graviton2的“ m6g”实例的预览访问权限。
对于不熟悉云计算的读者来说,从本质上讲,这意味着我们已经在Amazon的数据中心中部署了虚拟机,该服务以Amazon闻名于世,现在已占该公司收入的主要份额,为一些最大的互联网服务提供了动力。
决定此类实例功能的重要指标是其类型(本质上决定了底层硬件所采用的CPU体系结构和微体系结构)以及可能的子类型。在Amazon的情况下,这是指专门用于特殊用例的平台的变体,例如具有更好的计算功能或具有更高的内存容量功能。
在今天的测试中,我们可以访问专为通用工作负载设计的“ m6g”实例。“6”的命名是代表亚马逊第六代EC2硬件,带有Graviton2的产品是目前唯一使用这个名称的平台。
除了实例类型之外,定义实例功能的最重要的其他指标是其vCPU数量。“虚拟CPU”本质上是指虚拟机可用的逻辑CPU内核。亚马逊提供的实例数量从1个vCPU到最多128个,在最受欢迎的平台中最常见的实例有2、4、8、16、32、48、64和96。
Graviton2是不带SMT的单路64核平台,这意味着最大可用vCPU实例大小为64。
但是,这也意味着,在谈论SMT附带的平台时,我们在比较中有点像苹果和橘子的难题。当谈论64个vCPU实例(在EC2语言中为“ 16xlarge”)时,这意味着对于Graviton2实例,我们将获得64个物理核心,而对于AMD或Intel系统,我们将仅获得32个具有SMT的物理核心。我敢肯定会有一些读者会考虑这种比较“不公平”,但是就交付吞吐量而言,这也是亚马逊的定位,最重要的是,不同实例类型之间的等效定价。
今天的文章将重点介绍Graviton2的两个主要竞争对手:AMD EPYC 7571(Zen1)驱动的m5a实例和Intel Xeon Platinum 8259CL(Cascade Lake)驱动的m5n实例。在撰写本文时,这些是两个x86现有人员可用的最强大的实例,并且应提供最有趣的比较数据。
需要注意的是,我们很希望能够在此比较中包含基于AMD EPYC2 Rome(c5a / c5ad)的实例;亚马逊宣布他们去年11月一直在进行此类部署,但可惜该公司不愿意与我们分享预览访问权限(给出的一个原因是Rome C型实例与Graviton2的M型相比不是一个很好的比较)实例,尽管这实际上没有任何技术意义)。随着这些实例越来越接近预览可用性,我们将在另一篇文章中进行研究,以补充竞争格局中这一重要难题。
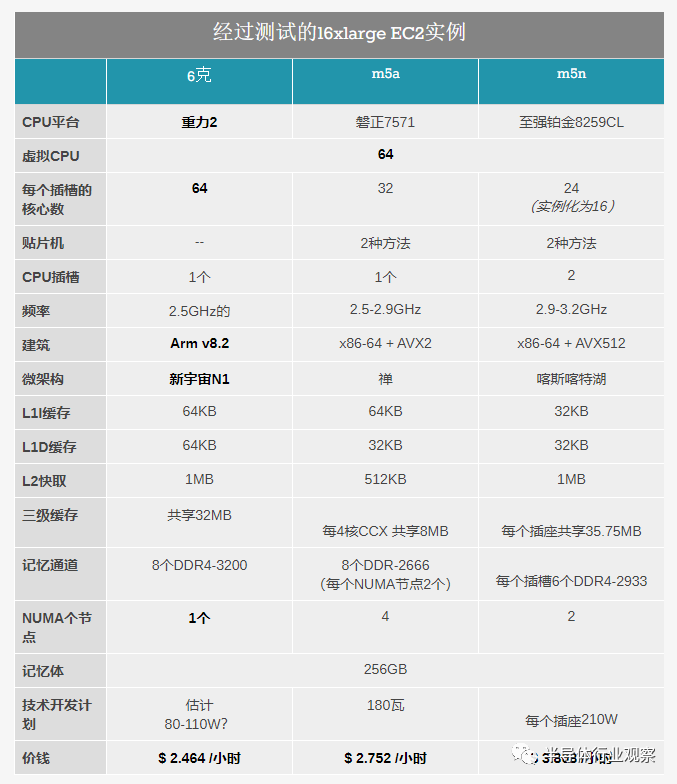
将Graviton2 m6g实例与AMD m5a和Intel m5n实例进行比较,我们发现为VM提供支持的硬件功能存在一些差异。同样,最臭名昭著的区别是,Graviton2附带的物理核计数与已部署的vCPU数目相匹配,而竞争对手也将SMT逻辑核也视为vCPU。
在谈论更高vCPU数量的实例时,其他方面是您可以接收跨越多个套接字的VM。由于EPYC 7571有32个内核,所以AMD的m5a.16xlarge仍能够在单个插槽上部署VM,但是英特尔的至强系统在这里使用了两个插槽,因为EC2中目前没有部署英特尔的硬件,但它可以在一个插槽中提供所需的vCPU数量。
EPYC 7571和Xeon Platinum 8259CL都是未公开发售的零件,甚至都未在任何一家公司的SKU列表中列出,因此它们是Amazon等用于数据中心部署的自定义零件。
AMD部件是基于32核Zen1的单插槽解决方案(至少对于我们测试中的16xlarge实例而言),在轻线程环境中,时钟频率为2.5 GHz,最高可达2.9 GHz。该系统的特殊性在于它受到AMD的四芯片MCM系统的一定限制,该系统具有四个NUMA节点(每个芯片一个和2通道内存控制器),这一特性已在基于EPYC2 Zen2的较新系统中消除。我们没有具体的数据确认,但我们怀疑这是根据SKU编号的180W部件。
英特尔至强铂金8259CL基于较新的Cascade Lake世代CPU内核。此特定部分也特定于Amazon,每个插槽包含24个启用的核心。为了达到16倍大的64个vCPU数量,EC2为我们提供了双插槽系统,每个插槽上实例化了24个内核中的16个。同样,我们对此事没有任何确认,但这些部件的每个插座的额定功率应为210W,或总计420W。我们必须提醒自己,尽管我们确实可以访问系统的全部内存带宽和缓存,但在我们的实例中我们只使用了66%的系统内核。
这里的缓存配置特别有趣,因为平台之间的情况相差很大。实际CPU本身的专用缓存相对来说是不言自明的,并且Graviton2在这三者中确实提供了最大的缓存容量,但在其他方面与Xeon平台相同。如果我们按线程划分可用缓存,则Graviton2能做1.5MB,领先于EPYC的1.25MB和Xeon的1.05MB。Graviton2和Xeon系统具有明显的优势,即它们的最后一级缓存在整个插槽中共享,而AMD的L3仅在4核CCX模块之间共享。
在具有实际多个进程的并行处理工作负载中,系统之间的NUMA差异并不重要,但是它将对多线程以及单线程性能产生影响,并且Graviton2的统一内存体系结构将在一些场景。
最后,实例之间的定价存在很大差异。Graviton2系统的价格为每小时2.46美元,在价格上领先于AMD系统,并且比基于Xeon实例的每小时3.80美元的价格便宜得多。尽管在谈论价格时,我们必须记住,交付的实际价值也将极大地取决于系统的性能和吞吐量,我们将在本文的后面部分对此进行详细介绍。
我们感谢亚马逊为我们提供了对m6g Graviton2实例的预览访问。除了为我们提供访问权限之外,Amazon或任何其他提及的公司都对我们的测试方法产生了影响,我们自己为EC2实例测试时间付费。
解释了各种云实例的硬件配置可能会发生很大变化,即使在纸上它们具有相同的交付“ vCPU”数量,将更多地关注CPU拓扑以及由此产生的方面(例如核心)将是很有趣的到核心的延迟。我对一些僵化或不准确的公共工具感到沮丧,最近我有时间编写一个新的自定义微基准来测试CPU内核的同步延迟,展现一些缓存一致性以及当前设计的物理布局。
我认为首先回过头来展示一下亚马逊第一代Graviton SoC在这方面的表现会很有趣。在Cortex-A72内核的支持下,此设计将其16个内核布置为4个群集,并通过相干的纵横制互连实现了连接。每个4个A72内核集群都有其自己的2MB L2缓存,并且在上述结果中我们清楚地看到了此类集群中的更快访问延迟。从一个群集到另一个群集的一致性带来了很高的损失,几乎使访问延迟增加了三倍。
转移到具有64个N1内核的Graviton2上,我们看到了完全不同的设置,相对更加统一,这是有道理的,因为芯片的内核是通过网状网络连接的,并且芯片是单片式裸片设计。但是,我们确实在延迟中看到了一些奇怪的结果,尤其是编号较低的内核之间的访问延迟似乎比编号较高的内核之间更好。我对这种行为不太了解,因为从理论上讲,延迟应在网格上表现得更均匀。
经过反复试验,我发现结果在各个运行过程中并不一致。更改CPU亲和力确实会对结果产生更大的影响,直到我了解发生了什么。
实际上,我们在以上两个结果集中看到的不是网格上的核心到核心两点延迟,而是系统的核心到缓存到核心三点延迟。Amazon和Arm已经确认了CMN-600的一个特殊方面:缓存行静态地驻留在网格的缓存片上。在内存地址空间中分配高速缓存行时,它会经历一个特殊的哈希函数,该函数确定其物理驻留在哪个网格高速缓存切片上。从系统中的任何CPU访问此高速缓存行时,它始终访问同一物理L3高速缓存切片在芯片上。
Graviton2展示了它可以在性能和吞吐量方面保持极佳的表现,甚至在许多测试中都领先于竞争对手。但是,有时您不太在乎性能,而只是想以最便宜的方式完成一些工作负载,此时价值就发挥了作用。
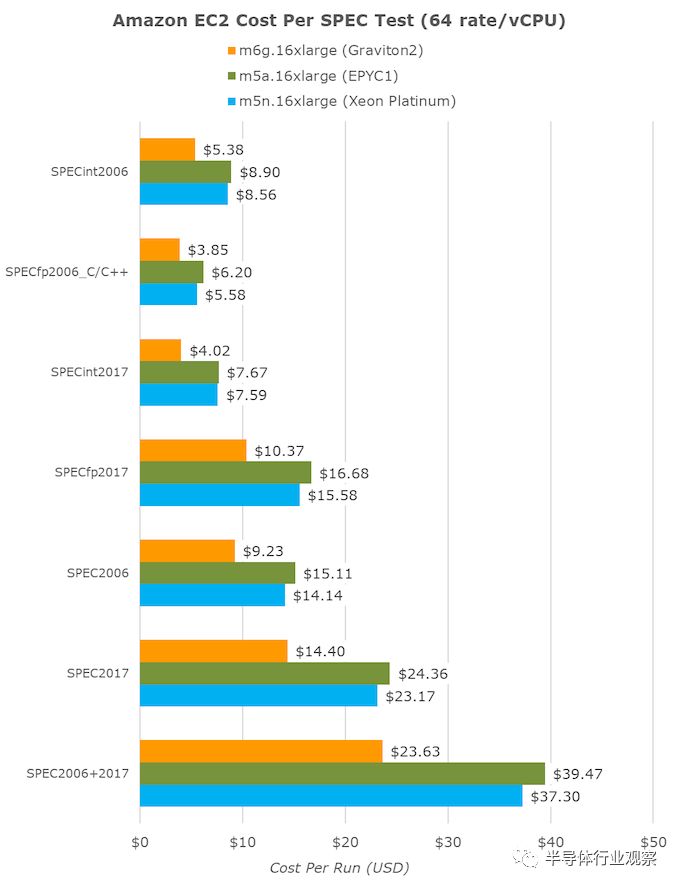
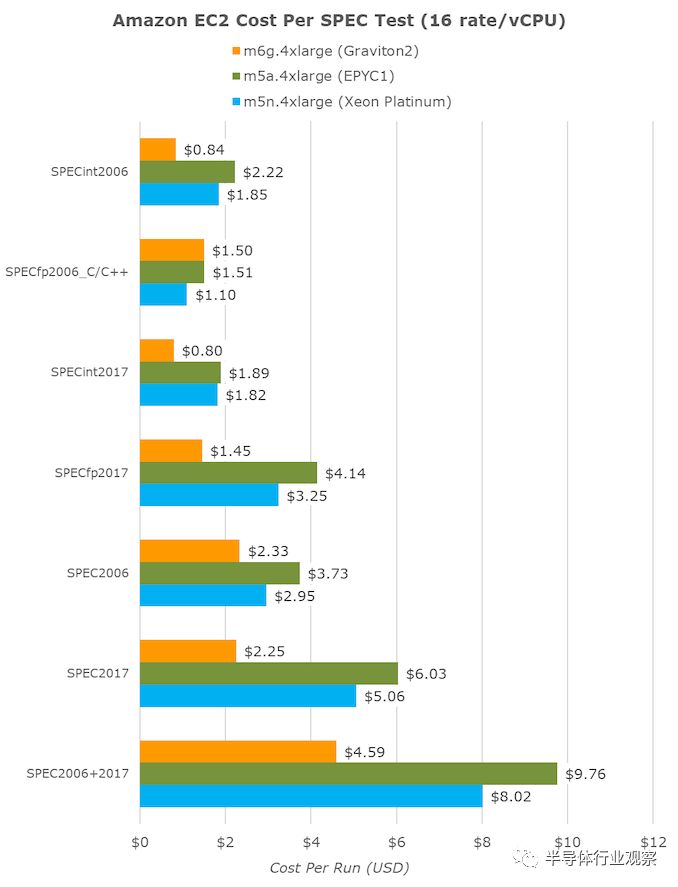
亚马逊确实暗示了这一点,并指出新芯片每美元的性能要比竞争对手高40%。如简介中所述,对于64个vCPU数量为16倍的大型实例,m6g(Graviton2),m5a(EPYC1)和m5n(Xeon Cascade Lake)的每小时成本分别为2.464美元,2.752美元和3.080美元。
将完成各种SPEC测试所需的时间转换为小时,然后乘以小时成本,最终得出了每个固定工作负载成本指标:
总的来说,所有工作负载的总和,有望最终代表各种实际使用案例的代表性数字,我们确实看到Graviton2比竞争对手的平台便宜40%,这是一个了不起的数字。
如果要比较较小实例数下的相同固定工作负载,由于Graviton2具有更好的每线程性能,那么我们将在4xlarge(16 vCPU)实例上看到更好的结果。在这里,亚马逊芯片的价格比至强芯片高43%,比AMD实例便宜53%。
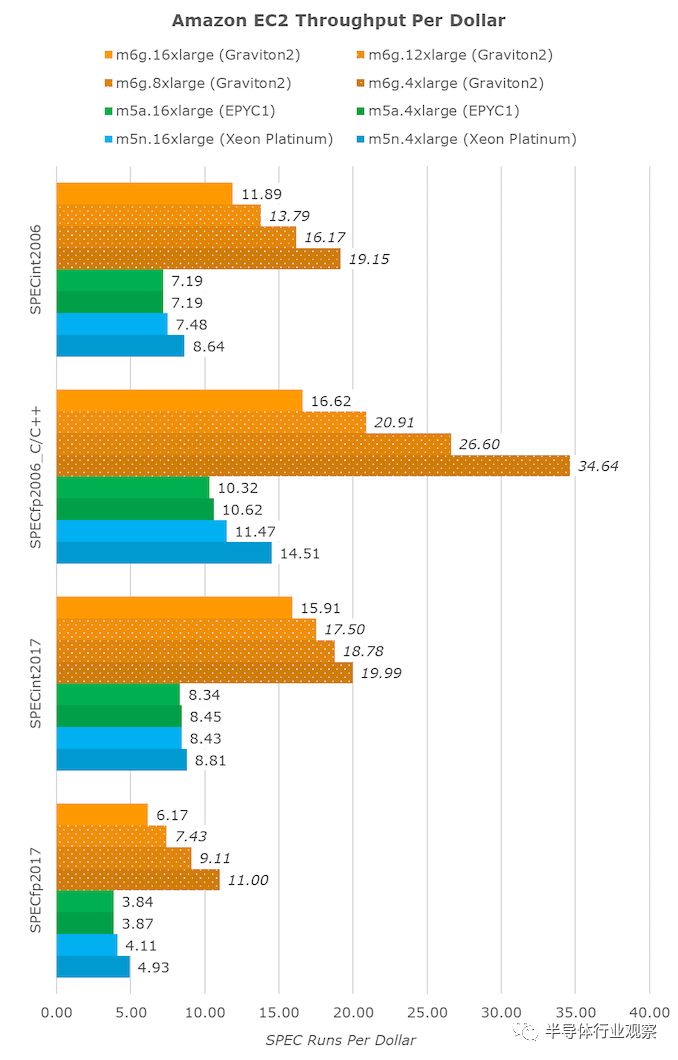
如果将结果转换为固定的每美元吞吐量,我们将再次看到Graviton2遥遥领先。这里的单位是SPEC每1美元运行。
vCPU实例的大小越小,Graviton2的价值似乎就越高,因为随着vCPU数量的增加,它的性能将线性下降,但是较大的vCPU实例的成本将呈线性增长,这几乎在AMD系统中根本不存在,而只是微不足道。存在于Xeon实例中。
同样,Graviton2在这里的缩放比例在生产实例中可能会有所不同,但是鉴于您不能只砍掉一半的芯片(或者在英特尔的情况下只能访问两个插槽之一),而且亚马逊似乎没有做任何事情对芯片共享资源的静态分区,我确实认为在现实世界中很可能会遇到这种性能和价值指标。
即使忽略较低的vCPU实例,亚马逊也能够兑现每美元提高40%的性能的承诺,这对AWS和EC2生态系统来说是一个巨大的改变。
*点击文末阅读原文,可阅读
英文
原文
。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2245期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
“芯”系疫情
|ISSCC 2020|国产芯片
|半导体股价
|
存储
|
Chiplet|氮化镓|高通|华为
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!
责任编辑:Sophie