
英伟达最强芯片曝光:18176个内核、48 GB内存、24 Gbps速度和800W TBP
来源:内容由 半导体行业观察(ID: icb a nk)编译自wccftech, 谢 谢。
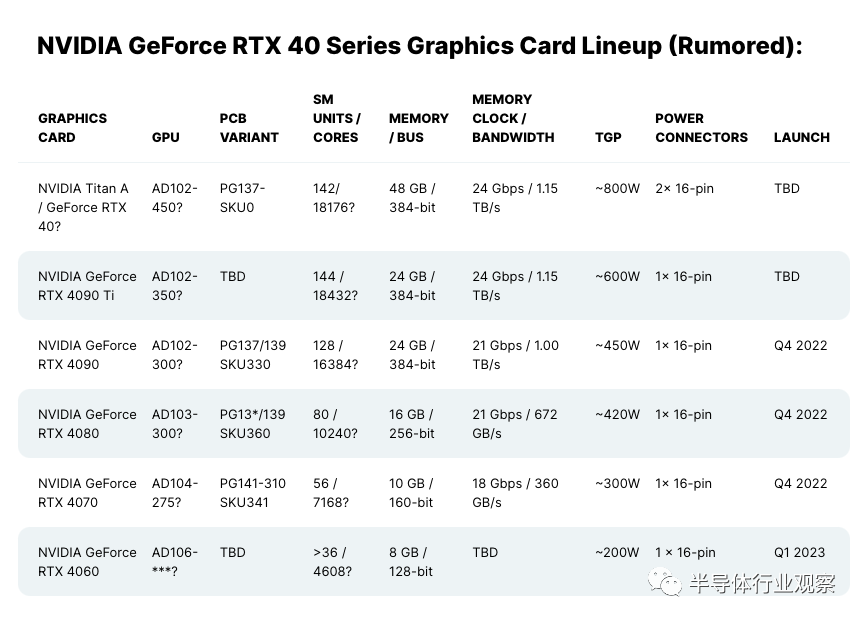
最近,博主Kopite7kimi报告了有关英伟达旗舰芯片 NVIDIA Ada Lovelace GPU SKU 的详细信息,这使它看起来像是有史以来最强大的终极图形芯片。传闻指出,NVIDIA Ada Lovelace 旗舰 GPU 采用 AD102-450 GPU,具有 18176 个内核、48 GB“24 Gbps”GDDR6X 显存和 800W TBP.
这不是第一次谈论如此高端的 Ada Lovelace GPU SKU。之前的传言也来自同一个泄密者,它报道了 Ada Lovelace GPU 阵容中的 Titan-Class 显卡,该显卡具有一些疯狂的规格。再一次,这不是完全启用的 AD102 GPU,而之前的变体被提及为具有完整 18432 CUDA 内核的 900W TBP SKU。
根据传闻的规格,该显卡将采用 Ada Lovelace 架构并具有略微缩减的配置“AD102-450-A1”,在 18,432 个 CUDA 内核(18432 个 CUDA 中)上摇摆 142 个 SM(144 个 SM)核心)。基于大约 3 GHz 的时钟速度,这款显卡将轻松突破 100 TFLOPs 计算障碍。据说该显卡配备 48 GB GDDR6X 内存,运行在 384 位总线接口上。
有趣的是,NVIDIA 不会拘泥于 VRAM 规格,而是采用最新的 24 Gbps 内存模块,为 GPU 提供高达 1.152 TB/s 的 VRAM 带宽。与具有 21 Gbps 内存芯片的现有 RTX 3090 Ti 旗舰产品相比,内存带宽增加了 14%。即将推出的 RTX 4090 也有望使用相同的 21 Gbps 内存芯片,只有旗舰“Ti”型号获得 24 Gbps 芯片。
功耗方面,新的NVIDIA旗舰AD102 GPU驱动的显卡将是疯狂的,其TDP几乎是RTX 3090 Ti的两倍,额定功率高达800W。考虑到单个 16 针连接器只能提供 600 瓦的功率,如果它成为现实,就必须为这种卡的怪物使用双 16 针连接器配置。图形卡可以使用 PG137-SKU0。
基于 Ampere 阵容,我们看到 NVIDIA 不仅没有发布 Titan 显卡,而且实质上用其 BFGPU 级 GeForce RTX 阵容取代了 Titan 系列。更高容量的卡仍然作为工作站 RTX Axxx系列推出,它也得到了完整的 GA102 处理,但除了RTX 3090 Ti和RTX A6000之外,没有 Titan 级。那么 Titan 级 GPU 对 Ada Lovelace 是否有意义,或者这个特定的 SKU 最终会成为下一代游戏 BFGPU 和工作站的旗舰产品吗?好吧,我们不能肯定地说,但有一件事是绝对正确的,这样的 GPU 配置在规格、功耗和价格方面确实是疯狂的。该卡如果涉及零售,肯定会在RTX 4090之后推出预计将于今年秋季晚些时候亮相。
Nvidia Ada Lovelace 和 GeForce RTX 40 系列:我们所知道的一切
Nvidia 的 Ada 架构和 GeForce RTX 40 系列显卡预计将于今年年底上市,并且可能在 9 月至 10 月的时间范围内——发生在Nvidia Ampere 架构之后的两年,考虑到摩尔“定律”的放缓(或者如果你愿意,死亡),英伟达这个发布步骤基本上是按计划进行的。随着今年早些时候的Nvidia 遭受黑客攻击,我们获得了关于预期结果的大量信息。我们已将所有内容收集到这里,详细介绍了我们对 Nvidia 的 Ada 架构和 RTX 40 系列家族的了解和期望。
现在有很多谣言在流传,但英伟达几乎没有透露其对 Ada 的计划,有些人将其称为 Lovelace。我们所知道的是,Nvidia 已经详细介绍了其数据中心Hopper H100 GPU,我们怀疑,就像Volta V100和Ampere A100一样,消费产品将在不久的将来跟进。
最后一个可能是预期的最佳样本。A100 于 2020 年 5 月正式发布,消费级 Ampere GPU 以RTX 3080和RTX 3090的形式推出大约四个月后。如果 Nvidia Ada Lovelace GPU 遵循类似的发布时间表,我们可以预期 RTX 40 系列将在 8 月或 9 月的某个时候到货。让我们从 Ada 系列 GPU 的传闻规格的高级版本预览开始。
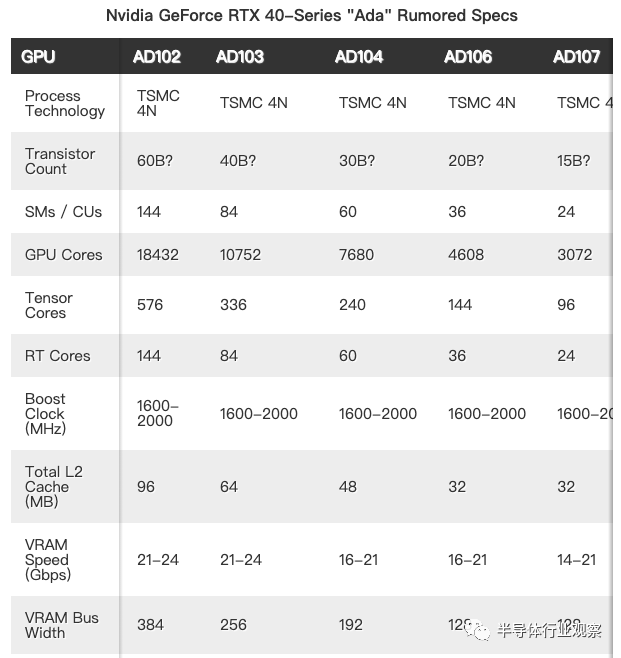
首先,根据预计,GPU 提供了介乎 1.6 到 2.0 GHz 的暂定时钟速度估计值,这与 Nvidia 之前的 Ampere、Turing 甚至 Pascal 架构一致。Nvidia 完全有可能超过这些时钟,因此我们认为这是一个保守的估计。
我们假设 Nvidia 将在所有 Ada GPU 上使用 TSMC 的 4N 工艺——“4nm Nvidia”,这在技术上可能又是不正确的。我们知道 Hopper H100 使用台积电的 4N 节点,这似乎主要是对台积电 N5 节点的调整变体,该节点已广泛用于苹果的智能手机和笔记本电脑芯片,并且据传闻,Nvidia 会将该节点用于 Ada。值得一提的是, AMD也有可能将其用于Zen 4 和RDNA 3。
坦率地说,节点名称并不像实际的 GPU 规格和性能那么重要。换句话说,“任何其他名字的玫瑰都会闻起来很香”。我们早就过了工艺节点名称与芯片上的物理特性有任何实际联系的年代。在 250nm(或 0.25 微米)芯片实际上具有可以指向并以 0.25um 宽度进行测量的元素时,芯片的物理缩放在过去的几个工艺节点上已经放缓,它们现在只是营销名称。
晶体管数量是目前最好的猜测。我们确实知道 Hopper H100 将拥有 800 亿个晶体管(这实际上只是一个近似值,但我们会继续使用它)。A100 GPU 有 560 亿个晶体管,是 GA102 消费级 halo芯片数量的两倍,但有迹象表明 Nvidia 将在 AD102 GPU 上“做大”,而且它的尺寸可能更接近 H100,而不是 GA102 . 如果有可靠的信息可用,我们将更新这些表格,但目前,任何关于晶体管数量的说法都只是与我们不同的猜测。
理论上,根据我们目前看到的“泄露”信息,Ada看起来是个怪物。与当前的 Ampere GPU 相比,它将包含更多的 SM 和相关内核,这将大大提高性能。即使 Ada 最终比泄漏所声称的要少,可以肯定的是,我们会看到顶级 GPU 的性能——也许是 RTX 4090,尽管 Nvidia 可能会再次改变命名法——不过毫无疑问,新产品将是领先RTX 3090 Ti 的一大进步.
例如,RTX 3080 在发布时比 RTX 2080 Ti 快了大约 30%,而 RTX 3090 又增加了 15%,至少如果你以 4K 超分辨率将 GPU 推到极限的话。这也是需要牢记的。如果您当前运行的是更适中的处理器,而不是绝对最好的游戏 CPU 之一(Core i9-12900K或Ryzen 7 5800X3D),这意味着即使在 1440p 超分辨率下,你也很可能会限制 CPU。为了充分利用最快的 Ada GPU,可能需要进行更大的系统升级。
在高级版本简介完毕之后,让我们进入细节。
一
ADA 将大幅提升计算性能
与当前 Ampere 代相比,Ada GPU 最显著的变化将是 SM 的数量。据猜测,AD102 包含的 SM 可能比 GA102 多 71%。即使架构没有其他任何重大变化,我们也预计性能会大幅提高。
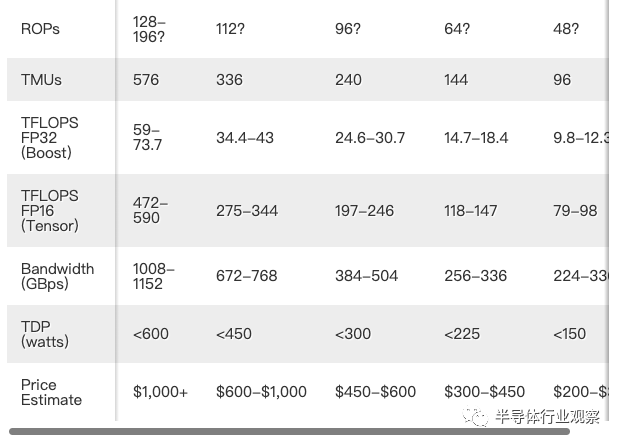
这不仅适用于图形,也适用于其他元素。我们在 Tensor 核心性能上使用安培计算(Ampere calculations),运行频率接近 2GHz 的完全启用的 AD102 芯片将在 FP16 中具有高达 590 TFLOPS 的深度学习/AI 计算。相比之下,RTX 3090 Ti 中的 GA102 最高约为 321 TFLOPS FP16(使用 Nvidia 的稀疏特性)。根据核心数量和时钟速度,新产品理论上增加了 84%。理论上 84% 的性能提升同样适用于光线追踪硬件。
除非 Nvidia 为各自的第三代和第四代实现重新设计 RT 内核和 Tensor 内核。我们怀疑不需要对 Tensor 内核进行大规模更改——Hopper H100 的深度学习硬件的重大改进将比 Ada AD102 更多。同时,RT 内核可以很容易地看到每核 RT 性能比 Ampere 再提高 25-50% 的改进,就像 Ampere 每个 RT 内核比 Turing 快 75% 左右一样。
最坏的情况,只是将 Ampere 架构从三星 Foundry 的 8N 工艺移植到 TSMC 的 4N(或 5N 或其他),并没有真正改变架构的任何其他内容,添加更多内核并保持类似的时钟应该提供足够的一代性能提升. Nvidia 的表现可能远远超过最低要求,但即使是位于底部的AD107 芯片也比当前的 RTX 3050快30% 或更多的改进。
请记住,列出的 SM 数量是完整的芯片,而且很可能 Nvidia 将使用部分禁用的芯片来提高良率。以 Hopper H100 为例,它有 144 个潜在的 SM,但在 SXM5 变体上仅启用了 132 个 SM,而 PCIe 5.0 卡将启用 114 个 SM。我们可能会看到 Nvidia 推出高端 AD102 解决方案(即 RTX 4090),其中启用了 132 到 140 个 SM,较低层型号使用更少的 SM。在良率提高后,这当然为未来带有完全启用 AD102 的卡(即 RTX 4090 Ti)打开了大门。
二
猜测 ADA 的 ROP
我们在所有 Ada GPU 上的 ROP 计数(渲染输出)之后加上了问号,因为我们还不知道它们是如何配置的。通过 Ampere,Nvidia 将 ROP 与 GPC(图形处理集群)联系起来。每个 GPC 包含一定数量的 SM(流式多处理器),可以成对禁用。然而,即使我们知道 SM 的数量,我们也不知道它们是如何分成 GPC 的。
以带有 144 个 SM 的 AD102 为例。这可能是 12 个 GPC,每个 12 个 SM,8 个 GPC,每个 18 个 SM,或 9 个 GPC,每个 16 个 SM。其他可能性也存在,但这是我们认为最有可能的三种。Nvidia 对 GPU 游戏并不陌生,因此无论安排如何,最终我们都应该期望它能够满足 GPU 的需求。
我们已经看到一些猜测表明 GA102 将有 12 个 GPC,每个 GPC 有 12 个 SM,这将产生 192 个 ROP 作为最大值。这不是不可能的,但请注意,Hopper H100 有 8 个 GPC 集群,每个集群有 18 个 SM,因此这对于 AD102 来说似乎也是一个合理的配置——只是没有 HBM3 并且较少关注深度学习硬件。
三
可疑的泄密和谣言
此外,AD102 的 144 个 SM 是令人怀疑的。巧合的是,Hopper H100 芯片共有 144 个 SM,其中 132 个在目前的顶级产品中启用。对于 Ada 和 Hopper 都拥有相同的 144 个 SM 来说,这将是非常令人惊讶的。GA100 最多有 120 个 SM,因此,对于 H100,Nvidia 仅将 SM 数量增加了 20%。相比之下,假设泄密信息是真的,那就意味着AD102 的 SM 比 GA102 多 71%。
我们现在没有更好的事情要做,所以我们报道了传闻中的 144 SM 数字,但如果这完全是假的,请不要感到惊讶。仅仅因为 Nvidia 被黑客入侵并且数据被泄露,并不意味着泄露的所有内容都是准确的。Nvidia 可能会更好地调整架构以获得更高的时钟并使用更少的 SM,类似于 AMD 对 RDNA 2 所做的,但这可能需要对底层架构进行更重大的改革。
另一方面,AD102 成为巨大芯片至少有一个充分的理由——专业 GPU。Nvidia 并未为消费者和专业市场制造完全独立的芯片,RTX A6000 等 A 系列芯片就是明证。它使用与 RTX 3080 到 3090 Ti 相同的 GA102 芯片,只是在驱动程序中打开了一些额外的功能。光线追踪并没有真正让游戏世界着火,但它对专业市场来说是一件大事,并且封装更多的 RT 核心将是 3D 渲染用户的福音。另请注意,Hopper H100 不包含任何光线追踪硬件,就像它所取代的 GA100 一样。
各种 Ada GPU 也将用于运行 AI 和 ML 算法的推理平台,这再次意味着可以使用更多的 Tensor 内核和计算。因此,最重要的是,假设的最大 144 个 SM 并不是完全不可能的,但它肯定值得怀疑。也许英伟达黑客发现了过时的信息,或者人们错误地解释了它。在接下来的几个月里,我们会知道更多。
四
内存子系统:GDDR6X 再上新台阶
早前,美光宣布它拥有运行速度高达 24Gbps 的 GDDR6X 内存的路线图。最新的 RTX 3090 Ti 仅使用 21Gbps 内存,而 Nvidia 是目前唯一一家使用 GDDR6X 的公司。这立即引发了将使用 24Gbps GDDR6X 的问题,唯一合理的答案似乎是 Nvidia Ada。较低层的 GPU 更有可能坚持使用标准 GDDR6 而不是 GDDR6X,其最高速度为 18Gbps。
这代表了一个问题,因为 GPU 通常需要计算和带宽来按比例扩展以实现承诺的性能量。例如,RTX 3090 Ti 的计算量比 3090 多 12%,更高的时钟内存提供了 8% 的带宽。如果我们上面的计算估计证明甚至接近准确,那么就会出现巨大的脱节。假设的 RTX 4090 的计算量可能比 RTX 3090 Ti 多 80%,但带宽仅多 14%。
假设可以控制 GDDR6X 功耗,那么在较低级别的GPU 上带宽增长的空间要大得多。当前的 RTX 3050 到 RTX 3070 都使用标准 GDDR6 内存,主频为 14-15Gbps。我们已经知道运行在 18Gbps 的 GDDR6 将及时为 Ada 提供,因此具有 18Gbps GDDR6 的假设 RTX 4050 应该可以轻松跟上 GPU 计算能力的增长。如果 Nvidia 仍然需要更多带宽,它也可以将 GDDR6X 用于较低层的 GPU。
更高级别的 Ada GPU 最终与 GDDR7 或三星的“GDDR6+”配对的可能性也很小,据报道,这将达到高达 27Gbps 的速度。然而,我们还没有听到关于其中任何一个的具体细节,在这个阶段,Nvidia 将需要其合作伙伴来提高内存产量。更多的生产将不可避免地导致更多的泄漏,由于我们还没有看到 GDDR7 或 GDDR6+ 生产的泄漏,我们假设它不会及时出现。
更有可能的是,Nvidia不需要大幅增加纯内存带宽,因为它会重新设计架构,类似于我们看到 AMD 对 RDNA 2 所做的与原始 RDNA 架构相比。
五
ADA 希望利用 L2 缓存获利
一种减少对更多原始内存带宽需求的好方法是几十年来已知和使用的方法——在芯片上增加更多缓存,您会获得更多cache hits,每次cache hits意味着 GPU 不需要从 GDDR6/GDDR6X 内存中提取数据。AMD 的 Infinity Cache 让 RDNA 2 芯片基本上可以用更少的原始带宽做更多的事情,泄露的Nvidia Ada L2 缓存信息表明 Nvidia 将采取类似的方法。
AMD 在 Navi 21 GPU 上使用了高达 128MB 的大型 L3 缓存,Navi 22 为 96MB,Navi 23 为 32MB,Navi 24 仅为 16MB。令人惊讶的是,即使是较小的 16MB 缓存也能为内存子系统带来奇迹。我们没想到Radeon RX 6500 XT总的来说是一张很棒的卡,但它基本上可以跟上内存带宽几乎是两倍的卡。
Ada 架构似乎将一个 8MB L2 缓存与每个 32 位内存控制器配对。这意味着具有 128 位内存接口的卡将获得 32MB 的总二级缓存,而堆栈顶部的 384 位接口卡将拥有 96MB 的二级缓存。虽然在某些情况下这比 AMD 的 Infinity Cache 要小,但我们还不知道延迟或设计的其他方面。L2 缓存的延迟往往低于 L3 缓存,因此稍小的 L2 肯定可以跟上更大但速度较慢的 L3 缓存。
如果我们以 AMD 的 RX 6700 XT 为例,它的计算能力比上一代 RX 5700 XT 高出约 35%。我们的GPU 基准测试层次结构中的性能同时在 1440p 超分辨率下高出约 32%,因此整体性能与计算几乎一致。除此之外,6700 XT 拥有 192 位接口,带宽仅为 384 GB/s,比 RX 5700 XT 的 448 GB/s 低 14%。这意味着大型 Infinity Cache 使 AMD 的有效带宽提高了 50%。
假设 Nvidia 可以通过 Ada 获得类似的结果,那么通过 24Gbps 内存将带宽增加 14%,然后将其与有效带宽增加 50% 配对。这将使 AD102 的有效带宽增加大约 71%,这与 GPU 计算的增加非常接近,因此一切都应该很好地发挥作用。
然而,关于缓存谣言的更多都是猜测。Nvidia 已经发布了有关 Hopper H100 的大量细节。它确实比上一代 GA100 具有更大的 L2 缓存大小,但它不是每个内存控制器 8MB。事实上,H100 上的总二级缓存为 50MB,而 A100 的二级缓存为 40MB。但 Hopper 也使用 HBM3 显存,将用于海量数据集,这也是它拥有 80GB 显存的原因。任何不能放入 40MB 的东西也不太可能放入 50MB 甚至 150MB。消费者工作负载,尤其是游戏,更有可能从更大的缓存中受益。Nvidia 可能会在这里追随 AMD 的脚步,或者谣言最终可能完全错误。
六
ADA的功耗
Ada 架构的一个元素肯定会引起一两个人的注意,那就是功耗。Igor's Lab 的 Igor 是第一个将 Ada 的 600W TBP(典型电路板功率)传闻记录在案的人,我们第一次听到就笑了。“不可能,”我们想。多年来,Nvidia 显卡的最高功率接近 250W,而 Ampere 在 RTX 3090(以及后来的 RTX 3080 Ti)上跃升至 350W 已经感觉有些过分了。随后英伟达公布了 Hopper H100 规格并发布了 RTX 3090 Ti,突然觉得 600W 的可能性不大。
这一切都可以追溯到 Dennard scaling的终结,以及摩尔定律的死亡。简而言之,Dennard scaling(也称为 MOSFET scaling)观察到,每一代,尺寸都可以缩小约 30%。这将总面积减少了 50%(长度和宽度都按比例缩放),电压下降了类似的 30%,电路延迟也将减少 30%。此外,频率将增加约 40%,总功耗将减少 50%。
如果这一切听起来好得令人难以置信,那是因为 Dennard scaling实际上在 2007 年左右停止发生。就像摩尔定律一样,它并没有完全失效,但收益变得不那么明显了。集成电路中的时钟速度仅从 2004 年 Pentium 4 Extreme Edition 的最高约 3.7GHz 增加到如今 Core i9-12900KS 的最高 5.5GHz。这仍然几乎增加了 50% 的频率,但它已经超过了六代(或更多,取决于您要如何计算)的流程节点改进。换句话说,如果 Dennard scaling没有死,现代 CPU 的时钟频率将高达 28GHz。
死亡的不仅仅是频率缩放,还有功率和电压缩放。如今,新的工艺节点还可以提高晶体管密度,不过需要平衡电压和频率。如果您想要一个速度快两倍的芯片,您可能需要使用几乎两倍的功率。或者,您可以构建更高效的芯片,但不会更快。Nvidia 似乎正在寻求 Ada 的第一个选项。
使用像 GA102 这样的 350W Ampere GPU,将性能提升 70-80%。因此,这样做意味着要多使用 70-80% 的功率。350W 然后变成 595–630W。Nvidia 可能会比线性扩展稍微好一点,并且 600W 很可能是参考卡上的最大功率使用,但我们已经听说一些下一代第三方超频卡可能包括双 16 针电源连接器。
七
ADA会最终成为RTX 40-SERIES吗?
下一代Nvidia GPU将被称为什么仍然存在问题。我们建议 RTX 40 系列,坚持过去几代人建立的模式,但 Nvidia 总能改变一些事情。改变的一个潜在原因是:中国人不喜欢“四”,这在粤语和普通话中也意味着死亡。
这是一个足够好的理由来改变事情吗?也许不是。当然,这些年来我们已经看到很多显卡和其他型号为“4”的 PC 产品。英伟达在其 RTX 品牌上投入了大量资金,虽然如果每个人都准确地猜出下一系列 GPU 的名称可能不会那么令人兴奋,但销量才是最重要的。
无论最终调用 Ada 显卡,都不会改变它们的性能或功能。我们中的大多数人有理由相信 Nvidia 将使用 RTX 40 系列名称,但如果 Nvidia 做出改变,这并不是世界末日。
简短的答案,也是真正的答案是,它们的成本将与 Nvidia 可以摆脱的收费一样多。Nvidia 推出 Ampere 时采用了一套财务模型,但事实证明,这些模型在 Covid-19 大流行时代是完全错误的。现实世界的价格飙升,黄牛从中牟取暴利,而那是在加密货币矿工开始支付官方推荐价格的两到三倍之前。即使是现在,我们仍然看到 30% 或更多的加价。好消息是GPU 价格正在下降。
Ada 和 RTX 40 系列的 GPU 价格很可能会上涨。然而,假设的大型 L2 缓存和内存带宽的相对有限增加应该导致 Ada 仅在 Ampere 的采矿性能方面提供适度的提升,就像 AMD 的 RDNA 2 卡仅比 RDNA 模型快一点一样。这意味着,即使在 Ada 到来之前采矿盈利能力“恢复”,单靠采矿几乎肯定无法维持我们从 2020 年底到 2022 年初看到的大幅上涨的价格。
正如我们将在下一节中讨论的那样,Nvidia 也没有理由立即将其所有 GPU 生产从 Ampere 转移到 Ada。我们可能会看到 RTX 30 系列 GPU 仍在生产相当长一段时间,特别是因为没有其他 GPU 或 CPU 竞争三星 Foundry 的 8N 制造。Nvidia 首先推出高端 Ada 卡,利用其可以从台积电获得的所有可用容量,并在必要时降低现有 RTX 30 卡的价格以填补任何漏洞,从而获得更多收益。
我们多次提到了 9 月推出 Ada 和 RTX 40 系列 GPU 的时间表,但重要的是要记住,第一批 Ada 卡只是冰山一角。英伟达于 2020 年 9 月推出了 RTX 3080 和 RTX 3090,一个月后 RTX 3070 到货,再过一个月后 RTX 3060 Ti 到货。RTX 3060 直到 2021 年 2 月下旬才问世,然后 Nvidia 在 2021 年 6 月用 RTX 3080 Ti 和 RTX 3070 Ti 更新了该系列。预算友好的 RTX 3050 直到 2022 年 1 月才到货,最后是 RTX 3090 Ti 刚刚于 2022 年 3 月下旬推出。
我们预计 Ada 卡也将分阶段推出,从最快的型号开始逐步进入高端和主流产品,以预算为导向的 AD106 和 AD107 最早可能要到 2023 年才会推出。正如我们刚刚提到的,RTX 3050 仅在 1 月下旬推出,因此至少再过一年甚至更长的时间都不会更换。再说一次,我们仍然需要真正的预算产品来接管 GTX 1660 和 GTX 1650 系列。我们能否以低于 200 美元的价格获得新的 GTX 系列或真正的预算 RTX 卡?这是可能的,但不要指望它,因为 Nvidia 似乎满足于让 AMD 和英特尔在 200 美元以下的范围内与之抗衡。
在首次发布大约一年后,不可避免地会更新 Ada 产品。在这个阶段,任何人都猜测这些最终是“Ti”模型还是“Super”模型或其他什么,但你几乎可以在你的日历上标记它。
八
GPU世界的更多竞争
几十年来,英伟达一直是显卡领域的主导者。它控制着整个 GPU 市场的大约 80% 到 90%,并且在很大程度上能够决定光线追踪和 DLSS 等新技术的创建和采用。然而,随着人工智能和计算对科学研究和其他计算工作负载的重要性不断增加,以及它们对类似 GPU 的处理器的依赖,许多其他公司都在寻求进入该行业,其中最主要的是英特尔。
自 90 年代后期以来,英特尔就没有在专用显卡上做出过适当的尝试,除非你算上流产的 Larrabee。这一次,Intel Arc 似乎是玩真的——或者至少是进了门。看起来英特尔更多地关注媒体功能,而在 Arc 的游戏或一般计算性能方面,陪审团仍然没有定论。据我们所知,顶级消费模型最多只能在 18 TFLOPS 范围内。看看我们在顶部的桌子,看起来它只会与 AD106 竞争。
但 Arc Alchemist 只是英特尔计划的常规 GPU 架构中的第一个。Battlemage 可以轻松地将 Alchemist 的能力翻倍,如果英特尔能够早日实现这一目标,它可能会开始蚕食 Nvidia 的市场份额,尤其是在游戏笔记本电脑领域。
AMD 也不会停滞不前,它已经多次表示它“有望”在今年年底之前推出其 RDNA 3 架构。我们预计 AMD 将转向台积电的 N5 节点,这意味着它可能会直接与 Nvidia 竞争晶圆,并且两者都必须做出类似的设计决策。到目前为止,AMD 一直避免将任何形式的深度学习硬件放入其消费级 GPU(与其 MI200 系列不同),但由于 Arc 还包括 Xe Matrix 内核,它可能需要重新考虑这种方法。
毫无疑问,Nvidia 目前提供的光线追踪性能远远优于 AMD 的 RX 6000 系列卡,但 AMD 对光线追踪硬件或游戏中对 RT 效果的需求几乎没有直言不讳。就英特尔而言,它的 RT 性能似乎比 AMD 还要低。但只要大多数游戏在没有 RT 效果的情况下继续运行得更快并且看起来不错,那么说服人们升级显卡就是一场艰苦的战斗。
长达两年的 GPU 干旱和价格过高的显卡已经过去了。2022 年将成为自 2020 年以来 GPU 领域的第一次真正激动人心的时刻。希望这一轮能够看到更好的可用性和定价。它几乎不会比我们过去 18 个月看到的情况更糟。
参考链接:
https://wccftech.com/nvidia-flagship-ada-lovelace-gpu-18176-cores-48-gb-memory-24-gbps-speeds-800w-tbp-rumor/
https://www.tomshardware.com/features/nvidia-ada-lovelace-and-geforce-rtx-40-series-everything-we-know
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3112内容,欢迎关注。
推荐阅读
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
晶圆|集成电路|设备 |汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!





-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号