
Arm发布新一代CPU,新系列GPU同时亮相
来源:内容来自 半 导体行业观察(ID:icbank)综合 ,谢谢。
Arm表示,公司在去年推出的第一代Armv9 CPU是一个里程碑式。这不仅是对于 Arm,更重要是对于我们扩展的生态系统。在Arm看来,Armv9 架构推动的进步将对科技行业和未来十年的计算产生持久的影响。
在近日,Arm正式对外发布其第二代基于 Armv9 的 CPU。其中包括Arm Cortex-X3和Arm Cortex-A715,以及Arm Cortex-A510和 DSU-110(DynamIQ 共享单元)的重要更新。新的 Armv9 CPU 和更新构成了Arm 新的全面计算解决方案 (TCS22)的基础。

Arm表示,新的 Armv9 CPU 展示了其对释放计算性能的承诺。新的 Cortex-X3 和 Cortex-A715 以及对 Cortex-A510 和 DSU-110 的升级都旨在突破峰值性能的极限并提供卓越的持续性能和效率。作为多功能 CPU 集群的一部分,Arm旨在通过在下一代消费设备上提供出色的用户体验来激励合作伙伴并吸引最终用户。
Cortex-X3:将 X 因素带入性能
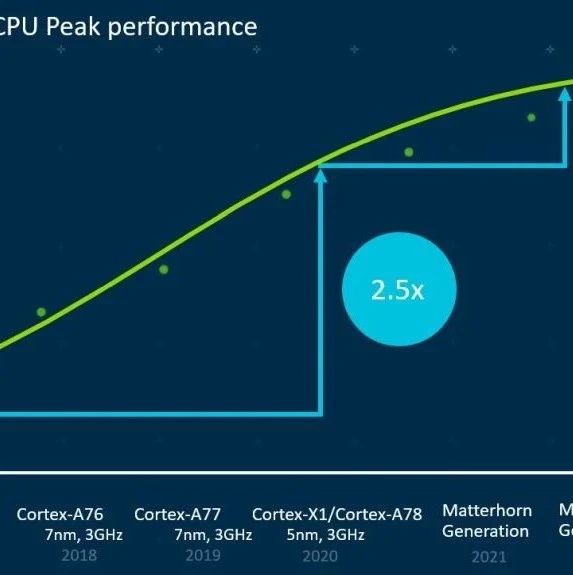
据Arm介绍,新的 Cortex-X3 是 Arm 的第三代 Cortex-X CPU。它是Cortex-X 定制计划的产物,允许参与的合作伙伴塑造最终产品设计。Cortex-X3 专为极致性能而设计,代表了 IPC 连续第三年实现两位数增长。这一强劲的 IPC 成绩能让 Android 旗舰智能手机和 Windows on Arm 笔记本电脑设备的性能领先地位。
Arm表示,Cortex-X3 针对一系列基准测试和应用程序,与最新的 Android 旗舰智能手机相比,其性能提高了 25%。

在笔记本电脑领域,与最新的主流笔记本电脑相比,Cortex-X3 的单线程性能提高了 34%。一致的性能和微架构改进为强大的 Cortex-X CPU 产品组合奠定了坚实的基础。
从Arm的介绍我们得知,全新的DSU 能在 Cortex-X3 上支持多达 12 个内核和 16M L3 缓存,可实现跨笔记本电脑和台式设备、移动设备、DTV 等设备的可扩展性。
据theregister报道,Arm 的 Cortex-X3 CPU 设计至少考虑了英特尔功能更强大的主流笔记本电脑处理器之一。这是Arm 在运行 SPECRate2017_int_base 单线程基准测试以模拟其 CPU 内核设计(时钟频率相当于 3.6GHz、1MB L2 和 16MB L3 缓存)后得出的结论。
他们指出,Arm 相信其 Cortex-X3 内核在运行通用应用程序代码时可以胜过 Core i7 的 P 内核。面向轻薄笔记本电脑的 28 瓦英特尔部件具有四个性能内核和八个效率内核,而基于 Arm 的竞争性现实世界片上系统(无论何时或如果有的话)将需要多个 Cortex 内核.
Arm 表示,X3 的进步部分归功于每时钟指令 (IPC) 比 X2 提高了 11%,这标志着 Cortex-X 系列的 IPC 连续第二年实现两位数增长。这使得 X3 成为 Arm 产品组合中“性能最高的 CPU”。然而,一旦我们考虑到转向即将到来的 3nm 制造工艺的预期收益,这一收益将扩大到 25%。Arm 预计该内核的性能将在笔记本电脑市场进一步扩展,与中端英特尔 i7-1260P 相比,性能提升高达 34%。不过,Cortex-X3 仍然不会赶上Apple 的 M1 和 M2,但希望缩小差距。

“这是关于最佳用户体验的,无论你的应用程序需要峰值性能还是用户响应时间非常关键,”Arm 中央工程组织的首席 CPU 架构师兼研究员 Chris Abernathy 在与记者的简报中说.
在进行微架构更改之前,X3 有几点值得注意。Arm 现在坚定地致力于其仅 64 位的路线图,因此 Cortex-X3 是仅 AArch64 的内核,就像其前身一样。Arm 表示,由于传统的 AArch32 支持已被删除,因此它专注于优化设计。重要的是,Cortex-X3 与 Cortex-X2 保持在同一版本的 Armv9 架构上,使其与现有内核的 ISA 兼容。
Cortex-X3 实现同比两位数的性能提升绝非易事,而 Arm 这次究竟是如何做到这一点的,归结为核心前端的大量工作。换句话说,Arm 已经优化了它如何让核心的执行单元有很多事情要做,从而使它们能够更好地发挥潜力。部分归功于 AArch64 指令的可预测性。
前端的细节包括改进的分支预测准确性和更低的延迟,这要归功于用于间接分支(带指针的分支)的新专用结构。分支目标缓冲区 (BTB) 已显著增长,受益于 Arm 分支预测算法的高精度。L1 BTB 缓存容量增加了 50%,L0 BTB 容量增加了 10 倍。后者允许核心在 BTB 经常出现的工作负载中实现性能提升。由于 BTB 的整体大小,Arm 还必须包含第三个 L2 缓存级别。
要理解这一变化,您需要注意 Arm 的分支预测器作为解耦指令预取运行,在内核的其余部分之前运行以最大程度地减少流水线停顿(bubbles)。这可能是具有大型代码库的工作负载的瓶颈,并且 Arm 希望最大限度地提高其面积占用的性能。增加 BTB 的大小,特别是在 L0 时,可以让更多正确的指令准备好填充指令提示,从而减少采用分支的气泡(bubbles)并最大限度地提高 CPU 性能。
为此,Arm 还扩展了获取深度,允许预测器提前获取更多指令以利用大型 BTB。同样,这也有助于减少指令管道中的停顿次数,因为 CPU 什么也不做。Arm 声称,总体结果是预测的分支平均延迟减少 12.2%,前端停顿减少 3%,每千个分支的错误预测减少 6%。
现在还有一个更小、更高效的微操作(解码指令)缓存。它现在比 X2 小 50%,回到与 X1 相同的 1.5K 条目,这要归功于减少抖动的改进填充算法。这种较小的 mop 缓存还允许 Arm 将总流水线深度从 10 个周期减少到 9 个周期,从而减少发生分支错误预测和刷新流水线时的惩罚。

Arm 计划通过其Total Compute Solutions计划提供 X3 设计,该计划提供一系列“专用”芯片设计配置,将各种技术结合在一起,包括其不断扩大的 GPU 设计组合。
继去年的 X2 之后,X3 的发布正值Arm希望通过硅合作伙伴在笔记本电脑领域获得更大的立足点,这些合作伙伴授权 Arm 的技术来制造与英特尔和 AMD 的基于 x86 的处理器竞争的芯片。除了笔记本电脑,Armv9 X3 还针对高端 Android 智能手机。
Cortex-A715:实现完美平衡的高效性能
Arm表示,对于 Cortex-A715,他们正在加倍关注 Cortex-A700 CPU 的关键价值主张——即终极高效性能。arm对 Cortex-A715 设计进行了一系列有针对性的改进,包括分支预测精度和数据预取。一致的 IPC 增益意味着 Cortex-A715 现在达到了与已有 2 年历史的 Arm Cortex-X1 CPU 性能相匹配的重要里程碑。
arm强调,Cortex-A715 为其合作伙伴提供了性能和效率的完美平衡。与Arm Cortex-A710 CPU (ISO 工艺)相比,这包括在相同性能下提高 20% 的能效,在相同功率下提高 5% 的性能。

这种对高效性能的推动使 Cortex-A715 成为 big.LITTLE CPU 集群的 CPU 集群主力。作为 TCS22 的一部分,CPU 可以与 Cortex-X3 和 Cortex-A510 CPU 内核配对。
正如Arm 所示,Cortex-A715 取代了上一代 Cortex-A710,继续提供比 X 系列更平衡的性能和能耗方法。不过,它仍然是一个繁重的内核,如上所述,Arm 表示 A715 在配备相同的时钟和缓存时提供与旧版 Cortex-X1 内核相同的性能。就像 Cortex-X3 一样,A715 的大部分改进都在前端。
与 A710 相比,更值得注意的变化之一是新内核仅为 64 位。由于没有 AArch32 指令,Arm 的指令解码器的大小与其前身相比缩小了 4 倍,所有这些解码器现在都可以处理 NEON、SVE2 和其他指令。总体而言,它们在面积、功率和执行方面的效率更高。

在 Arm 改进解码器时,它同时还把 i-cache从 4 通道切换到每周期 5 条指令,并将指令融合从 mop-cache 集成到 i-cache,两者都针对具有大容量的代码进行了优化指令操作。这样做的结果就是让mop-cache可以完全消失了。Arm 指出,它在实际工作负载中并没有那么频繁,因此并不是特别节能,尤其是在转向 5 宽解码时。移除 mop-cache 可降低整体功耗,使内核的能效提高 20%。
分支预测的准确性也得到了调整,方向预测能力翻了一番,同时改进了分支历史算法。结果是错误预测减少了 5%,这有助于提高执行核心的性能和效率。带宽已扩展,每个周期支持两个分支,支持条件分支和 3 阶段预测管道以减少延迟。
相关报道指出,Cortex-A715的执行核心与 A710 保持不变(也许是为什么 Arm 选择将名称增加 5,而不是 10?),这部分解释了这一代较小的性能提升。其余的更改在后端;有两倍多的数据缓存来增加 CPU 的并行读写能力,并产生更少的缓存冲突以提高电源效率。A715 L2 翻译后备缓冲区 (TLB) 现在具有 3 倍的页面文件范围,具有更多条目和针对连续页面的特殊优化,并且每个条目的翻译数量增加了 2 倍,从而提高了性能。Arm 还提高了现有数据预取引擎的准确性,减少了 DRAM 流量并有助于整体节能。
总而言之,Arm 的 Cortex-A715 是 A710 的更精简版本。放弃传统的 AArch32 ,并优化前端和后端会产生小的性能提升,但更大的收获是功率优化。作为大多数移动场景的主力,Cortex-A715 比以往任何时候都更高效——电池寿命的福音。然而,这也可能说明该设计可能已经完成,Arm 将需要进行更大的设计改革,以在下一次将中核性能提升一个档次。
Cortex-A510的效率升级
除了上述 CPU,arm还对去年推出的“LITTLE”Armv9 CPU Cortex-A510 进行了更新,该 CPU 主要为高效率而设计。arm表示,在该cpu上,他们保持了 2021 版本的性能,但提供了卓越的效率,这就使得其功耗降低了 5%。进而将公司的“LITTLE”CPU 内核的终极效率推向了全新的高度,更低的功耗意味着最终用户的电池寿命更长。

从相关报道可以看到,改进后的 A510 可将功耗降低多达 5%,同时改进时序,从而优化频率。作为替代品,明年的智能手机将在低功耗任务中更加高效。有趣的是,改进后的 A510 可以配置 AArch32 支持——原来只有 AArch64——这将该核心带入传统移动、物联网和其他市场。因此,就 Arm 的合作伙伴如何使用核心而言,它更加灵活一些。
报道指出,Arm 最新的动态共享单元 (DSU) 现在在单个集群中的支持性能获得了提升,例如其DSU 在 Cortex-X3 上支持多达 12 个内核和 16M L3 缓存,可实现跨笔记本电脑和台式设备、移动设备、DTV 等设备的可扩展性。

报道指出,与上一代相比,新更新的 DSU-110 支持的内核数量增加了 50%,同时支持最新的 ISA 功能。这些变化提高了我们合作伙伴的灵活性,并提供了资源来充分发挥我们 CPU 的潜力,从而改善用户体验。我们的合作伙伴现在可以针对具有新配置(例如 8 个 Cortex-X3 CPU 内核和 4 个 Cortex-A715 CPU 内核)的高端笔记本电脑设备,解锁新一代消费设备。

Arm表示,公司推出的big.LITTLE 技术于 2011 年首次推出,现已成为全球消费类设备(包括智能手机、笔记本电脑和 DTV)最常用的异构处理架构。然后,arm的DynamIQ 技术将大 CPU 和小 CPU 组合成一个完全集成的单一集群。big.LITTLE CPU 集群的灵活性非常适合多线程工作负载。该技术可以适应跨消费设备的动态使用模式,例如用于游戏和网页浏览的高处理强度,以及用于短信、电子邮件和音频的更长时间的低处理强度任务。
Arm同时强调,公司的 big.LITTLE 证明了其对计算的清晰愿景,并体现了 Arm 解决方案为我们的合作伙伴和更广泛的生态系统提供的灵活性。无论是计算密集型游戏还是低强度消息传递,big.LITTLE CPU 集群配置都能为用户提供最佳体验。
通过构建在 Armv9 安全功能的坚实基础上,arm希望能使开发人员能够创建最好、最安全的应用程序。通过将这些功能集成到硬件中,arm的 CPU 可提供卓越的安全性,而不会影响峰值性能或功率。
借助全新的 CPU,arm表示公司将继续突破专业处理的界限。这些最新的 CPU 集群也可在广泛的下一代设备中实现多种功率、性能和面积矢量的可扩展性。多功能且功能强大的 Armv9 CPU 集群可为未来十年提供计算能力,并支持 Arm 的下一代创新。
支持光追的GPU,释放游戏性能
在发布全新CPU的同时,Arm还带来了新一代的CPU。
Arm 也强调,公司每年都会发布面向移动市场的全新优质 GPU。然而,Arm今年决定更进一步,通过推出名为“Immortalis”的全新旗舰 GPU,确保最佳体验。这将其GPU 范围扩展到 Mali 之外,Mali 是迄今为止全球出货量最大的 GPU,已达到 80 亿个。
Immortalis 专为上市的最好的旗舰智能手机而设计,其设计的核心是卓越的游戏体验。Immortalis-G715 以最高性能和最佳图形功能提供终极游戏体验。其中一个功能是光线追踪,Immortalis-G715 是第一款在移动设备上提供基于硬件的光线追踪支持的 Arm GPU。
除了新的旗舰 GPU 之外,Arm还推出了新的高级Arm Mali-G715 GPU,它为移动设备带来了新的和更新的图形和 GPU 功能。其中包括用于显著节能和进一步提升游戏性能的可变速率着色,以及改进的执行引擎。高级系列中的第二款 GPU Arm Mali-G615 GPU - 提供相同的功能,但与 Mali-G715 的 7-9 个内核相比,内核数量为 6 个或更少。

按照Arm的说法,支持性能和效率是他们在移动设备上实现更多机器学习 (ML) 和智能的驱动力,而公司全新的 GPU 也的确提供了 2 倍的架构 ML 改进。GPU 可以更适合移动设备上的一系列 ML 工作负载,例如图像处理和精度灵活性,以获得更高级的用户体验。
首先看Immortalis-G715方面,据arm介绍,这是公司第一款提供专为移动设备设计的基于硬件的光线追踪支持的 Arm GPU。光线追踪是一种计算机图形技术,它通过对单个光线在场景周围的路径进行建模来生成逼真的光照和阴影。从本质上讲,这提供了更逼真的游戏体验。
挑战在于,光线追踪技术可以在整个移动 SoC 上使用大量的功率、能量和面积。然而,Immortalis-G715 上的光线追踪仅使用了 4% 的着色器核心区域,同时通过硬件加速实现了 300% 以上的性能提升。
arm同时谈到,公司去年的 Mali-G710 已经支持基于软件的光线追踪。联发科已经在其旗舰产品Dimensity 9000 芯片组中利用了这一功能,该芯片组已用于 OPPO 的 Find X5 Pro Dimensity 版本等旗舰智能手机。Immortalis-G715 中光线追踪的硬件加速将提升游戏性能,并为未来的旗舰智能手机带来更逼真和身临其境的体验。
Arm 认为,光线追踪代表了移动游戏内容的范式转变。我们决定现在在 Immortalis-G715 上引入基于硬件的光线追踪支持,因为我们的合作伙伴已经准备好,硬件已经准备好,并且开发者生态系统已经(即将)准备就绪。
当 Immortalis-G715 于 2023 年初出现在旗舰智能手机中时,我们认为这是生态系统开始探索其游戏内容的光线追踪技术的基础。随着未来几年技术的不断发展,这将有助于为在移动设备上全面过渡到光线追踪做好准备。
从相关报道可以看到,Arm 最新的 GPU 使用的其第四代 Valhall 图形架构,该架构在2019 年的 Mali-G77 上取代了前一代产品 Bifrost。Immortalis-G715、Mali-G715 和 Mali-G615 的核心是共享相同的图形 DNA。有一个改进的执行引擎,我们稍后会介绍它,以及对可变速率着色 (VRS) 的支持。VRS 可以通过解耦光栅化和着色频率将性能提高多达 40%。一些手机游戏现在已经支持可变速率着色有一段时间了,Arm 现在在这里达到了与高通的 Adreno GPU 相同的功能。
除了支持光线追踪之外,这些 GPU 之间唯一真正的区别是它们支持的核心数量和内存配置。因此,期待在旗舰 SoC 中看到 Immortalis,而 G715 和 G615 的性能点则略低。下表概述了设置的比较方式。

让我们回到改进后的执行引擎,Arm 称之为 Execution Engine Evolution。除了支持可变速率着色之外,还有一个经过调整的融合乘加 (FMA) 模块。现在,每个内核中的 FMA 单元数量增加了一倍,每个 FMA 中还有一个专用的乘法累加 (MMUL) 块。这使得 Arm 的最大计算能力翻了一番,尤其是对于机器学习工作负载,同时仅将核心的面积大小增加了 27%。每个引擎仍然有两个数据路径集群,因此每个内核有四个 FMA 单元。
Arm 在更广泛的着色器核心上进行了其他改进。高几何游戏的 Tiler 峰值三角形吞吐量为 3 倍,FP16 混合器吞吐量为 2 倍,用于多样本抗锯齿的新 FP16 硬件,以及细节级别案例的 2 倍纹理映射器速度。Arm 固定速率压缩 (AFRC) 首次出现在高级层中,之前已包含在通常更受内存带宽限制的低端内核中。现在还有一个软件可编程的 L2 哈希(32K x 32K 分辨率),为开发人员提供了更大的哈希算法选择灵活性。
这完全是针对实际工作负载优化图形内核的一个案例,允许 Arm 从其 Valhal 架构中获得更多的性能和效率,至少就其高级 Mali 内核而言。

Arm 的光线追踪单元 (RTU) 是直接内置在着色器核心中的可选附加组件,而不是外部加速器,这意味着性能会随着核心数量的增加而扩展。根据 Arm 的基准测试,微型 RTU 占用的着色器内核不到 4%,但提供的光线追踪性能比没有硬件加速的情况下高出 300% 以上。RTU 包含用于框和三角形边界框检测的专用加速单元,与标准 FMA 单元相比,大大加快了执行这些计算所需的时间。

值得注意的是,有不同程度的光线追踪支持。Arm 的实施并没有加速边界体积分层 (BVH) 处理,与游戏机中的支持相比,它是一种计算成本更高的光线追踪实施,但面积和功耗成本更小。因此,我们不应该期望视觉复杂性或帧速率接近高端空间,尽管考虑到移动与桌面层图形的功率、性能和面积限制,这总是有些意料之中的。
与其他实现一样,Arm 使用混合光栅化和线追踪方法。因此,预计可以从光线的使用中受益的对光、影和反射的更适度的增强,而不是对图形保真度的大修。
最后但并非最不重要的一点是,Arm 正在为开发人员提供更多服务。arm的新 GPU 得到广泛而全面的开发人员资源和工具集的支持,可优化所有移动游戏应用程序的性能和效率。

★ 点击文末 【阅读原文】 ,可查看本文原文链接!
今天是《半导体行业观察》为您分享的第3085内容,欢迎关注。
推荐阅读
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
晶圆|集成电路|设备 |汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!





-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号