
HBM 4,打响第一枪
2024-11-19
15:55:09
来源: 互联网
点击
这些年人工智能的火热除了带动GPU的热销以外,HBM无疑是不能忽视的另一个赢家。
知名分析机构集邦咨询发布报告显示,人工智能引发的高带宽内存 (HBM) 需求推动制造商在 2024 年将位供应量增加近三倍,这将使 HBM 收入占 DRAM 市场的 20%。其中,韩国存储公司SK海力士凭借在HBM上提早布局,大有将DRAM对手三星电子拉下马之势。
SK 海力士在最近的一份声明中表示:“公司HBM 销售额表现出色,较上一季度增长超过 70%,较去年同期增长超过 330%。 ”
之所以HBM能拥有如此热度,则需要从人工智能的原理说起。
AI对内存提出高需求
如下图所示,AI通常可以分为两个不同的过程(或者说步骤):分别是AI训练和AI推理。在AI的训练阶段是需要给AI提供大量的数据,让它对这些数据进行分析,提取出其中的规律,形成一个AI模型。为了实现上述目标,我们需要非常大量的数据来进行AI训练,而且这通常会花上很长的时间,才可以进行完整的AI模型的训练。
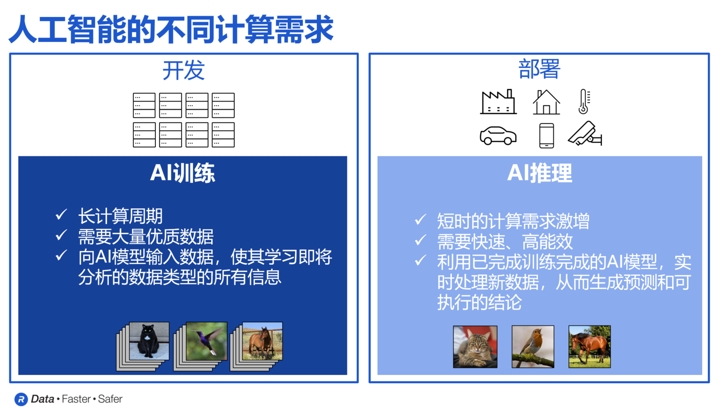
一旦模型完成了基于大量数据的训练,就可以将其应用于实际场景,并提供新的、模型未曾见过的案例进行推理。这就是AI的推理阶段。在这一阶段,我们对性能有较高要求,尤其是在推理速度和准确性上。
在Rambus研究员兼杰出发明家Steven Woo博士看来,AI训练可以说是目前计算领域中最具挑战性和最难完成的任务之一,因为在这个阶段需要管理和处理的数据量极为庞大。而且,如果训练过程能够越快完成,就意味着AI模型能够更早投入使用,从而帮助投资者尽早获得回报,并最大化投资回报率。
“这就对内存提出了额外的要求,需要确保其既足够快速,性能足够强大,尺寸又要足够小。”Steven Woo博士强调。他同时指出,在推理阶段,我们则需要更短的延迟和更高的带宽,因为推理结果必须几乎实时地快速给出。
正是在这两个步骤的推动下,AI对内存的高性能需求各自提出了独特的挑战,推动了内存行业的持续发展。如下图所示,内存对速度、容量和尺寸的要求每年都在以超过10倍的速度增长,而且自2012年以来,这一趋势没有减缓的迹象。
以大语言模型GPT为例,过去几年中,它的参数数量和规模都大幅增长。相关数据显示,在2022年11月发布的GPT-3,使用了1750亿个参数,但到了今年5月发布的最新版本GPT-4o,则使用了超过1.5万亿个参数。
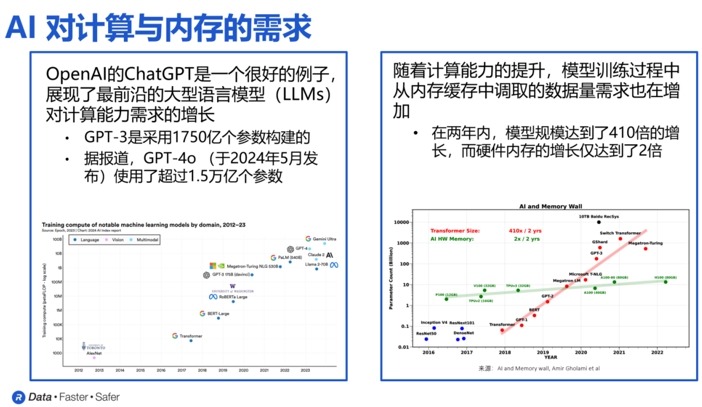
“过去几年里,这些大语言模型的规模增长了超过400倍。我们面临的一大挑战是,在相同时间内,硬件内存的规模仅增长了两倍。这就意味着,要完成这些AI模型的任务,就必须投入额外数量的GPU和AI加速器,才能满足对内存容量和带宽的需求。 ”Steven Woo博士说。
于是,不同类型的内存正在被推向人工智能的核心——数据中心。
从下图左可以看到我们,DDR内存是目前最标准的内存形式,广泛应用于全球各地的服务器和数据中心;低功耗DDR内存LPDDR最初专为移动设备设计,现在还被应用于AI边缘推理系统;GDDR是一种专为图形处理设计的DDR内存,在带宽、成本和可靠性方面实现了良好的平衡,如今也被广泛应用于AI推理任务,同时也被正式应用于汽车和一些网络应用场景。
除此以外,本文的主角HBM因为拥有远高于市面上常见DRAM的带宽和密度,非常适用于AI训练、高性能计算和网络应用。

HBM,发挥重要作用
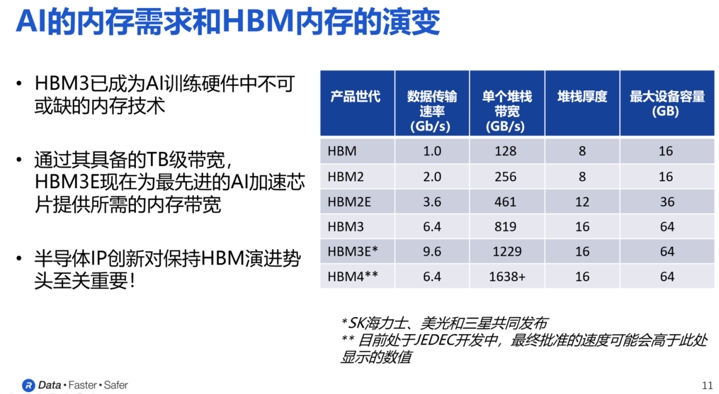
所谓HBM,也就是High Band Memory,也就是所谓的高带宽内存。如下图所示,在过去多年的发展中,HBM已经发展到了第五代的HBM3E。当中,每一代的最明显变化就是单个堆栈带宽的急剧增加。
以现在正在流行的HBM3为例,主要的DRAM制造商,如SK海力士、美光和三星已经宣布推出HBM3E设备,数据传输速率最高可达9.6Gbps。其单个设备的带宽更是超过了1.2TB/s。
之所以能获得如此高的带宽和速度,主要得益于其聪明的设计。
从结构上看,HBM的DRAM内存会通过有一个中间层的物理线,然后与那些处理器进行相应的连接。要实现这个目的,还需要以来图中所示的中介层,之后上面这些部分会共同与一个基板相连接,最后基板焊接在我们的PCB上面;从设计上看,HBM的DRAM堆栈会使用多层堆栈的架构、正是因为这样的一种方式可以提供非常高内存带宽,高容量和高能效。在其中,也会有非常、非常多的晶片堆栈,其中一个内存晶片会与处理器直接相连。
“在HBM3的标准当中,HBM内存有一个非常独特的点,就是它有非常多的线连接到SoC,在HBM3里面是1024根线。”Steven Woo博士表示。
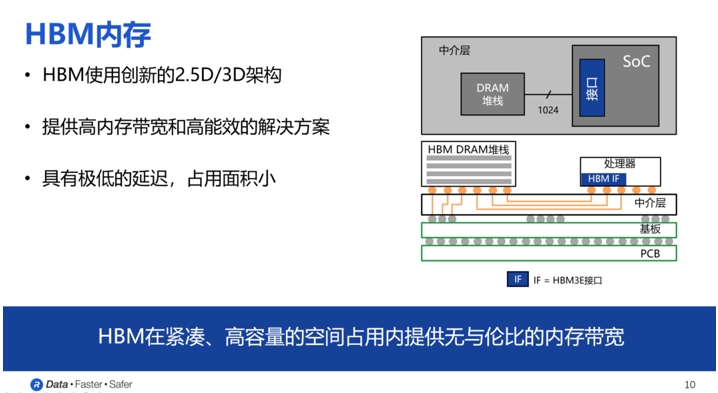
Steven Woo博士指出,随着命令、地址、时钟和其他附加信号的加入,HBM3所需的信号路径数量增加到约1700条。上千条信号路径远远超出了标准PCB所能支持的范围。因此,采用硅中介层作为桥梁,将内存设备和处理器连接起来。类似于集成电路,硅中介层上可以蚀刻出间距非常小的信号路径,从而实现所需数量的信号线来满足HBM接口的要求。
正是由于这种精巧的结构设计和HBM DRAM的堆叠方式,HBM内存才能提供极高的内存带宽、优异的能效、极低的延迟,同时占用最小的面积。但是,因为大模型对带宽的需求还在持续增加中。为此,行业也不停息提升级HBM,这就催生了HBM 4。据透露,HBM4的带宽将达到1.6TB/s。值得一提的是,这只是单个堆栈的带宽,最终的实际带宽可能会更高。
“随着行业推出越来越快的HBM内存器件,Rambus作为内存控制器IP提供商,在这一过程中扮演着重要角色。我们的创新对于最终客户如何使用这些高性能的HBM内存至关重要。”Steven Woo博士重申。
Rambus打响关键一枪
毫无疑问,作为一家在内存系统领域拥有超过30年开发和研究经验的半导体企业,Rambus能够在HBM方面为人工智能行业提供广泛的支持。
Steven Woo博士直言,依托于多年来在HBM内存领域积累的丰富经验。Rambus在HBM市场的份额位居第一,并且已经成功完成了超过100次的HBM设计。在过去发展中,Rambus也成功交付了业界领先的HBM3E内存控制器以及业界最高数据传输速率的HBM2E内存控制器(速率达到每秒4 Gbps)。
“我们始终致力于帮助客户实现一次流片成功,避免重新设计。因此,客户可以放心选择Rambus,因为他们知道我们在构建成功系统方面拥有多年的经验,能够为他们提供所需的全方位支持。”Steven Woo博士表示。

面向正在走向现实的HBM 4,Rambus也在近日带来了业内首款HBM4控制器IP,旨在加速下一代AI工作负载。
据Steven Woo博士介绍,Rambus新发的HBM4内存解决方案是在HBM3性能的基础上进一步提升:一方面,HBM4的控制器IP提供了32个独立通道的接口,总数据宽度可达2048位。而基于这一数据宽度,当数据速率为6.4Gbps时,HBM4的总内存吞吐量将比HBM3高出两倍以上,达到1.64TB/s;
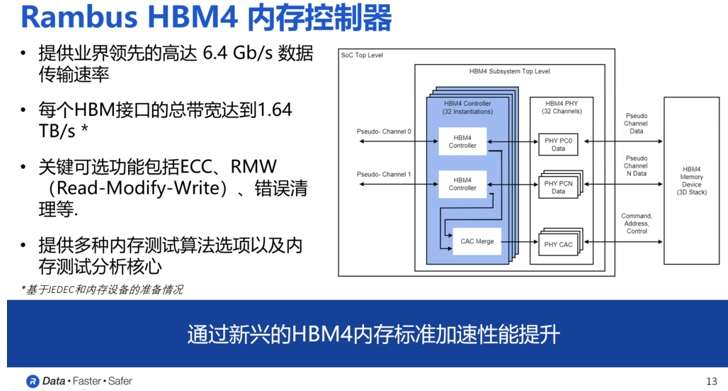
另一方面,与HBM3E控制器一样,Rambus HBM4内存控制器IP也是一个模块化、高度可配置的解决方案。
“根据客户在应用场景中的独特需求,我们提供定制化服务,涵盖尺寸、性能和功能等方面。关键的可选功能包括ECC、RMW和错误清理等。此外,为了确保客户能够根据需要选择各种第三方PHY并应用于系统中,我们与领先的PHY供应商开展了合作,确保客户在开发过程中能够一次流片成功。 ”Steven Woo博士说。他同时还透露,Rambus的客户将在今年晚些时候采用其HBM 4控制器,并在 2025 年将其集成到他们的芯片设计中,这些芯片设计预计最终将在 2026 年上市。
当然,除了HBM 控制器以外,Rambus在很多产品方面能够为AI及其他诸多应用支持。
正如Rambus大中华区总经理苏雷先生所说,Rambus是一家业界领先的半导体IP和芯片提供商。凭借着34年的技术领先地位,Rambus实现了让数据传输更快、更安全的目标。“Rambus专注于数据中心,因为数据中心对最高性能和安全性的需求最大,我们75%的收入都来自于数据中心。”苏雷先生强调。从他的介绍我们得知,纵观半导体价值链,Rambus在三个层面发挥着作用:分别是半导体IP、基础技术和芯片。
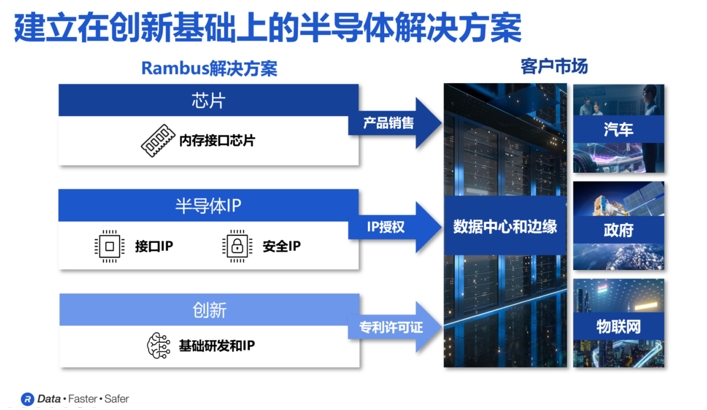
苏雷表示,Rambus的半导体IP产品主要由接口IP和安全IP两大类产品组成。其中,接口IP实现了处理器、加速器和内存之间高性能互联;安全IP保护芯片上静止的数据,处理器和内存之间使用中的数据,以及数据中心中各设备传输中的数据。
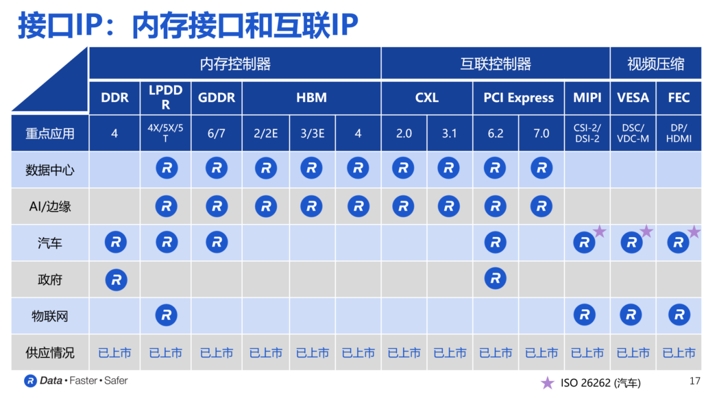
在基础技术方面,据介绍,Rambus在过去34年以来开发了约2800项专利以及专利申请。Rambus的芯片产品则是最大、增长最快的产品系列,为DDR4和DDR5内存模块提供了除DRAM颗粒之外所有的内存模块所需的芯片组,提供模块解决方案,以及一站式服务。
展望未来,Rambus也会持续更新,为客户提供极具竞争力的方案。具体到人工智能方面,如Steven Woo博士所说,为了保持未来的扩展步伐,Rambus认为未来的人工智能将继续需要在性能、功效和内存容量方面取得重大改进,这将需要许多不同的公司共同努力。例如需要内存制造商和像 Rambus 这样的公司将改进内存系统,但处理器厂商也必须通过压缩数据和使用新的数字格式等方式来改进处理。软件开发人员将来也必须与硬件开发人员更多地合作,这种软件和硬件之间的协同设计也将有助于确保软件充分利用可用的硬件。
“Rambus 始终着眼未来,我们在高性能内存架构领域拥有 30 年的经验,一直致力于扩展内存的性能和容量。”Steven Woo博士强调。
知名分析机构集邦咨询发布报告显示,人工智能引发的高带宽内存 (HBM) 需求推动制造商在 2024 年将位供应量增加近三倍,这将使 HBM 收入占 DRAM 市场的 20%。其中,韩国存储公司SK海力士凭借在HBM上提早布局,大有将DRAM对手三星电子拉下马之势。
SK 海力士在最近的一份声明中表示:“公司HBM 销售额表现出色,较上一季度增长超过 70%,较去年同期增长超过 330%。 ”
之所以HBM能拥有如此热度,则需要从人工智能的原理说起。
AI对内存提出高需求
如下图所示,AI通常可以分为两个不同的过程(或者说步骤):分别是AI训练和AI推理。在AI的训练阶段是需要给AI提供大量的数据,让它对这些数据进行分析,提取出其中的规律,形成一个AI模型。为了实现上述目标,我们需要非常大量的数据来进行AI训练,而且这通常会花上很长的时间,才可以进行完整的AI模型的训练。
一旦模型完成了基于大量数据的训练,就可以将其应用于实际场景,并提供新的、模型未曾见过的案例进行推理。这就是AI的推理阶段。在这一阶段,我们对性能有较高要求,尤其是在推理速度和准确性上。
在Rambus研究员兼杰出发明家Steven Woo博士看来,AI训练可以说是目前计算领域中最具挑战性和最难完成的任务之一,因为在这个阶段需要管理和处理的数据量极为庞大。而且,如果训练过程能够越快完成,就意味着AI模型能够更早投入使用,从而帮助投资者尽早获得回报,并最大化投资回报率。
“这就对内存提出了额外的要求,需要确保其既足够快速,性能足够强大,尺寸又要足够小。”Steven Woo博士强调。他同时指出,在推理阶段,我们则需要更短的延迟和更高的带宽,因为推理结果必须几乎实时地快速给出。
正是在这两个步骤的推动下,AI对内存的高性能需求各自提出了独特的挑战,推动了内存行业的持续发展。如下图所示,内存对速度、容量和尺寸的要求每年都在以超过10倍的速度增长,而且自2012年以来,这一趋势没有减缓的迹象。
以大语言模型GPT为例,过去几年中,它的参数数量和规模都大幅增长。相关数据显示,在2022年11月发布的GPT-3,使用了1750亿个参数,但到了今年5月发布的最新版本GPT-4o,则使用了超过1.5万亿个参数。
“过去几年里,这些大语言模型的规模增长了超过400倍。我们面临的一大挑战是,在相同时间内,硬件内存的规模仅增长了两倍。这就意味着,要完成这些AI模型的任务,就必须投入额外数量的GPU和AI加速器,才能满足对内存容量和带宽的需求。 ”Steven Woo博士说。
于是,不同类型的内存正在被推向人工智能的核心——数据中心。
从下图左可以看到我们,DDR内存是目前最标准的内存形式,广泛应用于全球各地的服务器和数据中心;低功耗DDR内存LPDDR最初专为移动设备设计,现在还被应用于AI边缘推理系统;GDDR是一种专为图形处理设计的DDR内存,在带宽、成本和可靠性方面实现了良好的平衡,如今也被广泛应用于AI推理任务,同时也被正式应用于汽车和一些网络应用场景。
除此以外,本文的主角HBM因为拥有远高于市面上常见DRAM的带宽和密度,非常适用于AI训练、高性能计算和网络应用。
HBM,发挥重要作用
所谓HBM,也就是High Band Memory,也就是所谓的高带宽内存。如下图所示,在过去多年的发展中,HBM已经发展到了第五代的HBM3E。当中,每一代的最明显变化就是单个堆栈带宽的急剧增加。
以现在正在流行的HBM3为例,主要的DRAM制造商,如SK海力士、美光和三星已经宣布推出HBM3E设备,数据传输速率最高可达9.6Gbps。其单个设备的带宽更是超过了1.2TB/s。
之所以能获得如此高的带宽和速度,主要得益于其聪明的设计。
从结构上看,HBM的DRAM内存会通过有一个中间层的物理线,然后与那些处理器进行相应的连接。要实现这个目的,还需要以来图中所示的中介层,之后上面这些部分会共同与一个基板相连接,最后基板焊接在我们的PCB上面;从设计上看,HBM的DRAM堆栈会使用多层堆栈的架构、正是因为这样的一种方式可以提供非常高内存带宽,高容量和高能效。在其中,也会有非常、非常多的晶片堆栈,其中一个内存晶片会与处理器直接相连。
“在HBM3的标准当中,HBM内存有一个非常独特的点,就是它有非常多的线连接到SoC,在HBM3里面是1024根线。”Steven Woo博士表示。
Steven Woo博士指出,随着命令、地址、时钟和其他附加信号的加入,HBM3所需的信号路径数量增加到约1700条。上千条信号路径远远超出了标准PCB所能支持的范围。因此,采用硅中介层作为桥梁,将内存设备和处理器连接起来。类似于集成电路,硅中介层上可以蚀刻出间距非常小的信号路径,从而实现所需数量的信号线来满足HBM接口的要求。
正是由于这种精巧的结构设计和HBM DRAM的堆叠方式,HBM内存才能提供极高的内存带宽、优异的能效、极低的延迟,同时占用最小的面积。但是,因为大模型对带宽的需求还在持续增加中。为此,行业也不停息提升级HBM,这就催生了HBM 4。据透露,HBM4的带宽将达到1.6TB/s。值得一提的是,这只是单个堆栈的带宽,最终的实际带宽可能会更高。
“随着行业推出越来越快的HBM内存器件,Rambus作为内存控制器IP提供商,在这一过程中扮演着重要角色。我们的创新对于最终客户如何使用这些高性能的HBM内存至关重要。”Steven Woo博士重申。
Rambus打响关键一枪
毫无疑问,作为一家在内存系统领域拥有超过30年开发和研究经验的半导体企业,Rambus能够在HBM方面为人工智能行业提供广泛的支持。
Steven Woo博士直言,依托于多年来在HBM内存领域积累的丰富经验。Rambus在HBM市场的份额位居第一,并且已经成功完成了超过100次的HBM设计。在过去发展中,Rambus也成功交付了业界领先的HBM3E内存控制器以及业界最高数据传输速率的HBM2E内存控制器(速率达到每秒4 Gbps)。
“我们始终致力于帮助客户实现一次流片成功,避免重新设计。因此,客户可以放心选择Rambus,因为他们知道我们在构建成功系统方面拥有多年的经验,能够为他们提供所需的全方位支持。”Steven Woo博士表示。
面向正在走向现实的HBM 4,Rambus也在近日带来了业内首款HBM4控制器IP,旨在加速下一代AI工作负载。
据Steven Woo博士介绍,Rambus新发的HBM4内存解决方案是在HBM3性能的基础上进一步提升:一方面,HBM4的控制器IP提供了32个独立通道的接口,总数据宽度可达2048位。而基于这一数据宽度,当数据速率为6.4Gbps时,HBM4的总内存吞吐量将比HBM3高出两倍以上,达到1.64TB/s;
另一方面,与HBM3E控制器一样,Rambus HBM4内存控制器IP也是一个模块化、高度可配置的解决方案。
“根据客户在应用场景中的独特需求,我们提供定制化服务,涵盖尺寸、性能和功能等方面。关键的可选功能包括ECC、RMW和错误清理等。此外,为了确保客户能够根据需要选择各种第三方PHY并应用于系统中,我们与领先的PHY供应商开展了合作,确保客户在开发过程中能够一次流片成功。 ”Steven Woo博士说。他同时还透露,Rambus的客户将在今年晚些时候采用其HBM 4控制器,并在 2025 年将其集成到他们的芯片设计中,这些芯片设计预计最终将在 2026 年上市。
当然,除了HBM 控制器以外,Rambus在很多产品方面能够为AI及其他诸多应用支持。
正如Rambus大中华区总经理苏雷先生所说,Rambus是一家业界领先的半导体IP和芯片提供商。凭借着34年的技术领先地位,Rambus实现了让数据传输更快、更安全的目标。“Rambus专注于数据中心,因为数据中心对最高性能和安全性的需求最大,我们75%的收入都来自于数据中心。”苏雷先生强调。从他的介绍我们得知,纵观半导体价值链,Rambus在三个层面发挥着作用:分别是半导体IP、基础技术和芯片。
苏雷表示,Rambus的半导体IP产品主要由接口IP和安全IP两大类产品组成。其中,接口IP实现了处理器、加速器和内存之间高性能互联;安全IP保护芯片上静止的数据,处理器和内存之间使用中的数据,以及数据中心中各设备传输中的数据。
在基础技术方面,据介绍,Rambus在过去34年以来开发了约2800项专利以及专利申请。Rambus的芯片产品则是最大、增长最快的产品系列,为DDR4和DDR5内存模块提供了除DRAM颗粒之外所有的内存模块所需的芯片组,提供模块解决方案,以及一站式服务。
展望未来,Rambus也会持续更新,为客户提供极具竞争力的方案。具体到人工智能方面,如Steven Woo博士所说,为了保持未来的扩展步伐,Rambus认为未来的人工智能将继续需要在性能、功效和内存容量方面取得重大改进,这将需要许多不同的公司共同努力。例如需要内存制造商和像 Rambus 这样的公司将改进内存系统,但处理器厂商也必须通过压缩数据和使用新的数字格式等方式来改进处理。软件开发人员将来也必须与硬件开发人员更多地合作,这种软件和硬件之间的协同设计也将有助于确保软件充分利用可用的硬件。
“Rambus 始终着眼未来,我们在高性能内存架构领域拥有 30 年的经验,一直致力于扩展内存的性能和容量。”Steven Woo博士强调。
责任编辑:Ace
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 东方晶源YieldBook 3.0 “BUFF叠满” DMS+YMS+MMS三大系统赋能集成电路良率管理
- 2 NVIDIA重磅出击:三台计算机助力人形机器人飞跃
- 3 奕行智能(EVAS Intelligence)完成数亿元A轮融资,加速推出RISC-V计算芯片产品,共同助力新时代到来
- 4 智能驾驶拐点将至,地平线:向上捅破天,向下扎深根
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号