
英伟达:AI芯片还可以这样做
过去一年,我们看到了来自工业界的新研究芯片的洪流。基于芯片的新设计和新的神经处理器体系结构比比皆是。在早前举办的2019年超大规模集成电路(VLSI)研讨会上,我们看到了一个由英伟达制作的一个有趣的研究芯片,在这里我们来披露一下。

研究芯片2018 - RC 18
Nvidia的研究芯片并没有引人注目的代号。相反,它简称为2018研究芯片或“RC 18”。尽管该芯片是在今年早些时候在2019年GPU技术大会(GTC)上首次谈到,但直到本月早些时候在日本京都举行的2019年VLSI研讨会上才公布了技术细节。Nvidia的高级研究科学家Brian Zimmer对该芯片做了详细介绍。
顺便说一下,我们想指出的是,像英特尔和英伟达这样的半导体公司,出于探索性的原因,通常每年都会设计几个这样的研究芯片。以帮助他们了解哪些可以工作,哪些在实践中不能工作,为什么这样做,以及涉及到哪些挑战。从这项研究中获得的知识将应用到未来的产品中。虽然像英特尔这样的公司有时会在各种IEEE会议上展示多达几十个研究芯片,但看到英伟达谈论其内部研究芯片的情况相当罕见。
该研究芯片试图展示几种不同的技术:
-
面向对象的逻辑合成
-
细粒度全局异步局部同步(GALS)SoC设计
-
裸片到裸片以地为参考的单端串行链路(GRS)
-
可伸缩的( scalable)神经处理器加速器架构
请注意,并非所有内容都经过专门讨论。具体而言,未讨论面向对象的逻辑综合方面的开发。
用于推理的神经处理器的一个相对独特的方面是根据目标市场必须涵盖的广泛应用,性能和功率范围。例如,由于允许的功率预算通常是几百瓦,数据中心中的推断可以轻松地以每秒尽可能多的操作完成。虽然工程师希望在他们的自动驾驶汽车中拥有这样的性能,但动力是一个难以克服的障碍。因此,通常选择一个更平衡的性能power point。同样的,手机的电量预算只有几瓦,而在天平的末端是一些边缘设备,它们只需要几毫瓦的电量就能延长电池寿命。
很可能,许多神经处理器的另一个独特之处是,假设它们不受内存限制,那么随着计算能力的提高,它们的可扩展性(scala)会更好。扩展能力很适合基于芯片的方法。本研究的主题是能够使用多个单一裸片来构建多个具有不同功率和性能要求的系统。

Test Chip Overview (VLSI 2019, Nvidia)测试芯片概述(VLSI 2019,Nvidia)
对于这个研究芯片,英伟达决定从一个裸片扩展到36个裸片系统。设计这样的体系结构有其自身的挑战。必须证明,这样的系统能够从毫瓦扩展到100瓦,并在沿途的每个点上提供成比例的性能缩放。这必须做到从一个裸片直到36个裸片系统都没有效率损失。为了使更大的系统能够减少延迟,还必须演示强大的可缩放性,而延迟对于诸如汽车应用程序之类的领域是至关重要的。
裸片
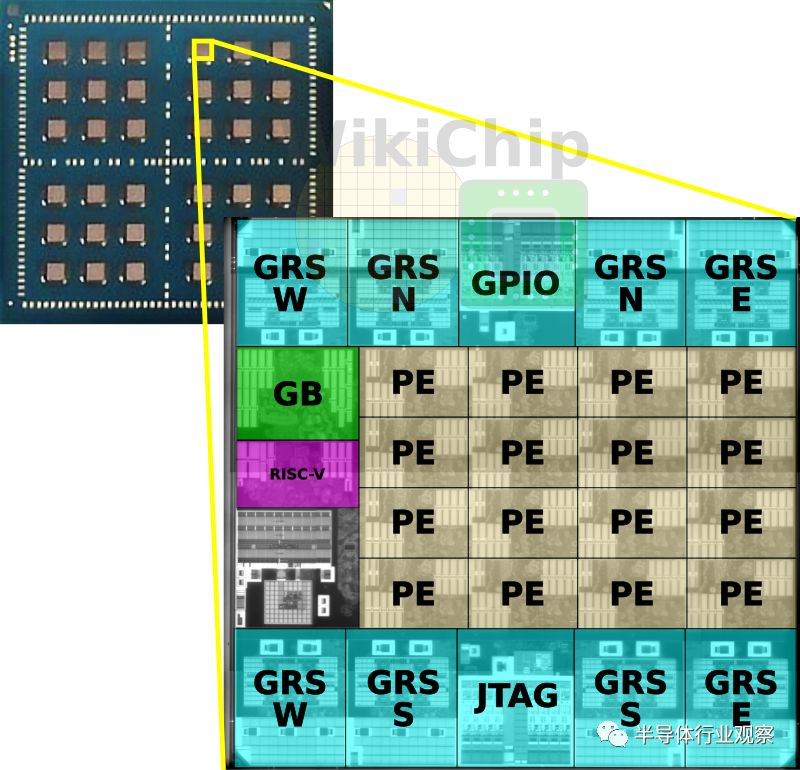
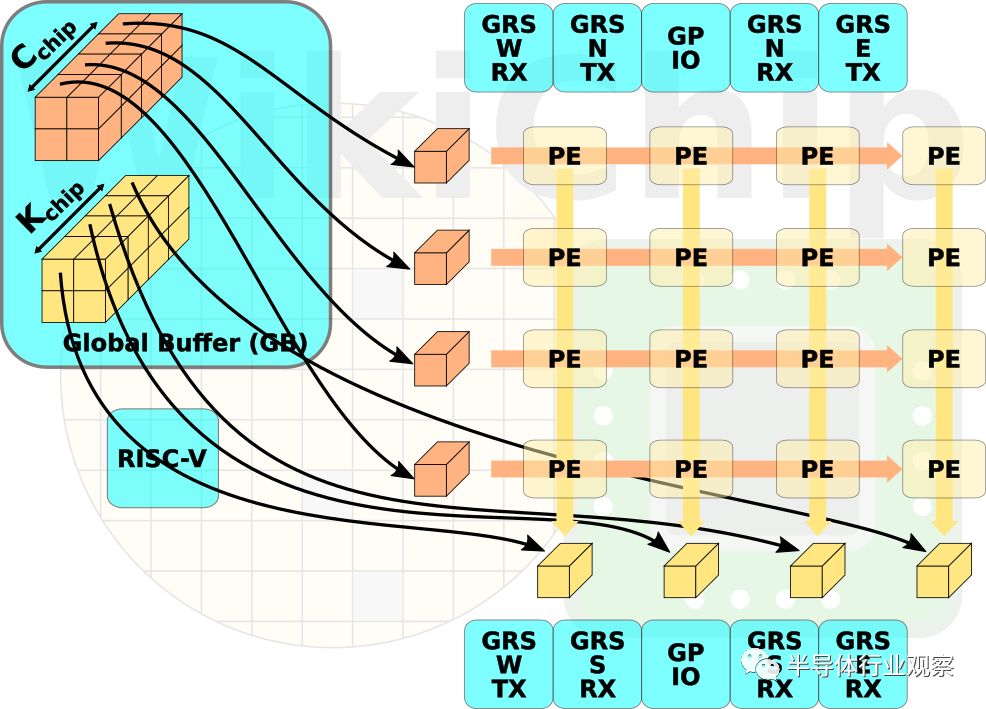
从单裸片到36芯片系统,所有裸片都是相同的。在台积电16纳米节点上制造,每个裸片占据正好6平方毫米的硅,工业标准尺寸适中,但对于研究芯片来说还不够大(这将在后面进一步讨论)。每个芯片上有一个由16个处理元件组成的网络,一个存储中间激活的全局缓冲区,NoC,NoP和一个管理RISC-V内核。
RISC-V Core RISC-V 核心
该芯片采用基于开源Rocket可配置内核的单个RISC-V内核。这是一个有序的5级流水线核心,可与Cortex-A5相媲美,具有更好的面积,性能和功效。

Scaling 缩放
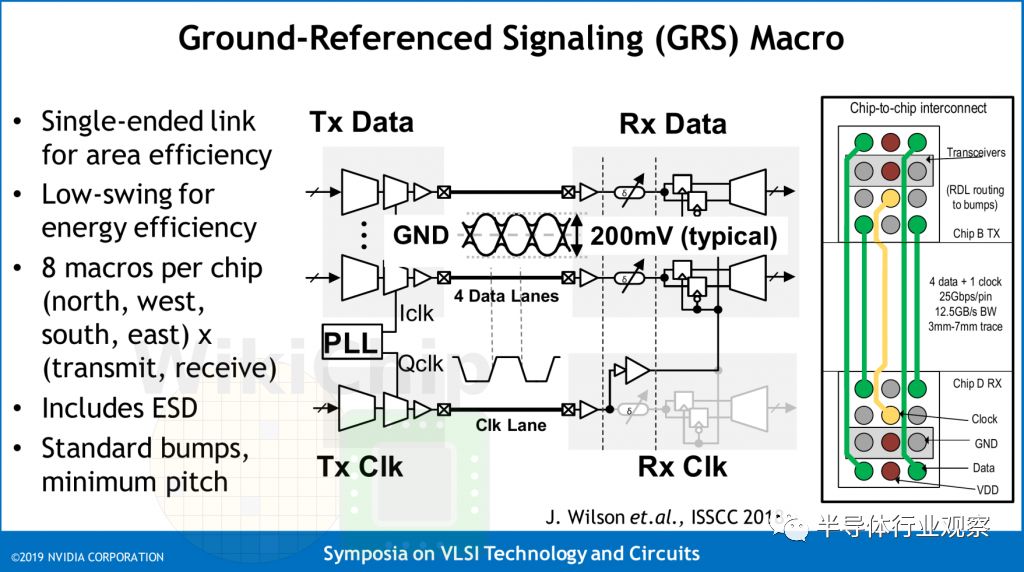
为了将架构缩放成许多小芯片,Nvidia实现了网络封装。每个芯片上有八个接地参考信令(GRS)宏。每个罗盘方向有一对用于发送和接收的宏。这些宏可在北,南,东和西方向上发送或接收100 Gbps。

在这项研究中,Nvidia在单个有机基板上组装了多达36个连接在一起的小芯片。前六个芯片具有连接到外部世界的通用I / O. 包装本身为47.5毫米×47.5毫米,相对于它所携带的模具数量而言相对较小。值得注意的是,Nvidia选择了标准的有机基板,而不是CoWoS等替代封装技术,由于经济原因,它具有更好的I / O密度和凸点间距。对于许多市场来说,硅插入器太昂贵了。
die配置为具有大导线的网状拓扑,其不能在不损害功率输送的情况下在die上路由。每个宏都有一个时钟脉冲和四个数据脉冲。请记住,这是在标准有机基板上使用标准的150μm凸点间距。接地参考信令(GRS)是单端链路,旨在利用传统的廉价有机封装和电路印刷板。这些是使用单端信令的短距离(约80mm范围)链路。
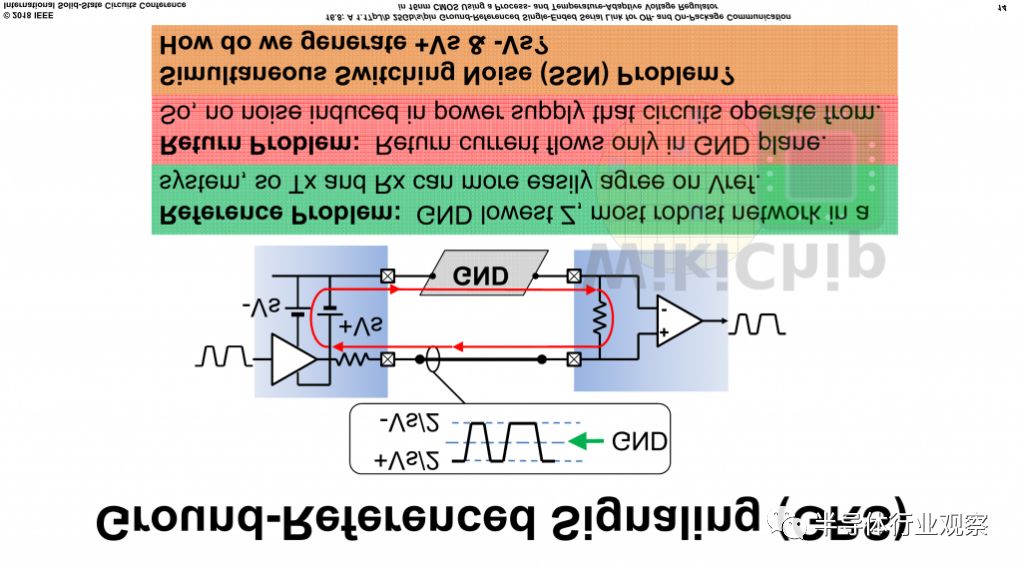
历史上,由于其固有的抗噪声性和较低的功率特性,差分信令已经优选用于这样的高速信令信道。为了克服其中一些问题,尤其是与同步开关噪声和信号完整性有关的问题,Nvidia GRS链路使用接地作为电压参考,因为其坚固性和最低阻抗。返回电流仅在地面上流动,信号在相对于地的两个+ Vs和-Vs电压源之间对称驱动(换句话说,信号在地下或地上发送)。这是低摆幅信号,因此您可以看到大约200 mV的峰峰值。时钟也被转发。
Loading Dat 加载数据
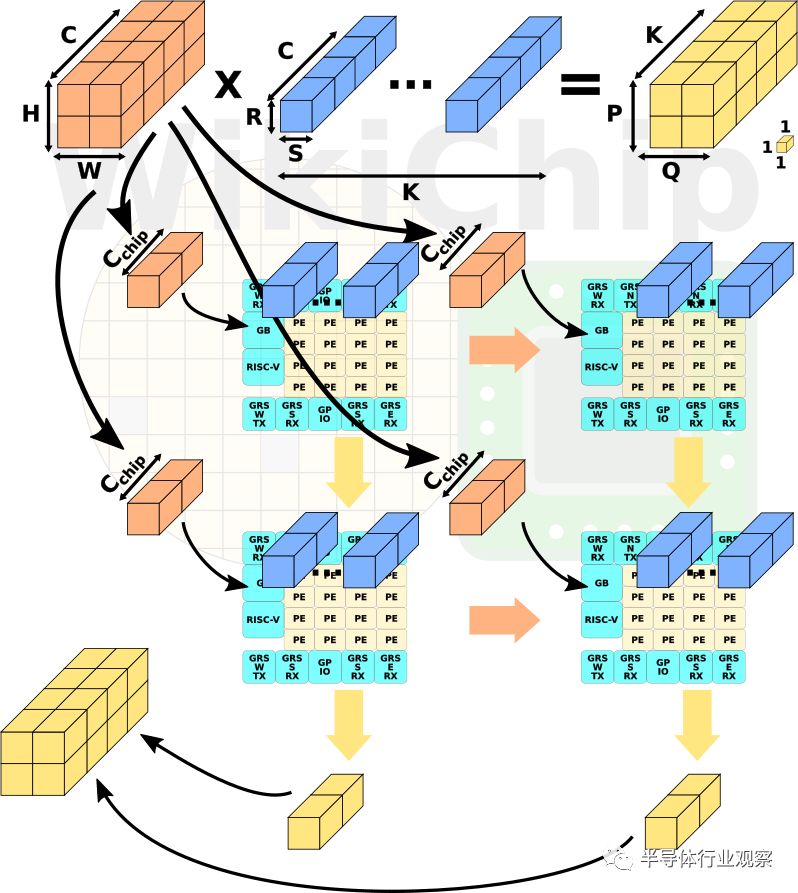
芯片一次在一层上操作,每层可能具有不同的输入和输出尺寸以及预定的权重。输入的特征在于具有C通道的H乘以W的大小。因此,输入乘以具有C通道的R乘以S的权重内核大小。因此,输出激活大小是P乘以K输出通道的Q倍。
然后,芯片将R x S x C输入元件乘以R x S x C权重,最后将所有值相加,以创建1x1x1输出。重复P×Q×K次。输入在所有芯片之间是均匀分布的。在每个芯片内,然后将输入分配到NoC上的所有处理元件。顶部芯片将其输出传送到底部芯片,用于累积所有C输入通道。
Loading Data (PEs) 加载数据(PEs)
实际的tiling 是软件可编程的,唯一固定的约束是处理元件中只有八个输入和输出通道(详见下一节)。数据到达每个小芯片的全局缓冲区。在单个die内,权重和输入的分布遵循与包级分布相同的方案。输入在处理元件上传播,而交叉PE输出累积向下级联。
Processing Element处理元件
处理元件是芯片的主力执行单元。除了操作的开始和结束之外,PE在没有任何全局同步逻辑的情况下自主地操作。复位后操作开始。此时,权重进入并密集存储在本地32 KiB权重缓冲区中。同样,输入激活被馈送到本地8 KiB激活缓冲器。当所有数据都可用时,可以开始MAC操作。有八个通道,每个通道对应一个输出通道。在每个通道中读取不同的权重,在读取一次之后在所有通道上共享输入。
每个通道是一个 8-wide矢量MAC元件,同时在8个输入通道上运行。通过8个通道,您可以查看每个周期64个MAC的峰值计算。PE从重量缓冲器读取每个PxQ(卷积结果的宽度和高度)循环,同时每个循环从输入缓冲器读取。

请记住,工作负载在所有PE之间分开。由于每个PE都在处理通道的子集,因此最终值必须通过PE运出,以便汇总输出。最后,计算输出激活。
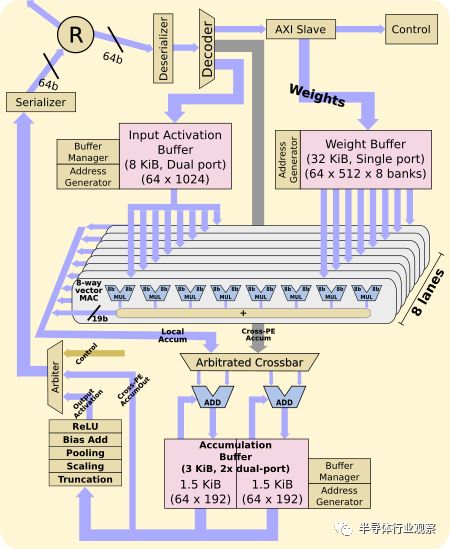
每个PE每个周期能够进行64位8位乘法累加。每个芯片中有16个PE,每个周期总共执行1024个MAC。
性能
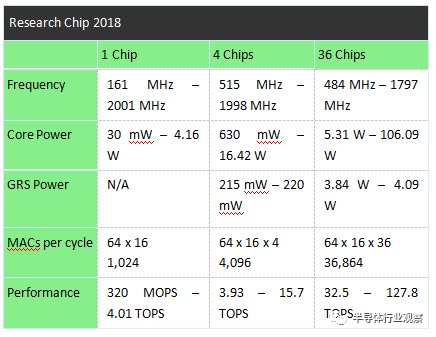
一些相当过时的网络被用于测试。在AlexNet上,他们报告了32,369个周期的测量延迟,相当于75%的利用率。ResNet-50具有较强的结垢能力。它还表明,相当一部分时间花在多芯片RISC-V同步操作。总而言之,一个芯片可以在161兆赫到2兆赫之间工作,消耗30兆瓦到4w,性能从320 MOPS到4陀螺不等。对于最大的配置36个芯片,多达128个顶部可以实现1.8 GHz的运行和消耗约110 W。
更深入的分析
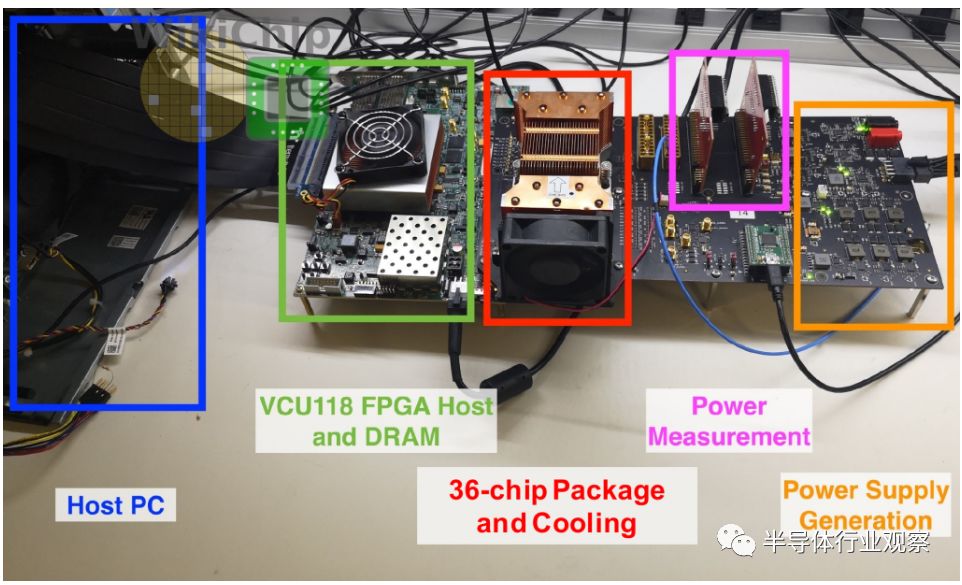
应该注意的第一件事是缺少内存控制器的整个方面。目前,采用具有低带宽存储器系统的FPGA。模型逐层操作。目前的设计假设一切都适合片上。随着FPGA工作的加重,看看如何实现分布式内存控制器on-die以可伸缩的(scalable)方式完全支持芯片上的这一功能,将是一件有趣的事情。这还必须考虑原始的伸缩(scaling要求。通过从毫瓦到功耗预算的100瓦特,可以预期内存预算和功能的类似缩放。
裸片本身很小。芯片到芯片的互连构成了芯片的很大一部分,但是远未得到充分利用。用于这项研究的小裸片是其约束的一部分,这是可以理解的。通过我们的测量,收发器占用的硅比处理元件多出约30%。更加理想的是具有更大的加工元件网格的更强的裸片。互连将能够支持这一点,并且每个小芯片最终将更加平衡。
还有一个方面是进一步扩展。开发的GRS Nvidia不仅可以缩放到同一封装中的其他裸片,还可以缩放到多个封装。看起来英伟达并没有尝试向外扩展到一个更大的系统,但是看看144个芯片和半个peta-ops (pop)计算系统的扩展效果一定会很有趣。
铺垫
该芯片允许Nvidia调查各种技术的影响,包括他们已经研究了超过五年的地面参考信令链路。在去年的VLSI研讨会上,Bill Dally发表了一个主题演讲,他表示类似的信令技术将使Nvidia能够缩放,因为生产更小的芯片变得更有利,因为前沿节点的成本不断上升。他概述的一个想法是带有共同封装DRAM的2×2 GPU阵列。然后将该板集成在具有2×2个这样的板的较大板上,总共16个GPU。他进一步建议,然后可以在网格圆环拓扑中缩放这些板。




-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 进迭时空完成A+轮数亿元融资 加速RISC-V AI CPU产品迭代
- 2 复杂SoC芯片设计中有哪些挑战?
- 3 MediaTek 发布天玑 8400 移动芯片,开启高阶智能手机全大核计算时代
- 4 探索智慧实践,洞见AI未来!星宸科技2024开发者大会暨产品发布会成功举办
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号