AI芯片的第一次同场竞技背后
2019-11-12
16:01:50
来源: 互联网
点击
关于AI/ML芯片的Benchmark,我写过好几篇文章来讨论(参考如何评测AI系统?),因为它对产业意义重大却容易被忽视。不夸张的说,Benchmark本身可能指引AI芯片的技术方向,而其结果也可以反映产业发展的状况。
 source: mlperf.org
source: mlperf.org
 source: mlperf.org
source: mlperf.org

第一类场景是“Single stream”,这类场景假设只有一个需要进行处理的数据流,其关注的指标是处理的延时(Latency),典型应用是手机对摄像头数据的处理。第二类场景“Multiple stream”,同时有多个数据流需要处理,典型情况是自动驾驶需要同时处理来自多个sensor的数据。这类场景关注的指标是,在满足一定处理延时的要求下,能同时处理的数据流的个数。第三种场景“Server”比较复杂,需要处理随机到达(泊松分布)的Inference请求,这种情况关注的指标是,在满足一定处理延时的要求下,可以实现的QPS(Queries Per Second)。第四种场景“Offline”,比较简单,就是所有数据一下到达,进行离线处理,看最大可以支持的Throughput。


在精度等级方面,参与的厂商在量化上可以有一定的灵活性。但在Closed Division中,他们的方案必须达到数学上的等效,并且不允许对测试模型进行retrain。在Open division里则没有对retrain的限制。从这次的结果来看,在Open division里,Habana(超低Latency)和NVIDIA(4bit量化使ResNet-50 offline throughput有大幅提高,但需要retrain)给出了优化的结果。其它结果注意是第三方软件厂商提交的移动平台的测试结果,不具太大的参考价值。所以我后面还是主要分析Closed Division的数据。
 source:mlperf.org
source:mlperf.org

从被测系统的特征来看,这次结果也基本覆盖了大部分硬件类型(没有覆盖类脑和模拟计算类型)。

但是,考虑到现在AI芯片领域参与者的数量(可参考下图:AI Chip Landscape),此次提交结果的厂商还是很有限的。
 source:https://basicmi.github.io/AI-Chip/
source:https://basicmi.github.io/AI-Chip/

MLPerf刚刚发布了第一次Inference的评测结果,可以看作是AI芯片产业逐渐走向成熟的一个标志。如果说之前的Training评测还只是几个大厂的“游戏”,这次的测试结果则是各类厂商的第一次同场竞技[1],不管是数据本身,还是数据背后,都有很多有趣的问题值得讨论。
技术背景
如我之前多次介绍过的,Training系统的Benchmark设计相对比较简单,基本就是看在待测系统上训练一个模型达到一定的准确度所需要的时间。而Inference系统的Benchmark设计和实现的挑战多得多,MLPerf的成员对此进行了相当长时间的探讨,而这次公布测试结果的同时,他们还发表了一篇Paper来讨论相关的问题[2]。对于设计理念和细节,我建议读者自己去看Paper,这里我主要想介绍一下Inference Benchmark 0.5中场景的概念,以便大家可以更好的理解这次发布的数据。
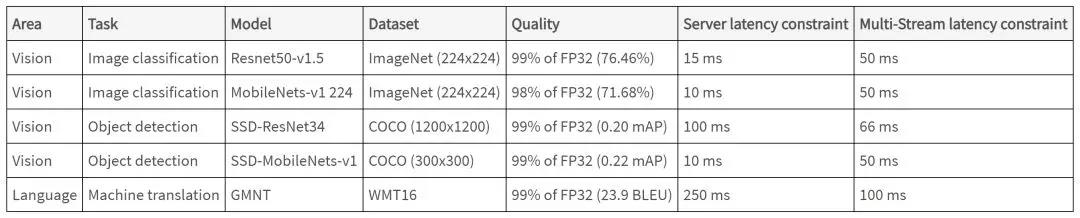
我们知道,目前AI Inference的应用类型和场景多种多样,这给Benchmark设计带来了很大挑战。这个版本的Benchmark,除了选取5种模型作为基本的测试用例之外,还专门设计了4个不同的场景。
source: mlperf.org模型就不多说了,我们主要看一下4个场景(Scenario),下表是对场景的正式定义。
source: mlperf.org下图对几个场景以及不同场景的测试指标的描述更为直观。
第一类场景是“Single stream”,这类场景假设只有一个需要进行处理的数据流,其关注的指标是处理的延时(Latency),典型应用是手机对摄像头数据的处理。第二类场景“Multiple stream”,同时有多个数据流需要处理,典型情况是自动驾驶需要同时处理来自多个sensor的数据。这类场景关注的指标是,在满足一定处理延时的要求下,能同时处理的数据流的个数。第三种场景“Server”比较复杂,需要处理随机到达(泊松分布)的Inference请求,这种情况关注的指标是,在满足一定处理延时的要求下,可以实现的QPS(Queries Per Second)。第四种场景“Offline”,比较简单,就是所有数据一下到达,进行离线处理,看最大可以支持的Throughput。
值得注意的是,这四种场景隐含的决定了做Inference时的Batch Size的大小,而Batch Size对于Throughput和Latency都有很大影响。显然,“Single stream”只能用很小的Batch Size(一般就是1)。而对于“Multiple stream”,Batch Size只要小于stream的数量就可以。对于“Offline”场景,Batch Size是没有限制的。“Server”场景的情况复杂一些,由于到达的处理请求是随机的,你可以收集一定的请求后组成Batch进行处理,当然前提是要满足场景下的latency要求。如果一下来了很多请求,则可比较容易组成较大的Batch。
数据分析
在了解了技术背景之后,我们来一起看看这次发布的结果[1]。测试首先分为Closed和Open两大类(divisions),其中Closed Division有比较严格的限制,希望能对不同的待测系统(硬件平台或软件框架)做到“Apple-to-Apple”的比较;而Opened Division则允许做一些特定的优化以获得更好的效果。下面两页slides可以说明这两个类别的限制。
在精度等级方面,参与的厂商在量化上可以有一定的灵活性。但在Closed Division中,他们的方案必须达到数学上的等效,并且不允许对测试模型进行retrain。在Open division里则没有对retrain的限制。从这次的结果来看,在Open division里,Habana(超低Latency)和NVIDIA(4bit量化使ResNet-50 offline throughput有大幅提高,但需要retrain)给出了优化的结果。其它结果注意是第三方软件厂商提交的移动平台的测试结果,不具太大的参考价值。所以我后面还是主要分析Closed Division的数据。
此外,数据还根据待测系统的可获得性(availability)分成几个小类:Available,Preview systems,Research systems。简单来说就,Available的系统就是公开可以使用(购买)的,Preview系统虽然目前还不行但到下一次提交结果前是必须公开可用的,而Research systems则没有这些要求。
表格的具体内容除了待测系统的一些基本信息,比如系统里CPU和加速器的数量,软件框架之外,最重要的当然是Benchmark Results部分。如前所述,目前Benchmark使用5种模型和4个场景。对每一个系统来说,最多可以提交20个数据,但实际上并没有任何一个系统提交所有结果。一方面原因是,不同的AI芯片设计都是有针对性的,在现实中并不需要支持所有组合,比如Single Stream的场景比较适合移动平台,我们看到的结果主要是一些手机和移动设备的SoC平台(高通,华为,Rockchip)。而提交结果最多的NVIDIA,也只是提交了Jetson AGX Xavier (Xavier)平台的Stream场景结果。另外一个原因是,大量模型和场景,要都跑出能拿得出手的结果(估计拿不出手的就先不提交了)也是很大的工作量,对软件工具链的灵活性和成熟度也是很大的考验。所以如意料之中,和training的结果类似,还是NVIDIA和Intel提交的结果覆盖情况最多。
既然Benchmark的结果有PK的意义,我们就看看竞争最激烈的战场。从模型来看,结果最多的是ResNet-50,这个也不意外。我从原始数据中摘出了ResNet-50的部分,为了让大家更好的对比结果,去掉了一些不太重要的数据。
source:mlperf.org从场景来看,Offline场景提交的结果最多,这个也不奇怪,毕竟Offline场景是最好实现的场景(也应该是大部分AI专用芯片测试时首先实现的场景)。在这个模型/场景组合中,这次最吸引眼球的当然是阿里的含光芯片,实现了单芯片69,306.6(samples/sec)这个惊人的数据。我在之前的文章“数据中心AI Inference芯片今年能达到什么样的性能?”中估计,今年能实现单芯片25,000 image/sec@INT8的性能,看来是严重低估了(还是贫穷限制了我的想象力啊)。除此之外,含光在ResNet-50其它几个场景的数据也是遥遥领先,非常强悍。
另一个值得关注的结果是Intel的NNP-I,虽然两颗芯片实现10567.2的性能不算亮眼,但重要的是总算看到东西了!
Google这次提供了多种TPU配置(1-32个Cloud TPU v3-8)的结果,并且由“32x Cloud TPU v3-8”系统得到了全场最高的1,038,510。感觉Google想show的是在Offline场景里,throughput可以随着芯片数量线性增加。不过在这种场景下,没有latency的限制,尽可以使用大的Batch做数据并行,实现这种线性增加也不算很难的事情,这一点在其他家的数据里也可以看出来。
NVDIA这次没有提交单个T4的数据,而是8颗(44,977.8)和20颗T4(113,592)的数据,不过阿里云和Dell分别提交了单颗(5,540.1)和四颗芯片(22,438)的数据。而在Open Division里,浪潮提交了一个V100的结果。另外,NVDIA还提交了TitanRTX和Jetson AGX Xavier的数据。
在Available类别里提交结果的还有Habana(Goya),腾讯(Intel CPU),dividiti(一家做软件平台优化的初创公司,提交的结果主要基于移动SoC芯片);在Preview类别提交结果的还有Centaur Technology(一家做CPU的公司)和Hailo(一家以色列的做边缘AI芯片的初创公司),具体的结果就不再赘述。
还有一点需要指出的是,在发布结果之前,大家提交的数据是需要通过一个评审机制进行审核的,这些原始数据都在Github上。大家可以通过表格里的details和code的链接去看更多细节信息和测试用的代码。
数据背后
首先,这次的ML Benchmark是0.5版本,也意味着它并非一个真正成熟稳定的版本。这个版本一个重要的问题就是只有性能指标(Throughput,Latency)但没有效率指标。对于一个芯片产品来说,最终被市场接受,除了要看它能够达到多高的性能,还必须看达到这样的性能所花的代价,比如需要消耗多少能量,投入多少成本等等。在大多数情况下,samples/sec/W,或者samples/sec/$,要比单纯的samples/sec重要。不考虑效率,只看目前的数据,是很难对不同的系统做出公平的对比的。当然,实现效率的测试,比如引入power test会给Benchmark带来更多复杂性,但这也是MLPerf下一步必须解决的问题。另外,MLPerf目前使用的模型也需要根据AI算法的进展和实际应用的需求持续更新,而这方面的变动对于Benchmark的设计者和使用者也都意味着不小的工作量。
第二,我们可以从几个官方的总结看看这次参与者的情况。从参与者的类型来说,这次结果基本覆盖了这个领域的各类公司和组织。
从被测系统的特征来看,这次结果也基本覆盖了大部分硬件类型(没有覆盖类脑和模拟计算类型)。
但是,考虑到现在AI芯片领域参与者的数量(可参考下图:AI Chip Landscape),此次提交结果的厂商还是很有限的。
source:https://basicmi.github.io/AI-Chip/目前的MLPerf还只是发展初期,在成为标准之前,多数提交结果的厂商主要还是希望能够达到宣传的目的。所以,如果不能展示一些亮眼的数据(不管是硬件或者软件确实做的不好,还是应用场景和优化目标不同),厂商自然是不会主动参与的。另外,对于很多系统公司自研的芯片,宣传的需求不大,即使会用MLPerf做内部测试,但不一定有意愿提交结果。
还有一大类AI加速是嵌入在移动平台SoC中的,比如手机芯片。但这一类AI硬件的测试,这次只有一两家第三方公司提交了结果。而对手机芯片AI能力的测试,目前大家用的比较多的是ETH Zurich的AI-Benchmark(类似手机跑分软件,也没有严格的规则)。MLPerf据说未来也会提供类似的手机APP的测试模式,但能否取代AI-Benchmark的地位就很难说了。
对于一个权威的Benchmark来说,除了要有好的设计,业界的认可和参与度也是至关重要的。Benchmark设计的公平合理,大家就更愿意参与;参与的厂商越多,Benchmark越容易改进,形成权威。反之则会越来越差,最终被淘汰。从目前这个领域的情况来看,MLPerf起点最高,也得到越来越多的厂商的认可,但最终要成为行业标准,还有很长的路要走。
最后说一点感受吧。从这次结果中的Available部分可以看出,真正能用的芯片还是非常有限的,可以说惊喜不多。虽然这次MLPerf发布的结果并不能覆盖所有AI芯片公司,但现实情况还是只有NVIDIA能够真正能够提供从training到inference,从cloud到edge全覆盖的产品。NVIDIA刚刚又发布了Jetson Xavier NX,号称世界最小的超算平台。应该说,NVIDIA的领先地位并没有受到多大挑战。
source: NVDIA
Google从开始做TPU,到现在已经是AI芯片最重要的玩家了,有自己完整的生态,相信未来会有持续的发展。其它科技巨头可能会参考Google的模式,不过发展路径和时间表会各不相同。Intel的表现还是很稳健的,各种专用AI芯片看起来热闹,但其实inference用的最多的还是Intel的CPU。另一方面,除了移动平台,不管你用什么加速器,Intel的CPU也还是必不可少的。除了这几个巨头(也包括没有参与的),大部分初创公司或新玩家还是在为“Available”甚至“Preview”而奋斗,希望在MLPerf下次发布测试结果的时候,我们能有更多的惊喜。
祝MLPerf好运!祝各AI芯片公司好运!
Reference:
[1] "MLPerf Inference v0.5 Results", https://mlperf.org/inference-results/
[2] Vijay Janapa Reddi, et al. " MLPERF INFERENCE BENCHMARK", https://arxiv.org/abs/1911.02549
责任编辑:sophie
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 东方晶源YieldBook 3.0 “BUFF叠满” DMS+YMS+MMS三大系统赋能集成电路良率管理
- 2 首次!芯联集成2024年度毛利率转正
- 3 蓝牙技术联盟宣布2025蓝牙亚洲大会重磅回归
- 4 智能驾驶拐点将至,地平线:向上捅破天,向下扎深根
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号