
全球首款RISC-V 3D GPU即将亮相
来源:内容由 半 导体行业观察(ID:icbank) 编译自design-reus ,谢谢。
据报道,超低功耗图形 IP 领导者 Think Silicon将在2022 年Embedded World上展示业界首款基于 RISC-V 的 GPU——NEOX™ G 系列和 A 系列。该公司还将推出 NEMA®|pico-VG,这是用于 MCU 驱动的 SoC 的 NEMA®|GPU 系列的最新产品,它支持丰富的矢量图形,并通过将 CPU 利用率降低高达 95% 来提高系统效率。
NEOX ™ G 系列和 A 系列——智能 GPU 架构的新时代
NEOX™| G(图形)和 A(深度学习加速器)系列 IP 代表了智能 GPU 架构的新时代,可编程计算着色器在实时操作系统 (RTOS) 上运行并由轻量级图形和机器学习框架提供支持。通过使用相同硬件模块的可配置编程库,可以轻松针对图形、机器学习、视觉/视频处理和通用计算工作负载定制大量多线程系统。新产品作为一个 GPU 平台,将在 32 位 SoC 中实现,解决无数应用,包括下一代智能手表、增强现实 (AR) 眼镜、用于监控和娱乐的视频,以及用于销售点的智能显示器/交互终端。
NEMA®|pico-VG – 适用于功率、尺寸和成本受限产品的高性能图形
Think Silicon 的新型 NEMA®|pico-VG GPU 是最新添加的高性能和超低功耗图形,适用于电池驱动、功率受限的产品中的显示器。多核、矢量和 2.5D 光栅图形 GPU 在 0.21 平方毫米的微小硅片区域内支持 90-500MHz、70 fps 和 800x600 分辨率的时钟频率。在单个 IP 解决方案中结合硬件加速的矢量和光栅图形,使开发人员可以根据所显示的图形内容自由和灵活地选择最佳渲染技术。NEMA®|pico-VG 使用智能压缩算法来有效管理宝贵的内存空间,与纯软件解决方案相比,CPU 使用率最多可降低 95%。RTL 硬件模块和软件的结合使 NEMA®|pico-VG 成为智能手表、健身/GPS 追踪器和智能家居设备等功率、尺寸和成本受限产品中理想的高性能图形子系统。NEMA®|pico-VG 生产就绪型 RTL 预计将于 2022 年第四季度开始向客户发货。
“推出首款基于 RISC-V 的 GPU 是图形行业和 Think Silicon 的一个重要里程碑,”Think Silicon 的 IP 许可、销售和营销总监 Ulli Mueller 说。“我们的超低功耗、高性能图形解决方案旨在激发开发人员为各种产品和市场创造卓越的用户体验,同时显着降低能耗。我们期待在即将到来的嵌入式世界活动中展示我们的最新创新。”
在 Embedded World 上,Think Silicon 还将展出他们的 NEMA®|GUI-Builder,这是一种快速且易于学习的工具,使程序员能够通过使用拖放通用控件减少 SoC 平台 (MCU/MPU) 上的 GUI 开发时间和输入元素。NEMA®|GUI-Builder 通过利用 NEMA®|GPU 系列的强大 3D 功能,自动生成具有较小内存占用的功率和性能优化的 C 代码。NEMA®|GUI-Builder 包括 Think Silicon 的 NEMA®|GFX 软件 API 及其高效压缩技术 NEMA®|TSC,它也可以与非 Think Silicon GPU 一起使用。
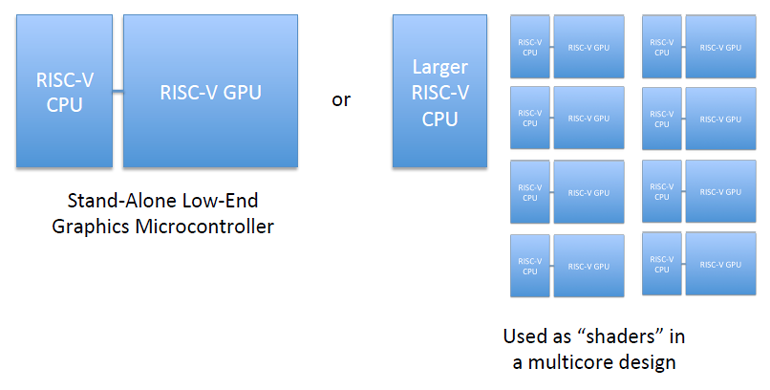
RISC-V能改变GPU吗?
RISC-V能处理GPU的事务吗?这项工作正在进行中,可以通过创建一个具有自定义可编程性和可扩展性的小型区域高效设计来实现这一目标。
-
GPU + RISC-V
-
这有点像VLIW(但不是真的)。
-
指令块之前带有寄存器标记,这些标记为该块内的标量指令提供了额外的上下文。
-
子块包括向量长度,旋转,向量/宽度覆盖和预测。
-
所有这些都添加到标量操作码中!
-
没有矢量操作码(也不需要任何操作码)。
-
在矢量上下文中,它是这样的:如果标量操作码使用寄存器,并且该寄存器在矢量上下文中列出,则将激活矢量模式。
-
激活会导致硬件级别的for循环发出多个连续的标量运算(而不只是一个)。
-
实现者可以自由地以他们想要的任何方式来实现循环-SIMD,多问题,单执行;几乎任何东西。
-
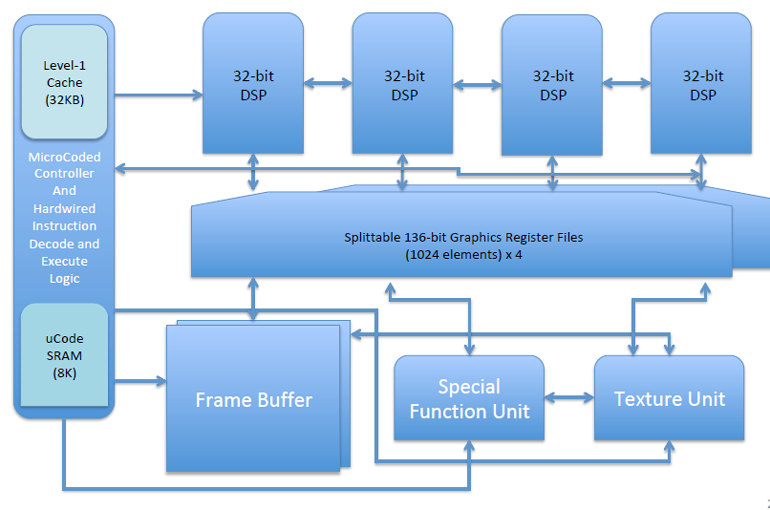
RV64X
-
指令/数据SRAM缓存(32 kB)
-
微码SRAM(8 kB)
-
双功能指令解码器(实现RV32V和X的硬连线;用于自定义ISA的微编码指令解码器)
-
四向量ALU(32位/ ALU-固定/浮动)
-
136位寄存器文件(1k个元素)
-
特殊功能单元
-
纹理单位
-
可配置的本地帧缓冲区
-
下一步是什么
★ 点击文末 【阅读原文】 ,可查看本文原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3072内容,欢迎关注。
推荐阅读
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
晶圆|集成电路|设备 |汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 东方晶源YieldBook 3.0 “BUFF叠满” DMS+YMS+MMS三大系统赋能集成电路良率管理
- 2 NVIDIA重磅出击:三台计算机助力人形机器人飞跃
- 3 奕行智能(EVAS Intelligence)完成数亿元A轮融资,加速推出RISC-V计算芯片产品,共同助力新时代到来
- 4 智能驾驶拐点将至,地平线:向上捅破天,向下扎深根
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号