英特尔的秘密任务
2019-08-07
14:42:56
来源: 互联网
点击
现代微处理器通常能够通过分层缓存来隐藏计算与内存之间的大部分差距。这是因为许多负载表现出相对可预测的一般内存模式,可以通过空间局部性和时间局部性加以利用。有些负载还尴尬地并行。例如,人工智能负载往往表现出这种行为。只要你持续为机器提供数据,更多计算就相当于更高性能。人工智能负载往往具有非常可预测的内存模式以及较高的数据重新利用能力,这有助于实现上述所有目标。
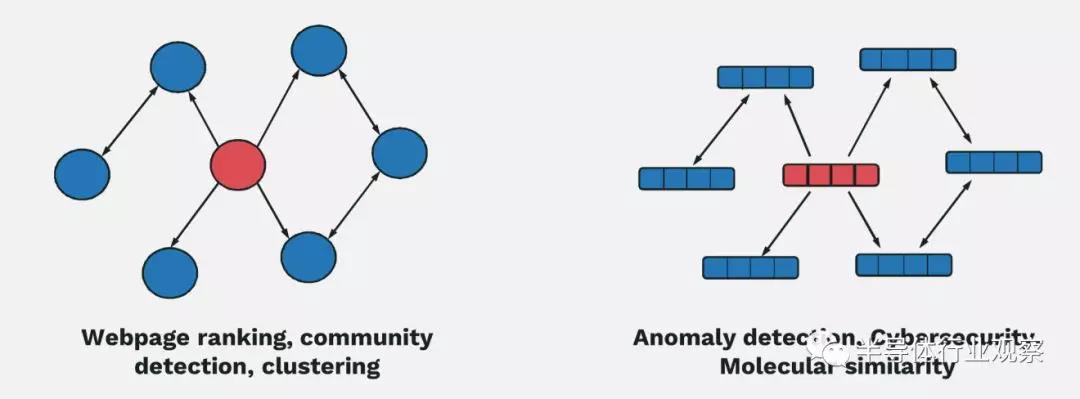
不幸的是,并非所有算法都具有这些理想的特性。图就是这样一个例子。企业广泛地使用图来处理大数据。这些数据结构往往有上万亿个边缘,并采用特殊的图算法对数据进行操作。图算法采用非常随机的内存访问模式,导致负载受到内存延迟的高度限制,迫使计算元素在很多时候陷入停滞。它本质上是一个非常大的指针追逐问题,表现出与运行在GPU和CPU上的大多数负载相矛盾的行为。

更糟的是,图算法往往具有非常差的次线性缩放特性。你根本无法通过投入更多处理器来解决这个问题。由于数据的稀疏性和不规则性,下一个数据访问通常是在一个完全不同的节点上,传输数据最终会导致整个系统出现瓶颈。
美国国防部分层识别验证及利用计划(DARPA HIVE)
分层识别验证及利用(HIVE)计划是美国国防部正在开展的一项计划,目标是解决这些缺点。HIVE采用软硬件双管齐下的方式。针对该计划的硬件部分,正在开发用于图处理的下一代ASIC。针对软件部分,正在开发一个新的全栈图框架。美国国防部希望通过专门的图处理器和优化的软件栈,实现比当前同类最佳的GPU高1000倍的性能效率。
在上个月底举行的DARPA ERI峰会上,Peter Wang介绍了该项目的最新进展。Wang是Anaconda公司的联合创始人兼首席技术官。他也是HIVE软件架构的首席研究员。

介绍英特尔PUMA团队
英特尔负责HIVE的硬件架构部分,他们正在开发一个新的架构来解决这些问题。在英特尔的数据中心事业部内部有一个名为PUMA的秘密团队。他们负责图分析(GA)处理器的开发。这是他们正在秘密开发的一个完整产品,英特尔打算最终将其商业化。
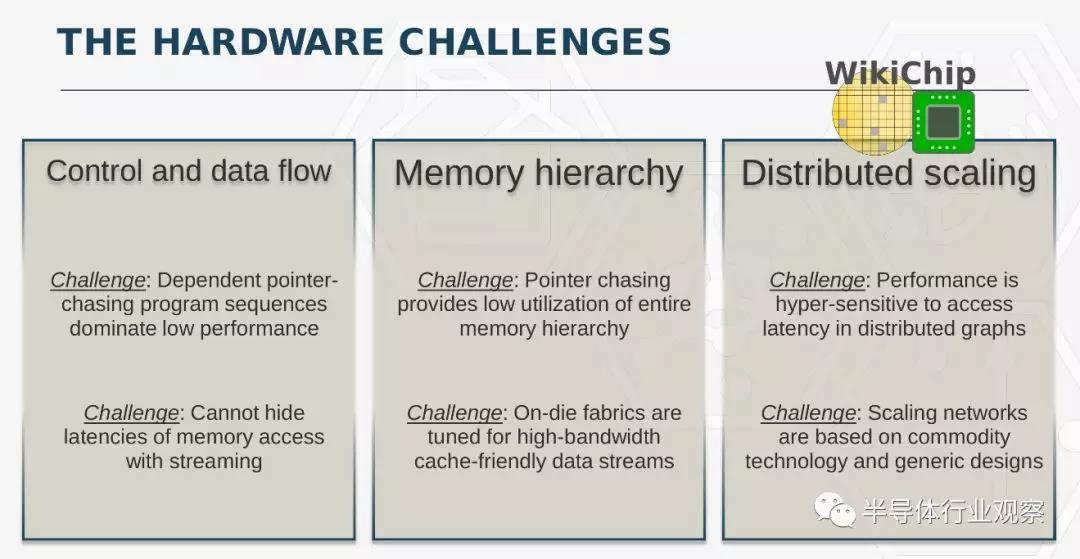
新的图处理器基于一种新开发的架构,被称为可编程统一内存架构或PUMA。这是一种新的架构,用于整个全局统一内存空间的小型不规则内存访问。在这种架构下,芯片放弃了现代CPU和GPU所使用的许多基本假设——它并不假设自己拥有附近所有内存,它并不假设内存访问会在不久的将来重复执行,它也不假设对特定地址的内存访问意味着附近的内存地址也将被访问。Wong说:“通过抛弃这些基本假设,你可以围绕对全局统一数据的小访问而构建一个完全不同的硬件架构。然后,在每个阶段,每当有一个有线互联或者任何把一个计算单元连接到其它一些数据单元或其它计算单元的东西,每一个点都针对延迟进了优化。” PUMA从根本上改变了与内存访问相关的行为,使内存访问更小、更有效,并使访问这些内存的延迟更长,但在整个系统中实现扁平化。
PUMA实现机箱级完全集成,可以跨处理元件和内存进行良好的通信。它旨在扩展到大型系统,在多个机架和多个集群上使用。

Wang根据英特尔的内部模拟结果给出了一些初步性能数据。他说:“节点缩放确实是一个关键问题。当我们讨论上万亿个边缘的时候,我们知道这些数字会变得更大。”为此,Wang报告了超过80%的缩放效率。他补充道:“这实际上让我们能够并行化解决图问题的方法。”

软件基础设施
HIVE的第二阶段是构建软件基础设施。新软件不仅必须与新硬件兼容,而且必须与现有CPU和GPU兼容。此外,新软件必须支持数据科学届使用的大量现有软件。现有的大量软件都是为了以某种方式解决特定的图问题而开发的。该计划的部分目标是能够将现有的软件和库连接到HIVE软件框架中,以便使其更易于投入使用。
当前的软件包括通过API公开的算法、数据的内部图表示以及硬件后端(GPU、CPU、FPGA或ASIC)。Wang解释说,在当前平台下,必须做出重大取舍,无论是针对某种类型的硬件进行优化还是针对某些算法进行优化。Wang说: “如果你专门从事图表示,那么你就会与数据科学生态系统脱节,因为你被切断了与一些重要库的联系。”

作为HIVE第二阶段一部分,他们正在开发模块化架构框架。现有软件正在重新纳入它们的组成部分,以便可以根据该软件最佳功能将其插入到框架中。该结构包括Workflow Scheduler和Dispatch Engine,用于把User API负载任务路由到后端。他们利用DASK任务调度程序来执行此操作。这也是他们进行后端切换和调度的方式。顺便说一句,值得注意的是,虽然他们正在与英特尔密切合作,共同开发这个框架,以便能够通过PUMA架构实现其性能目标,但是软件框架并不是专门为PUMA设计的。事实上,它们完全针对广泛的硬件,以便数据科学家立即能够跨越CPU、GPU和FPGA,充分利用相同的软件基础设施。并最终使用相同的基础架构,利用PUMA图处理器来加速相同的负载。

值得一提的是,如果有必要,在后端,框架可包含一组能够转换不同格式数据的转换器。

这种设计有两大好处——集成新硬件意味着设计了一个新的硬件后端,如果数据模型与现有模型不同,则添加对数据模型的支持,并添加一个可以从现有数据模型转换到新数据模型的转换器。同样,集成一个新的User API只需要在其中一个硬件上添加一个接口并至少采用一种算法。

最终,HIVE的总体目标就是统一和简化“让图软件与硬件进行优化通信的”流程,只需让硬件厂商提供其硬件并为其集成一个良好的后端,同时让数据科学家能够通过自己的API和算法来充分利用该硬件。

Wang透露,从明年开始,用户有望看到开源的初始源代码。

责任编辑:sophie
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 一文看懂封装基板
- 2 关于半导体工艺节点演变,看这一篇就够了
- 3 半导体未来三大支柱:先进封装、晶体管和互连
- 4 村田开发超小尺寸、超低功耗的Type 2GQ GNSS模块 以匠心品质助力实现万物互联时代
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号