
适用于1nm的晶体管
来源:内容由 半导体行业观察(ID:i cbank)编译自allaboutcircuits, 谢谢。
imec 研究人员发现了有关“complementary FET”的新发现,这是一种适用于 1 nm 逻辑技术节点及以上节点的有吸引力的器件架构。
在 forksheet 场效应晶体管 (FET) 中,nFET 和 pFET 被集成到相同的结构中,并由绝缘壁(dielectric wall)隔开。这种方法导致金属间距窄至 16 nm,这对于具有低轨道高度的高性能单元设计来说太低了。
imec 研究人员在其2022 年 VLSI 论文中强调了这一挑战,介绍了一种complementary FET (CFET) 架构。他们还报告了改进的工艺流程如何使顺序 CFET 比单片 CFET 更有前景。值得注意的是,该团队认为这种forksheet器件架构可能会将纳米片晶体管系列的可扩展性扩展到 1 nm 及以上的逻辑节点。

从 FinFET 到 nanosheet 到 forksheet 再到 CFET 的演变
从平面 FET 到 FinFET 的过渡
由于从平面 FET 过渡到 FinFET,晶体管尺寸减小了,而性能却提高了。这种转变是必要的,因为平面 FET 的性能在栅极长度减小时开始下降。FinFET 有助于维持扩展路径。
在 FinFET 中,源极和漏极之间的沟道是 Fin 的形式。栅极缠绕在这个沟道周围,从通道的三个侧面施加控制。这种方法消除了平面 FET 遭受的短沟道效应。此外,更高的鳍片高度允许在相同区域内更高的器件驱动电流。
然而,随着技术规模超过 5 nm,Fin 结构无法提供足够的静电控制。
imec 的扩展障碍解决方案:Forksheet 架构
为了实现进一步的缩放,imec 引入了一种垂直堆叠的纳米片结构,其中栅极完全包裹在沟道周围。据说这种架构提供了卓越的控制和更好的三维体积分布。
Forksheet 器件是垂直堆叠纳米片的延伸。在这里,纳米片由三栅极叉形结构控制,这是通过在 p 和 nFET 器件之间引入介电壁来实现的。隔离允许更紧密的 n 到 p 间距和更高的性能。隔离还将标准单元的轨道高度扩展到 4T,这意味着四个单元内金属线可以适应标准单元高度的范围。
然而,金属间距的 n 区和 p 区之间的间距低至 16 nm,这对于 4T 轨道高度单元设计来说太窄了。为了最大化沟道宽度和驱动电流,imec 研究人员提出了 CFET 架构。
单片与顺序
(Monolithic vs. Sequential)CFET
研究人员探索了两种可能的集成方案来实现垂直堆叠:单片和顺序。在 CFET 架构中,n 和 p 器件垂直堆叠在一起,消除了标准单元高度的 np 间距。

纳米片、叉片 (FS) 和 CFET(单片和顺序)的栅极横截面
单片 CFET 流发生在三个部分:底部通道的外延生长、中间层的沉积以及顶部通道的外延生长。这种流程比顺序流程更复杂,因为它会产生高纵横比 (HAR) 垂直结构,需要进一步的图案化。
在顺序制造流程中,底部器件被加工到触点。然后,使用晶圆对晶圆键合技术在其顶部创建一个覆盖半导体层。最后,集成顶层设备。这个过程更简单,因为可以以二维方式单独处理顶级设备。

3D 顺序堆叠设备
这些过程中的每一个都有其优点和缺点。在 2022 年 VLSI 论文中,imec 研究人员提出了 4T 标准单元设计中单片 CFET 与顺序 CFET 的功率性能面积成本 (PPAC) 评估。他们还评估了顺序 CFET 的不同层转移工艺。
从理论到实施
imec 报告说,从成本的角度来看,半导体制造商 SOITEC 提供了一种很有前途的层转移工艺——一种依赖于低温“智能切割”流程的工艺。它使用在低温下分裂的工程体供体晶圆。研究人员发现,在概念验证层转移后处理的顶层设备从降低的电气性能中恢复。

SOITEC 低温智能切割层传输流程示意图
imec 逻辑 CMOS 微缩计划主管 Naoto Horiguchi 强调,虽然这种架构是真正的 CFET 架构,但它不是真正的 CFET 实现,因为底部器件中没有金属互连层。
他指出,imec 的测试工具展示了“改进的层传输作为顺序 CFET 和其他 3D 顺序堆叠实现的关键模块”。在未来的研究中,imec 报告说,研究人员将致力于实现真正的顺序 CFET。
1nm的关键技术,IMEC公布新进展
20 多年来,Cu 双镶嵌(dual-damascene)一直是构建可靠互连的主要工艺流程。
但是,当尺寸继续缩小并且金属间距(metal pitches)变得像 20nm 及以下那样紧密时,由于电阻电容 (RC) 产品的急剧增长,后端 (BEOL) 越来越受到 RC 延迟的影响。
这个问题迫使互连行业寻找替代集成方案和在紧密金属间距下具有更好品质因数的金属。
大约五年前,imec 最初提出半镶嵌(semi-damascene )作为铜双镶嵌的可行替代方案,用于集成 1nm(及以上)技术节点的最关键的局部 (Mx) 互连层。

图 1 – Imec 的半镶嵌流程:a) Ru 蚀刻(底部局部互连线 (Mx) 的形成);b) 填空;c) 通过蚀刻;d) 通过填充和顶线 (Mx+1) 形成(如 VLSI 2022 所示)。
与双镶嵌不同,半镶嵌集成依赖于互连金属的直接图案化来制作线条(称为减材金属化(subtractive metallization)),并且不需要金属的化学机械抛光 (CMP) 来完成工艺流程。连接后续互连层的通孔以单镶嵌方式(single-damascene fashion)图案化,然后用金属填充并过度填充( then filled with metal and overfilled)——这意味着金属沉积会继续进行,直到在电介质上形成一层金属。然后对该金属层进行掩膜和蚀刻(masked and etched)以形成具有正交线(orthogonal line)的第二互连层。
在金属图案化之后,线之间的间隙可以用电介质填充或用于在局部层处形成(部分)气隙。请注意,在半镶嵌流程中,一次性形成两层(通孔和顶部金属),就像传统的双镶嵌一样。当以双镶嵌进行基准测试时,这使其具有有效的成本竞争力(见图 2)。

图 2 - 18nm 金属间距下半镶嵌和双镶嵌成本的比较。
半镶嵌集成流程的好处
与铜双镶嵌相比,半镶嵌在紧密的金属间距下具有多项优势。Imec研究员兼 imec 纳米互连项目总监Zsolt Tokei 表示:“首先,它允许更高的线路纵横比,同时保持电容受到控制——有望带来整体 RC 优势。其次,没有金属 CMP 步骤导致更简化和成本效益更高的集成方案。
最后,半镶嵌集成需要无屏障(barrierless)、可图案化的金属,例如钨 (W)、钼 (Mo) 或钌 (Ru)。通过使用与铜不同,不需要金属阻挡层的金属,宝贵的导电区域可以被互连金属本身充分利用,从而确保在缩放尺寸上具有竞争力的通孔电阻。” 当然,除了好处之外,在这样的计划获得工业认可之前,还有许多挑战需要解决。朝这个方向迈出的一步是实际演示双金属级方案。虽然仅通过仿真和建模显示了这些好处,但 imec 首次为双金属级半镶嵌模块提供了实验证据。
完全自对准的通孔——一个关键的构建块
在小至 20nm 的金属间距下,控制通孔降落在窄线上是半镶嵌集成模块成功运行的关键。当通孔和线路(在通孔顶部和底部)没有正确对齐时,通孔和相邻线路之间存在泄漏的风险。这些泄漏路径是由小通孔的常规图案化引起的过大覆盖误差造成的。
imec 技术人员的主要成员Gayle Murdoch说:“找到一种方法来制作功能性、完全自对准的通孔一直是半镶嵌工艺的圣杯。
我们通过 imec 的集成、光刻、蚀刻和清洁团队之间的密切合作实现了这一里程碑。通过我们完全自对准的集成方案,我们补偿了高达 5nm 的重叠误差——这是一项关键成就。”

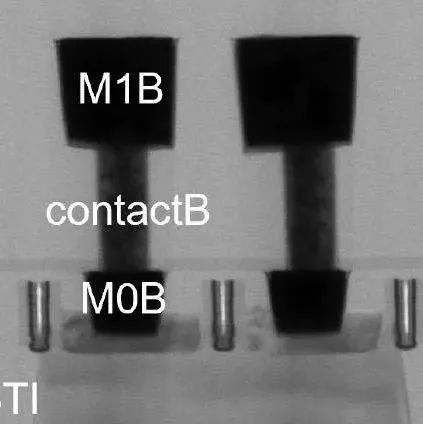
图 3 – 沿 Mx(左)和跨 Mx(右)的自对准通孔。X-TEM 显示自对准通孔落在 18nm 间距 Ru 线上(如 VLSI 2022 所示)。
通过在间隙填充后选择性去除氮化硅来确保底部自对准,从而允许在下部金属线的范围内形成通孔。朝向顶部金属层 (Ru) 的自对准是通过 Ru 过度蚀刻步骤实现的,该步骤在通孔过度填充和 Ru 图案化之后应用。
18nm 间距的良好电阻和可靠性——首次演示
使用具有完全自对准通孔的 Ru 减法蚀刻产生了 18nm 金属间距的功能性双金属级器件。结合自对准双重图案化 (SADP) 的 EUV 光刻用于图案化 9nm“宽”Ru 底部局部互连线 (Mx),而单次曝光 EUV 光刻用于印刷顶线 (Mx+1) 和通孔. 顶部金属与气隙相结合以抵消电容增加。
在将 Ru 与 Cu 的线路电阻与导电面积进行基准比较时,Ru 在目标金属间距方面明显优于 Cu。通过自对准在形态学和电学上都得到了证实。实现了出色的通孔电阻(26-18nm 金属间距的范围在 40 和 60Ω 之间),并且证明了 >9MV/cm 的通孔到线击穿场。
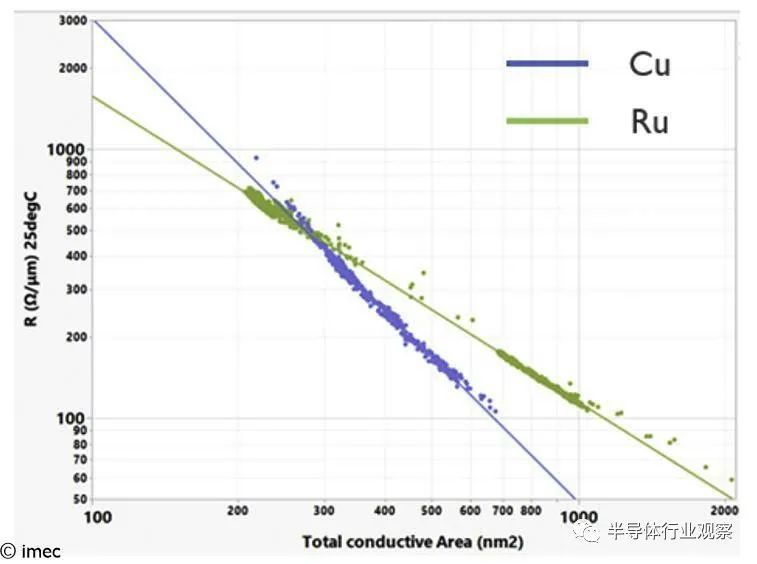
图 4 – Ru 和 Cu 线的导电面积与线电阻的关系(如 VLSI 2022 所示)。
Zsolt Tokei:“我们展示了所有关键技术参数的卓越价值,包括通孔和线路电阻和可靠性。该演示表明,半镶嵌是双镶嵌的一种有价值的替代方案,用于集成 1nm 技术节点及以后的前三个局部互连层。我们的具有完全自对准通孔的双金属层器件已被证明是关键的构建模块。”
我们的演示表明,半镶嵌是双镶嵌的一种有价值的替代方案,用于集成 1nm 技术节点及以后的前三个局部互连层。
通过增加线路的纵横比(降低电阻)同时保持气隙(控制电容),可以进一步改进。同时,imec 对使用半镶嵌技术(允许在标准单元级别进一步减少面积)实施中线 (MOL) 和 BEOL 技术增强器有具体的想法。
Intel眼里的下一代晶体管,GAA的继任者!
在近期举办的VLSI 技术和电路研讨会上,专家们深入探讨了最近的技术进步,并展望了将在不久的将来过渡到生产的研究工作。其中,来自英特尔组件研究小组的 Marko Radosavljevic 在题为“Advanced Logic Scaling Using Monolithic 3D Integration”的演讲中提供了有关 3D 设备制造开发状态的最新信息。
尽管仍有重大挑战有待解决,但 Marko 提供了一个令人信服的观点,即 3D 器件拓扑将成为新兴的环栅(纳米片/纳米带)器件的继任者。
本文总结了 Marko 演讲的亮点。
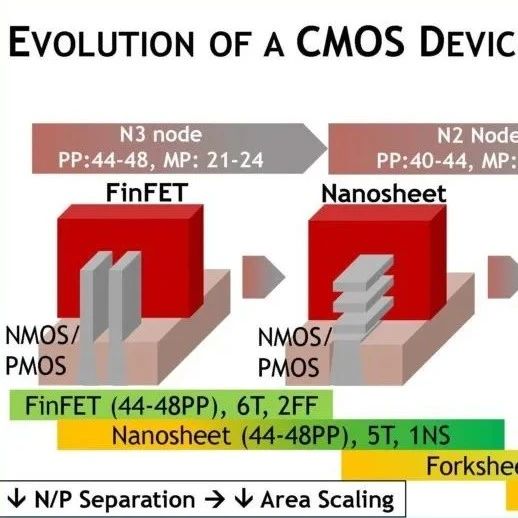
Marko 首先简要回顾了导致当前 FinFET 器件和即将推出的 GAA 拓扑的最新工艺技术发展。下面的第一张图列出了这些器件缩放特性,而下一张图显示了 FinFET 和 GAA 器件堆栈的横截面图。(图中显示了四个垂直纳米片,用于相邻的 nFET 和 pFET 器件。)

与 FinFET 的“三栅极”表面相比,GAA 拓扑改进了器件漏电流控制。(通常会集成额外的制程工程步骤,以减少最低纳米片底部和衬底之间的器件栅极材料的衬底表面泄漏电流。)
此外,如下图所示,GAA 光刻和制造在堆叠中纳米片的宽度方面提供了一些灵活性。与 FinFET 器件的量化宽度 (w=(2*h)+t) 不同,设计人员在针对特定 PPA 目标优化电路方面将具有更大的灵活性。
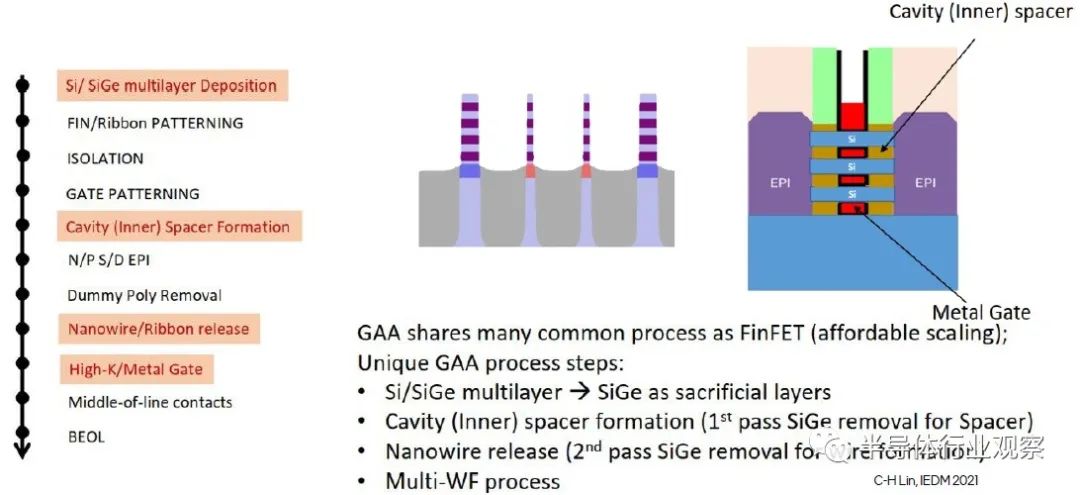
上图还强调了一些 GAA 工艺挑战,特别是与 FinFET 制造相比独特的步骤:
-
初始 Si/SiGe 外延叠层
-
牺牲(sacrificial)SiGe的部分凹陷蚀刻,暴露Si层的末端以用于源极/漏极节点的外延生长
FinFET 还使用选择性外延来扩展 S/D 节点——然而,鳍片已经暴露在栅极的任一侧。GAA 器件需要对散布的 SiGe 层进行非常精确的横向蚀刻,以在 S/D 外延之前暴露 Si 表面。
-
去除剩余的牺牲(sacrificial) SiGe 以“释放”纳米片表面(由 S/D Epi 支持)
-
在所有纳米片表面上精确沉积栅极氧化物和周围的栅极金属
请注意,在上图中,将沉积多种金属栅极成分,以针对不同的器件 Vt 阈值提供不同的功函数表面电位。
3D 设备
在此背景下,Marko 分享了下图,表明下一个工艺路线图器件演变将是 3D 堆叠纳米带,利用在横向 pFET 和 nFET 器件制造中获得的工艺开发经验。3D 堆叠器件通常表示为“CFET”(complementary FET)结构。
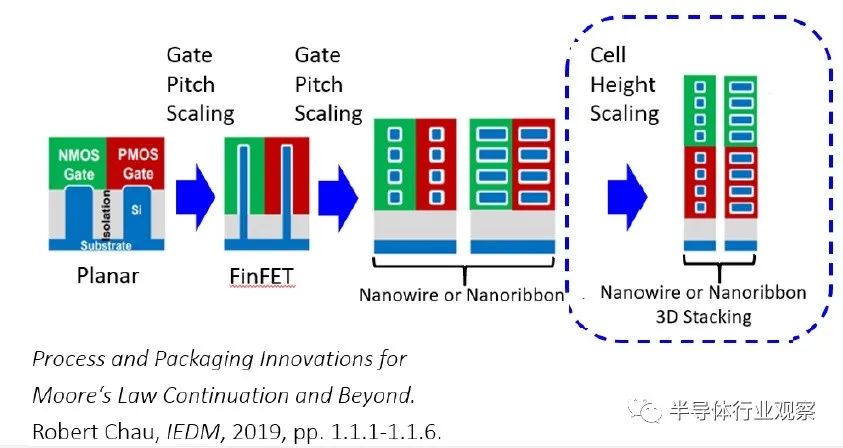
下图说明了与横向纳米片布局相比,垂直器件堆叠能够给逻辑单元和 SRAM 带来显著的微缩(a 1-1-1 device configuration for the transfer gate-pullup-pulldown in the 6T cell)。
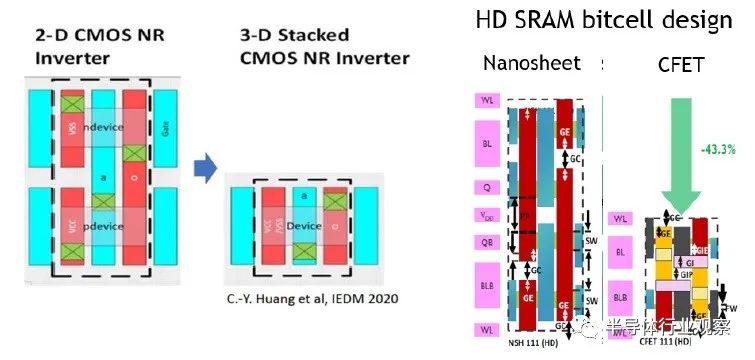
下图扩展了上面的逻辑反相器(logic inverter)布局,以横截面显示器件。注意为器件提供 VDD 和 VSS 的埋入式电源轨 (BPR)。此外,请注意接触蚀刻和金属填充所需的重要纵横比。

CFET 研发计划
实际上,有两种非常不同的 CFET 器件制造方法正在评估中——“顺序”(sequential)和“单片”(monolithic,或自对准)。
1.顺序 3D 堆叠
下图说明了顺序处理流程。首先制造底部器件,然后粘合(变薄的)衬底以制造顶部器件。氧化物介电层沉积并抛光在起始衬底上,用于键合工艺,并用作器件之间的电隔离。底部器件的存在限制了可用于顶部器件制造的热预算。
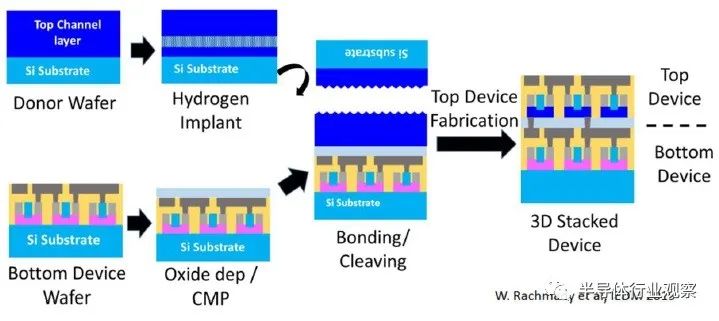
研究人员特别感兴趣的是,这种方法为两种器件类型提供了利用不同衬底材料(以及可能不同的器件拓扑)的机会。例如,下图显示了一个(顶部)pFET,它使用 Ge 衬底中的纳米片器件制造,(底部)nFET 使用 FinFET 结构。

在上面的示例中,Ge 纳米片中的 pFET 将使用 Ge/SiGe 层的起始堆叠制造,SiGe 再次用作源极/漏极生长和纳米片释放的牺牲支撑。与 Si 相比,该技术选项将利用 Ge 中更高的空穴迁移率。
分隔两个器件层的键合电介质厚度是一个关键的工艺优化参数——薄层可降低寄生互连电阻和电容,但需要无缺陷。
2.自对准单片 3D 堆叠
下图显示了单片自对准 CFET 结构的横截面,以及高级工艺流程描述。(中间的 SiGe 层是牺牲的。)

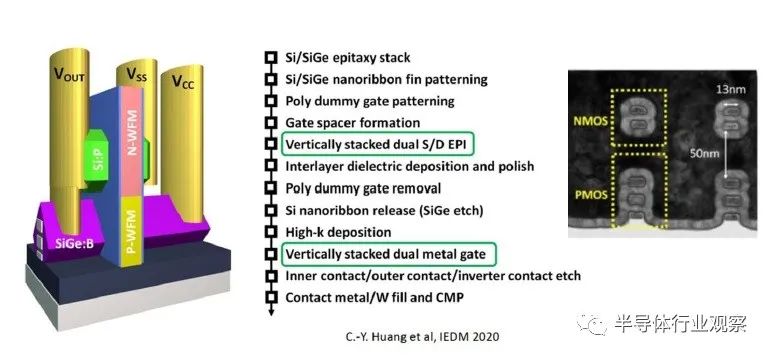
上图中突出显示的单片垂直器件结构独有的两个关键工艺步骤是不同的 nFET 和 pFET S/D 外延生长和栅极功函数金属沉积。
下图说明了两种器件类型的 S/D 外延生长过程。顶部器件纳米带在底部器件 S/D 外延生长之前接收阻挡层。然后,去除该阻挡层,露出顶部纳米带的末端,并生长顶部器件 S/D 外延。该图还包括确认 p-epi 和 n-epi 区域没有从其他外延生长步骤接收掺杂剂。

下图描述了栅极金属沉积的顺序。随后去除最初沉积在两种器件类型上的金属,用于随后沉积用于第二(顶部)nFET的不同功函数栅极金属。

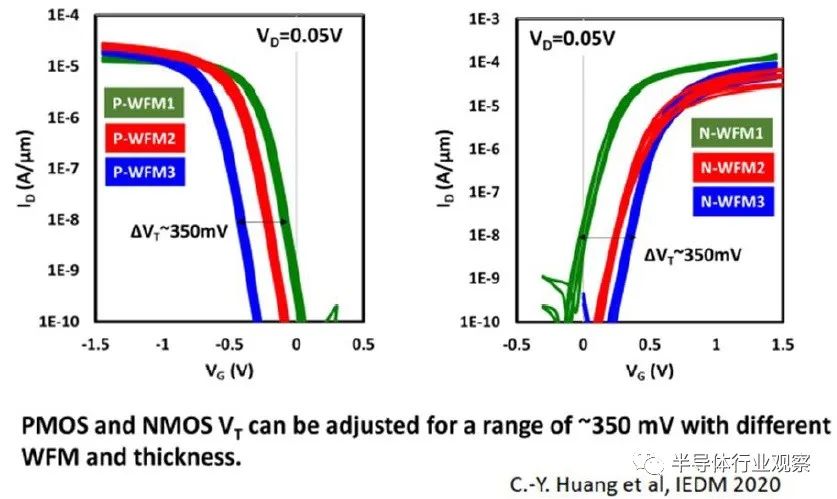
说明单片 nFET 和 pFET 的多个 Vt 器件特性范围的实验数据如下所示。
尽管 CFET 器件技术有望在即将到来的纳米带工艺节点上继续改进 PPA,但关键考虑因素将是 CFET 器件拓扑的最终成本。Marko 介绍了以下成本估算比较,这是与 IC Knowledge LLC 合作的一部分。类别细分为:光刻、沉积、蚀刻、CMP、计量和其他。请注意,CFET 示例包括 BPR 分布,为信号路由开辟了额外的单元轨道。导致顺序 CFET 成本差异的主要因素是晶圆键合和单独的顶部器件处理。
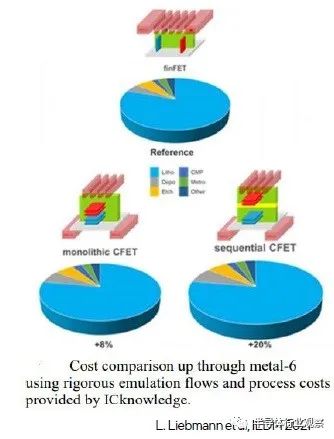
总的来说,CFET 制造的 PPAC 优势看起来很有吸引力,尽管总 CFET 工艺成本更高。(一个更具挑战性的权衡是使用不同衬底的顺序 CFET 器件制造所提供的灵活性是否会保证额外的成本。)
尽管工艺开发挑战仍有待解决,但 CFET 器件工艺路线图似乎是纳米带器件很快实现生产状态的自然延伸。
在最近的 VLSI 技术和电路研讨会上,英特尔展示了他们的研发结果和来自其他研究人员的实验数据,证明了 PPAC 的显着优势。FinFET 器件的寿命将通过七代工艺节点持续十多年,如下图所示。

迄今为止,纳米带设备的路线图(至少)描述了两个节点。
CFET 器件的优势和纳米带制造(以及建模和 EDA 基础设施)专业知识的利用可能会缩短纳米带的寿命。
★ 点击文末 【阅读原文】 ,可查看本文原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3103内容,欢迎关注。
推荐阅读
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
晶圆|集成电路|设备 |汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!

-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 东方晶源YieldBook 3.0 “BUFF叠满” DMS+YMS+MMS三大系统赋能集成电路良率管理
- 2 NVIDIA重磅出击:三台计算机助力人形机器人飞跃
- 3 奕行智能(EVAS Intelligence)完成数亿元A轮融资,加速推出RISC-V计算芯片产品,共同助力新时代到来
- 4 智能驾驶拐点将至,地平线:向上捅破天,向下扎深根
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号