
智算未来,合见工软打造国产EDA智算新引擎
2024-12-26
14:08:07
来源: 互联网
点击
在大数据、云计算、人工智能等技术的发展下,当今世界正在进入智算时代。未来,智算芯片的需求特点将越来越多地体现为高性能计算、高精度计算、高能效比、高内存带宽、高互联总线带宽,大规模设计及先进封装等等。这对于芯片设计者来说不可避免地成为新的挑战,需要在性能提升、能效管理、系统优化等多个维度上进行探索,以突破算力墙、存储墙、能耗墙、互联墙等诸多方面的限制。
在12月11日召开的ICCAD 2024高峰论坛上,合见工软副总裁吴晓忠发表了“智算时代,合见工软加速创新未来”的主题演讲。吴晓忠指出,合见工软将致力于智算时代的国产EDA创新战略,支持为国产智算芯片公司提供“EDA+IP+系统级”的联合解决方案,为智算时代智算芯片的开发提供有力支持。
打造国产供应链推动智算产业发展
合见工软作为自主创新的高性能工业软件及解决方案提供商,在展会现场展示了与智算芯片相关的完整解决方案,包括EDA+IP+系统级方案等。在高峰论坛上,合见工软副总裁吴晓忠也将演讲的主题聚焦于,智算时代给国产智算芯片带来的机遇与挑战。

合见工软副总裁吴晓忠
由于人工智能应用的驱动,人工智能训练算力需求自2010起加速增长,至2024已成长一亿倍。随着OpenAI o1 和未来人工智能的技术突破会产生新的智算需求。根据统计数据,芯片公司的成长已超过软件公司,美国股市市值前10大公司有7家来自智算芯片设计业。
近年来,中国持续推进智算芯片产业,以支撑人工智能的发展,预计中国智能算力规模2027年将达到1117.4EFLOPS。然而,随着政治及地缘环境的变化,中国人工智能产业从设计、工具和制造等方面受到了多重限制。
吴晓忠提到:“在此情况下,中国发展智算产业,必须充分利用自身优势,打造国产供应链。”吴晓忠对此强调指出,“中国的智算主权要靠国产智算芯片公司提供,支持国产智算芯片公司的基础设施既包括晶圆厂、装备材料等硬件设施,也包括EDA工具、硅知识产权IP等软件生态。”
合见工软是国内首家可以为高性能智算芯片设计提供“EDA+IP+系统级”联合解决方案的工具供应商。公司发布的创新产品涵盖了数字验证全新硬件平台、DFT全流程工具、PCB板级设计工具以及高速接口IP解决方案等多个领域。这些产品和解决方案的推出,不仅提升了国产EDA工具的技术水平,也为智算时代算力芯片的开发提供了有力支持。
仿真验证平台助力突破算力墙存储墙限制
算力墙、存储墙、能耗墙、互联墙是智算时代芯片设计者面临的重大限制和挑战。为了满足人工智能、数据中心、自动驾驶等场景对大算力的广泛需求,芯片尺寸和规模越来越大,单芯片晶体管多达百亿甚至千亿级别。同时,高阶工艺和先进封装如Chiplet等技术的应用,也大大增加了芯片的集成度与复杂度。这使芯片设计者不得不面临更多限制与挑战,也给EDA工具和IP提出更高要求。
在算力方面,设计公司面对的挑战可归纳为复杂且快速发展的芯片设计需求,用户既要考虑芯片面积的限制,还要考虑在有限单位面积中所采取的不同工艺,此外不同计算体系架构里的整体运行频率也有限制。“这就要求验证工具除了必须为芯片设计开发提供更快速准确的编译和更高效的调试能力,还必须具备更灵活、更统一的全场景验证平台。这不仅可提升故障纠错效率和验证吞吐量,还能降低大规模复杂芯片流片的失效风险,并为软硬件协同仿真验证提供强大的数字孪生能力。”吴晓忠指出。

针对这一需求趋势,日前合见工软推出全场景验证解决方案,其核心是创新的数据中心级全场景超大容量硬件仿真加速验证平台UniVista Hyperscale Emulator。该平台将硬件仿真系统的算力提升至数据中心级别,系统规模支持1.6亿门到460亿门可调,为国产自研硬件仿真器中首台可扩展至460亿逻辑门设计的产品,其性能可对标国际先进产品。同时,大幅提升智算软件开发效率,具备完备的高速接口降速桥方案(SA),具备完备的高速存储模型方案(MMK)。
此外,合见工软还推出新一代PD-AS原型验证平台,采用AMD Versal™ Premium VP1902 Adaptive SoC作为原型验证的基础硬件平台,拥有18.5M逻辑单元,等效逻辑门数达1亿门;搭载高速serdes,拥有64lane GTYP 和16lane GTM,GTYP的传输速度可达到32Gb/s,GTM的传输速度更可高达56Gb/s;更丰富的接口扩展方案:集成2000+个XPIO,同时提供板载大容量DDR4存储,配套大量的接口扩展方案,覆盖尽可能多的应用场景。该平台适用于智算中小规模芯片及子系统设计和验证,缩减测试进程,加快芯片面市。
合见工软上述两大仿真验证平台的推出,可为AI智算芯片提供从单卡到多卡组网的系统级功能及性能验证,有效填补了国内大规模全场景硬件仿真系统的空白。
DFT平台工具优化架构设计
无论是算力墙还是存储墙,都是智算芯片中在数据处理和运算过程中遭遇的重要挑战,特别是在处理需要频繁访问内存的任务时,逻辑运算与内存速度不匹配的问题尤为突出,往往成为制约智算芯片性能进一步提升的关键因素。
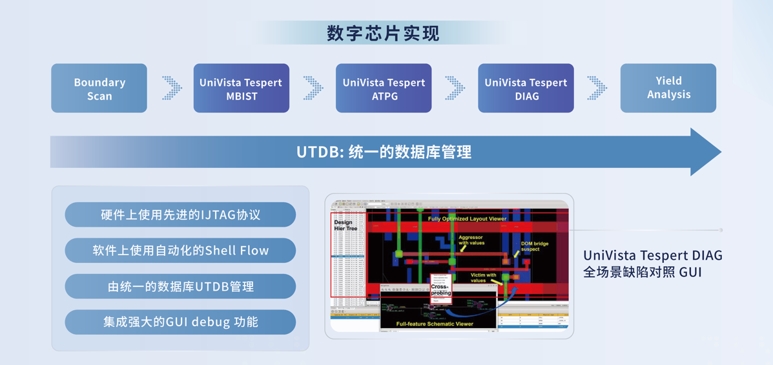
“这需要在芯片设计时就进行全流程可测性设计(DFT)及诊断,优化架构,解决内存访问速度的限制等问题。”吴晓忠表示。合见工软具有完备的DFT设计以及诊断方案。比如在针对传统单Die测试方案中,就包括了先进的IJTAG协议,自动化的Shell Flow,统一的数据库UTDB管理工具,自动化的版图级诊断分析工具。在针对Multi-Die测试方案中,包括基于1149.1 TAP的串行控制机制;Die Wrapper Register,支持对内对外测试;以及即将推出的Flexible Parallel Port (FPP)——IEEE1838等。
以合见工软9月份最新推出的国产自主知识产权的可测性设计(DFT)全流程平台UniVista Tespert为例。该平台集成了一系列高效工具,其中颇具代表性地集成了高效的存储单元内建自测试软件工具UniVista Tespert MBIST,可以有效提高测试设置的效率和可靠性,有助于芯片公司进行架构优化,解决内存访问速度的限制问题。
系统级EDA解决方案改善能耗问题
智算时代的产品设计越来越需要从系统角度考虑问题,相关产品如板卡、服务器、网络设备的复杂度不断增加,设计规模大、可靠性要求高、周期时间短、布线规则复杂。而且随着计算规模的扩大,能耗问题也日益突出,能耗墙成为横亘在所有设计者面前的一大挑战。需要从架构优化、系统及封装级优化等层级进行改善,这对更高性能、更紧凑、更可靠的PCB设计与先进封装提出了更高要求。
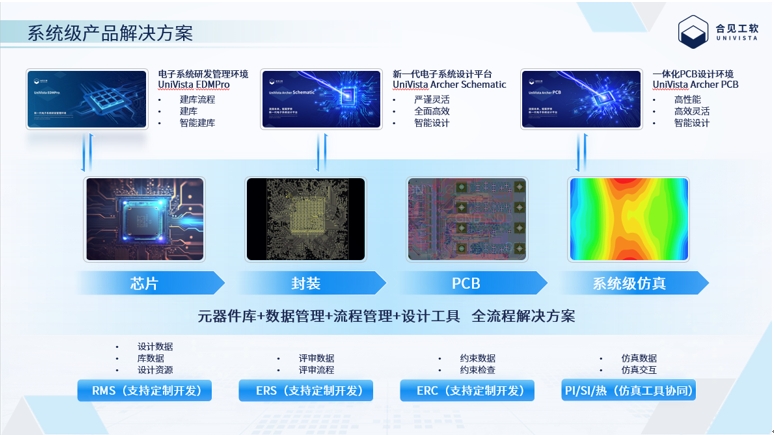
针对这一趋势,合见工软推出新一代电子系统设计平台UniVista Archer,作为自主知识产权的国产首款高端大规模PCB设计平台,可以满足日益复杂的电子系统设计需求,解决高速、多层PCB设计中带来的设计与仿真挑战。
吴晓忠指出:“UniVista Archer平台包括两款产品:一体化PCB设计环境的Archer PCB和板级系统电路原理设计输入环境的Archer Schematic。采用全新的先进数据架构,部分产品性能大幅提升,能够精准洞察用户的需求习惯,大幅提升用户体验,满足用户的复杂功能需求,为现代复杂电子系统提供一体化的智能设计环境。而封装与系统级需求的改善能够有效缓解因计算规模扩大而导致的能耗问题。”
完整IP产品支持高速互联设计
智算时代对高速互联技术产品提出更高要求,如高性能以太网RDMA、UCIE、HBM等,不仅体现在传输速度上,更在于如何实现更低延迟、更高效率、更强可扩展性的全面互联,以满足日益复杂的数据处理和推理需求。
合见工软拥有丰富的IP产品可以支持智算高速互联的需求,日前推出五款具有自主知识产权高速接口IP解决方案,包括高性能的网络IP、存储IP及Chiplet接口IP解决方案等,可应对智算时代所带来的网络互联、先进封装的互联集成、高数据吞吐量等诸多挑战。

以合见工软的智算网络IP解决方案UniVista RDMA IP为例,其可支持200G、400G带宽的完整RoCEv2传输层、网络层、链路层、物理编码层,可帮助芯片设计人员实现快速的RDMA功能集成,解决智算芯片的高带宽需求问题,可广泛应用于AI、GPU、DPU等多类芯片设计中,相比于传统25G/50G RDMA互联方案,性能更领先。相关产品已实现在AI和GPU等领域的国内头部IC企业中的成功部署应用。基于合见工软全场景验证硬件系统UniVista Unified Verification Hardware System(简称“UVHS”)的400G RDMA组网验证平台,现已成为国内唯一已经商用落地的RDMA IP及组网验证解决方案。
此外,作为Chiplet集成的关键标准之一,UCIe以开放、灵活、高性能的设计框架为核心,实现了采用不同工艺和制程的芯粒之间的无缝互连和互通。合见工软在今年已推出了下一代Chiplet集成创新的全国产UCIe IP解决方案UniVista UCIe IP,该IP产品已在智算、自动驾驶、AI等领域的知名客户的实际项目中得到广泛应用和验证,在真实场景中展现出卓越的性能表现和稳定可靠的品质。合见工软UCIe IP先进制程测试芯片现已成功流片,并在此次ICCAD-Expo展会上展出,该产品是IP领域第二个经由硬件验证过的先进制程UCIe IP产品。

针对智算时代的关键内存器件之一的HBM(高带宽内存),合见工软也在今年推出了加速存算一体化的全国产HBM3/E IP解决方案UniVista HBM3/E IP,其包括HBM3/E内存控制器、物理层接口(PHY)和验证平台,采用低功耗接口和创新的时钟架构,实现了更高的总体吞吐量和更优的每瓦带宽效率,可帮助芯片设计人员实现超小PHY面积的同时支持最高9.6 Gbps的数据速率,解决各类前沿应用对数据吞吐量和访问延迟要求严苛的场景需求问题,可广泛应用于以AI/机器学习应用为代表的数据与计算密集型SoC等多类芯片设计中,已实现在AI/ML、数据中心和HPC等领域的国内头部IC企业中的成功部署应用。
合见工软志在为客户提供可靠的先进接口IP整体解决方案,帮助客户解决在面对新的应用场景和封装形式时在接口实现和使用上的一系列挑战。合见工软在提供可靠解决方案之外,还对于部分协议进行优化,帮助客户在使用标准接口时,获得额外的场景便利性,助力用户突破互联限制。
在智算时代的浪潮中,合见工软凭借其“EDA+IP+系统级”联合解决方案,为国产智算芯片的设计提供了坚实的基础。未来,合见工软将在自主创新与产业链协同的基础上,继续不断发展完善智算工具,助力国产智算芯片核心竞争力的提升。
在12月11日召开的ICCAD 2024高峰论坛上,合见工软副总裁吴晓忠发表了“智算时代,合见工软加速创新未来”的主题演讲。吴晓忠指出,合见工软将致力于智算时代的国产EDA创新战略,支持为国产智算芯片公司提供“EDA+IP+系统级”的联合解决方案,为智算时代智算芯片的开发提供有力支持。
打造国产供应链推动智算产业发展
合见工软作为自主创新的高性能工业软件及解决方案提供商,在展会现场展示了与智算芯片相关的完整解决方案,包括EDA+IP+系统级方案等。在高峰论坛上,合见工软副总裁吴晓忠也将演讲的主题聚焦于,智算时代给国产智算芯片带来的机遇与挑战。
合见工软副总裁吴晓忠
由于人工智能应用的驱动,人工智能训练算力需求自2010起加速增长,至2024已成长一亿倍。随着OpenAI o1 和未来人工智能的技术突破会产生新的智算需求。根据统计数据,芯片公司的成长已超过软件公司,美国股市市值前10大公司有7家来自智算芯片设计业。
近年来,中国持续推进智算芯片产业,以支撑人工智能的发展,预计中国智能算力规模2027年将达到1117.4EFLOPS。然而,随着政治及地缘环境的变化,中国人工智能产业从设计、工具和制造等方面受到了多重限制。
吴晓忠提到:“在此情况下,中国发展智算产业,必须充分利用自身优势,打造国产供应链。”吴晓忠对此强调指出,“中国的智算主权要靠国产智算芯片公司提供,支持国产智算芯片公司的基础设施既包括晶圆厂、装备材料等硬件设施,也包括EDA工具、硅知识产权IP等软件生态。”
合见工软是国内首家可以为高性能智算芯片设计提供“EDA+IP+系统级”联合解决方案的工具供应商。公司发布的创新产品涵盖了数字验证全新硬件平台、DFT全流程工具、PCB板级设计工具以及高速接口IP解决方案等多个领域。这些产品和解决方案的推出,不仅提升了国产EDA工具的技术水平,也为智算时代算力芯片的开发提供了有力支持。
仿真验证平台助力突破算力墙存储墙限制
算力墙、存储墙、能耗墙、互联墙是智算时代芯片设计者面临的重大限制和挑战。为了满足人工智能、数据中心、自动驾驶等场景对大算力的广泛需求,芯片尺寸和规模越来越大,单芯片晶体管多达百亿甚至千亿级别。同时,高阶工艺和先进封装如Chiplet等技术的应用,也大大增加了芯片的集成度与复杂度。这使芯片设计者不得不面临更多限制与挑战,也给EDA工具和IP提出更高要求。
在算力方面,设计公司面对的挑战可归纳为复杂且快速发展的芯片设计需求,用户既要考虑芯片面积的限制,还要考虑在有限单位面积中所采取的不同工艺,此外不同计算体系架构里的整体运行频率也有限制。“这就要求验证工具除了必须为芯片设计开发提供更快速准确的编译和更高效的调试能力,还必须具备更灵活、更统一的全场景验证平台。这不仅可提升故障纠错效率和验证吞吐量,还能降低大规模复杂芯片流片的失效风险,并为软硬件协同仿真验证提供强大的数字孪生能力。”吴晓忠指出。
针对这一需求趋势,日前合见工软推出全场景验证解决方案,其核心是创新的数据中心级全场景超大容量硬件仿真加速验证平台UniVista Hyperscale Emulator。该平台将硬件仿真系统的算力提升至数据中心级别,系统规模支持1.6亿门到460亿门可调,为国产自研硬件仿真器中首台可扩展至460亿逻辑门设计的产品,其性能可对标国际先进产品。同时,大幅提升智算软件开发效率,具备完备的高速接口降速桥方案(SA),具备完备的高速存储模型方案(MMK)。
此外,合见工软还推出新一代PD-AS原型验证平台,采用AMD Versal™ Premium VP1902 Adaptive SoC作为原型验证的基础硬件平台,拥有18.5M逻辑单元,等效逻辑门数达1亿门;搭载高速serdes,拥有64lane GTYP 和16lane GTM,GTYP的传输速度可达到32Gb/s,GTM的传输速度更可高达56Gb/s;更丰富的接口扩展方案:集成2000+个XPIO,同时提供板载大容量DDR4存储,配套大量的接口扩展方案,覆盖尽可能多的应用场景。该平台适用于智算中小规模芯片及子系统设计和验证,缩减测试进程,加快芯片面市。
合见工软上述两大仿真验证平台的推出,可为AI智算芯片提供从单卡到多卡组网的系统级功能及性能验证,有效填补了国内大规模全场景硬件仿真系统的空白。
DFT平台工具优化架构设计
无论是算力墙还是存储墙,都是智算芯片中在数据处理和运算过程中遭遇的重要挑战,特别是在处理需要频繁访问内存的任务时,逻辑运算与内存速度不匹配的问题尤为突出,往往成为制约智算芯片性能进一步提升的关键因素。
“这需要在芯片设计时就进行全流程可测性设计(DFT)及诊断,优化架构,解决内存访问速度的限制等问题。”吴晓忠表示。合见工软具有完备的DFT设计以及诊断方案。比如在针对传统单Die测试方案中,就包括了先进的IJTAG协议,自动化的Shell Flow,统一的数据库UTDB管理工具,自动化的版图级诊断分析工具。在针对Multi-Die测试方案中,包括基于1149.1 TAP的串行控制机制;Die Wrapper Register,支持对内对外测试;以及即将推出的Flexible Parallel Port (FPP)——IEEE1838等。
以合见工软9月份最新推出的国产自主知识产权的可测性设计(DFT)全流程平台UniVista Tespert为例。该平台集成了一系列高效工具,其中颇具代表性地集成了高效的存储单元内建自测试软件工具UniVista Tespert MBIST,可以有效提高测试设置的效率和可靠性,有助于芯片公司进行架构优化,解决内存访问速度的限制问题。
系统级EDA解决方案改善能耗问题
智算时代的产品设计越来越需要从系统角度考虑问题,相关产品如板卡、服务器、网络设备的复杂度不断增加,设计规模大、可靠性要求高、周期时间短、布线规则复杂。而且随着计算规模的扩大,能耗问题也日益突出,能耗墙成为横亘在所有设计者面前的一大挑战。需要从架构优化、系统及封装级优化等层级进行改善,这对更高性能、更紧凑、更可靠的PCB设计与先进封装提出了更高要求。
针对这一趋势,合见工软推出新一代电子系统设计平台UniVista Archer,作为自主知识产权的国产首款高端大规模PCB设计平台,可以满足日益复杂的电子系统设计需求,解决高速、多层PCB设计中带来的设计与仿真挑战。
吴晓忠指出:“UniVista Archer平台包括两款产品:一体化PCB设计环境的Archer PCB和板级系统电路原理设计输入环境的Archer Schematic。采用全新的先进数据架构,部分产品性能大幅提升,能够精准洞察用户的需求习惯,大幅提升用户体验,满足用户的复杂功能需求,为现代复杂电子系统提供一体化的智能设计环境。而封装与系统级需求的改善能够有效缓解因计算规模扩大而导致的能耗问题。”
完整IP产品支持高速互联设计
智算时代对高速互联技术产品提出更高要求,如高性能以太网RDMA、UCIE、HBM等,不仅体现在传输速度上,更在于如何实现更低延迟、更高效率、更强可扩展性的全面互联,以满足日益复杂的数据处理和推理需求。
合见工软拥有丰富的IP产品可以支持智算高速互联的需求,日前推出五款具有自主知识产权高速接口IP解决方案,包括高性能的网络IP、存储IP及Chiplet接口IP解决方案等,可应对智算时代所带来的网络互联、先进封装的互联集成、高数据吞吐量等诸多挑战。
以合见工软的智算网络IP解决方案UniVista RDMA IP为例,其可支持200G、400G带宽的完整RoCEv2传输层、网络层、链路层、物理编码层,可帮助芯片设计人员实现快速的RDMA功能集成,解决智算芯片的高带宽需求问题,可广泛应用于AI、GPU、DPU等多类芯片设计中,相比于传统25G/50G RDMA互联方案,性能更领先。相关产品已实现在AI和GPU等领域的国内头部IC企业中的成功部署应用。基于合见工软全场景验证硬件系统UniVista Unified Verification Hardware System(简称“UVHS”)的400G RDMA组网验证平台,现已成为国内唯一已经商用落地的RDMA IP及组网验证解决方案。
此外,作为Chiplet集成的关键标准之一,UCIe以开放、灵活、高性能的设计框架为核心,实现了采用不同工艺和制程的芯粒之间的无缝互连和互通。合见工软在今年已推出了下一代Chiplet集成创新的全国产UCIe IP解决方案UniVista UCIe IP,该IP产品已在智算、自动驾驶、AI等领域的知名客户的实际项目中得到广泛应用和验证,在真实场景中展现出卓越的性能表现和稳定可靠的品质。合见工软UCIe IP先进制程测试芯片现已成功流片,并在此次ICCAD-Expo展会上展出,该产品是IP领域第二个经由硬件验证过的先进制程UCIe IP产品。
针对智算时代的关键内存器件之一的HBM(高带宽内存),合见工软也在今年推出了加速存算一体化的全国产HBM3/E IP解决方案UniVista HBM3/E IP,其包括HBM3/E内存控制器、物理层接口(PHY)和验证平台,采用低功耗接口和创新的时钟架构,实现了更高的总体吞吐量和更优的每瓦带宽效率,可帮助芯片设计人员实现超小PHY面积的同时支持最高9.6 Gbps的数据速率,解决各类前沿应用对数据吞吐量和访问延迟要求严苛的场景需求问题,可广泛应用于以AI/机器学习应用为代表的数据与计算密集型SoC等多类芯片设计中,已实现在AI/ML、数据中心和HPC等领域的国内头部IC企业中的成功部署应用。
合见工软志在为客户提供可靠的先进接口IP整体解决方案,帮助客户解决在面对新的应用场景和封装形式时在接口实现和使用上的一系列挑战。合见工软在提供可靠解决方案之外,还对于部分协议进行优化,帮助客户在使用标准接口时,获得额外的场景便利性,助力用户突破互联限制。
在智算时代的浪潮中,合见工软凭借其“EDA+IP+系统级”联合解决方案,为国产智算芯片的设计提供了坚实的基础。未来,合见工软将在自主创新与产业链协同的基础上,继续不断发展完善智算工具,助力国产智算芯片核心竞争力的提升。
责任编辑:Ace
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 英伟达,又挖了一道护城河
- 2 江波龙全球最小尺寸eMMC,为AI穿戴设备“减负”
- 3 奕行智能(EVAS Intelligence)完成数亿元A轮融资,加速推出RISC-V计算芯片产品,共同助力新时代到来
- 4 Solidigm宣布与博通拓展大容量SSD控制器在AI领域的应用合作
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号