来源:内容由半导体行业观察(ID:icbank)
编译自chipsandcheese
,
谢谢。
与 CPU 一样,现代 GPU 已经发展为使用复杂的多级缓存层次结构。集成 GPU (Integrated GPUs:iGPU
)也不例外。
事实上,它们是一种特殊情况
,因为它们与 CPU 内核共享一条内存总线。
iGPU 必须与 CPU 争夺有限的内存带宽,这使得缓存比专用 GPU 更加重要。
同时,集成 GPU 的集成特性提供了许多有趣的缓存设计选项。我们将看看 AMD、Intel 和 Apple 所采取的路径。
GPU 被赋予了很多明确的并行性,因此内存延迟并不像 CPU 那样重要。尽管如此,延迟仍然可以发挥作用。GPU 通常不会满负荷运行——也就是说,它们跟踪的并行工作量没有最大化。
测试延迟也是探测缓存设置的好方法。使用带宽做到这一点并不那么简单,因为请求可以在内存层次结构中的各个级别组合,并且要在缓存级别之间获得干净的中断可能会非常困难。
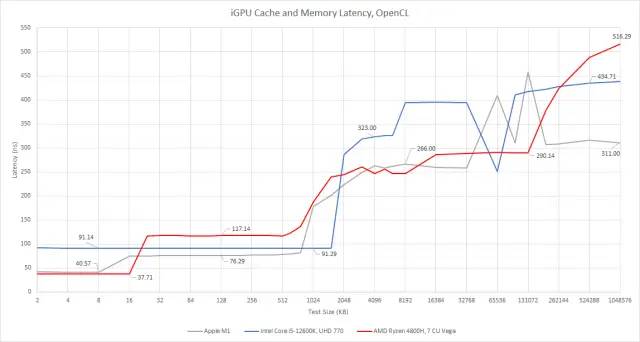
Ryzen 4800H 的缓存层次结构正是您对 AMD 著名的 GCN 图形架构所期望的。4800H 的七个基于 GCN 的 CU 中的每一个都有一个快速的 16 KB L1 缓存。然后,所有 CU 共享更大的 1 MB L2。AMD 处理内存总线限制的策略看起来很简单:使用比离散 GPU 更高的 L2 容量与计算比率。完全启用的 Renoir iGPU 有 8 个 CU,每个 CU 提供 128 KB。将此与 AMD 的 Vega 64 进行对比,其中 4 MB 的 L2 使其每个 CU 为 64 KB。
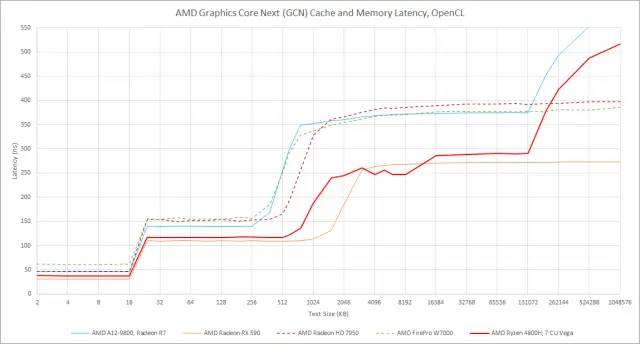 GCN 具有 16 KB L1 的简单两级缓存层次结构可立即识别出跨代和外形尺寸。
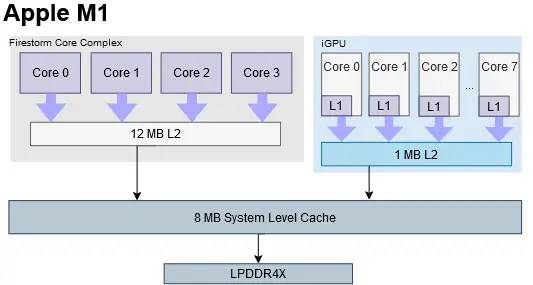
Apple 的缓存设置类似,快速的 L1 和 1 MB 的大 L2。Apple 的 L1 大小为 AMD 的一半,大小为 8 KB,但延迟相似。这种低延迟表明它被放置在 iGPU 内核中,尽管我们没有测试来直接验证这一点。与 AMD 相比,Apple 的 L2 延迟要低一些,这应该有助于弥补较小的 L1。我们还希望看到 8 MB SLC,但这并没有真正出现在延迟测试中。它可能是稍低的延迟区域,最高可达 32 MB。
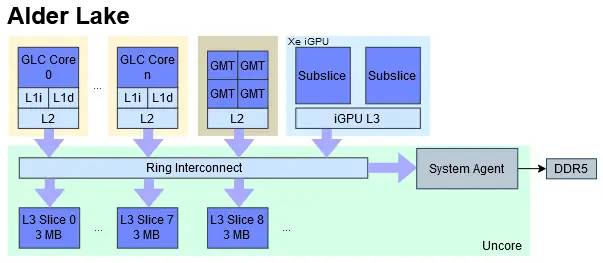
然后,看看英特尔的设计。与 AMD 和 Apple 相比,英特尔倾向于使用不太传统的缓存设置。这就是他们提供了一个由所有 GPU 内核共享的大型缓存的原因。它的大小至少为 1.5 MB,比 AMD 和 Apple 的 GPU 级缓存还要大。在延迟方面,它介于 AMD 和 Apple 的 L2 缓存之间。这不是特别好,因为我们看不到它前面有更小、更快的缓存。但它的大尺寸应该有助于英特尔在 iGPU 块内保持更多的内存流量。英特尔应该在大型共享 iGPU 级缓存之前拥有
更小、可能更快的缓存。
但是我们无法通过测试看到它们。
与 Apple 一样,英特尔拥有一个大型共享芯片级缓存,在延迟图上很难发现。这很奇怪——我们的延迟测试清楚地显示了前几代英特尔集成显卡上的共享 L3。
GCN 具有 16 KB L1 的简单两级缓存层次结构可立即识别出跨代和外形尺寸。
Apple 的缓存设置类似,快速的 L1 和 1 MB 的大 L2。Apple 的 L1 大小为 AMD 的一半,大小为 8 KB,但延迟相似。这种低延迟表明它被放置在 iGPU 内核中,尽管我们没有测试来直接验证这一点。与 AMD 相比,Apple 的 L2 延迟要低一些,这应该有助于弥补较小的 L1。我们还希望看到 8 MB SLC,但这并没有真正出现在延迟测试中。它可能是稍低的延迟区域,最高可达 32 MB。
然后,看看英特尔的设计。与 AMD 和 Apple 相比,英特尔倾向于使用不太传统的缓存设置。这就是他们提供了一个由所有 GPU 内核共享的大型缓存的原因。它的大小至少为 1.5 MB,比 AMD 和 Apple 的 GPU 级缓存还要大。在延迟方面,它介于 AMD 和 Apple 的 L2 缓存之间。这不是特别好,因为我们看不到它前面有更小、更快的缓存。但它的大尺寸应该有助于英特尔在 iGPU 块内保持更多的内存流量。英特尔应该在大型共享 iGPU 级缓存之前拥有
更小、可能更快的缓存。
但是我们无法通过测试看到它们。
与 Apple 一样,英特尔拥有一个大型共享芯片级缓存,在延迟图上很难发现。这很奇怪——我们的延迟测试清楚地显示了前几代英特尔集成显卡上的共享 L3。
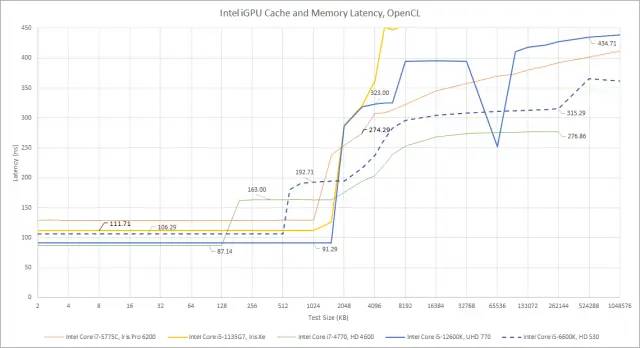 看起来共享芯片级 L3 在某些英特尔 iGPU 设计中对延迟没有太大帮助
从对延迟的第一眼看,我们已经可以很好地了解每个制造商如何处理缓存。现在让我们继续讨论带宽。
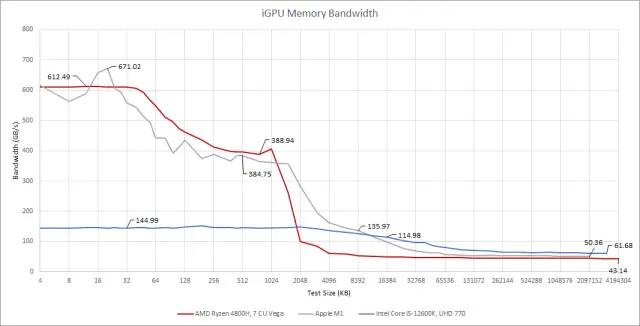
带宽对 GPU 来说比对 CPU 更重要。通常,CPU 只会在高度矢量化的工作负载中看到高带宽使用情况。但对于 GPU,所有工作负载本质上都是矢量化的。即使缓存命中率很高,也会出现带宽限制。
AMD 和 Apple 的 iGPU 私有缓存具有大致相当的带宽。英特尔的要低得多。部分原因是因为 Alder Lake 的集成显卡有一些不同的目标。比较 GPU 配置,这一点非常明显:
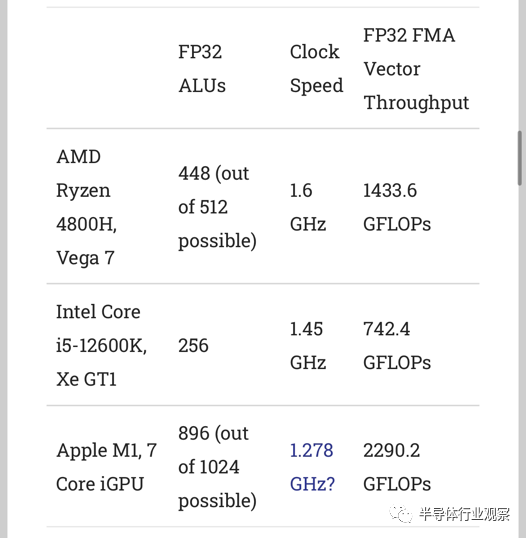
AMD 的 Renoir 和 Apple 的 M1 旨在为难以安装单独 GPU 的轻薄笔记本电脑提供低端游戏功能。但桌面 Alder Lake 肯定希望与独立的 GPU 配对用于游戏。可以理解的是,这意味着英特尔的 iGPU 在电源和芯片面积分配方面远远落后于优先级列表。较小的 iGPU 将具有较少的缓存带宽,因此让我们尝试通过使用向量 FP32 吞吐量来标准化 GPU 大小来平衡比较。
看起来共享芯片级 L3 在某些英特尔 iGPU 设计中对延迟没有太大帮助
从对延迟的第一眼看,我们已经可以很好地了解每个制造商如何处理缓存。现在让我们继续讨论带宽。
带宽对 GPU 来说比对 CPU 更重要。通常,CPU 只会在高度矢量化的工作负载中看到高带宽使用情况。但对于 GPU,所有工作负载本质上都是矢量化的。即使缓存命中率很高,也会出现带宽限制。
AMD 和 Apple 的 iGPU 私有缓存具有大致相当的带宽。英特尔的要低得多。部分原因是因为 Alder Lake 的集成显卡有一些不同的目标。比较 GPU 配置,这一点非常明显:
AMD 的 Renoir 和 Apple 的 M1 旨在为难以安装单独 GPU 的轻薄笔记本电脑提供低端游戏功能。但桌面 Alder Lake 肯定希望与独立的 GPU 配对用于游戏。可以理解的是,这意味着英特尔的 iGPU 在电源和芯片面积分配方面远远落后于优先级列表。较小的 iGPU 将具有较少的缓存带宽,因此让我们尝试通过使用向量 FP32 吞吐量来标准化 GPU 大小来平衡比较。
使用测量的带宽值。如果缓存级别不存在,则使用下一个缓存级别。GTX 1070 Max-Q 使用 Vulkan 进行了测试,因为 L1 不用于 OpenCL。即使使用 Vulkan,英特尔也没有显示出更快的缓存级别
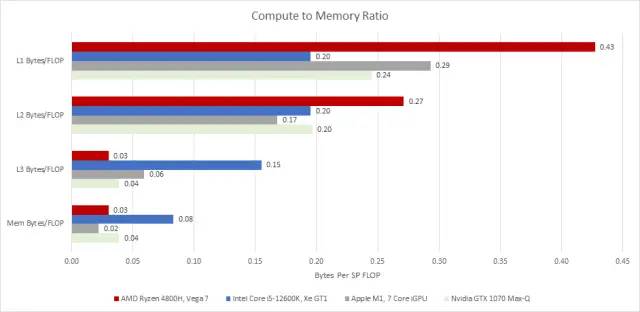
英特尔的缓存带宽现在看起来更好,至少如果我们从 L2 开始比较的话。每个 FLOP 的字节数大致与其他 iGPU 相当。它的共享芯片级 L3 看起来也很出色,主要是因为它的带宽对于这么小的 GPU 来说是超额配置的。
就缓存而言,AMD 是这场秀的明星。Renoir 的 Vega iGPU 享有比 Intel 或 Apple 更高的缓存带宽与计算比率(compute ratios)。但它的性能可能取决于缓存命中率(cache hitrate)。L2 未命中(misses
)直接进入内存,因为 AMD 后面没有另一个缓存。
Renoir 拥有所有 iGPU 中最弱的内存设置。
DDR4 可能既灵活又经济,但它并没有赢得任何带宽竞赛。
Apple 和 Intel 都拥有更强大的内存设置,并由大型片上缓存增强。
GPU 内存访问比在 CPU 上更复杂,在 CPU 上,程序访问单个内存池。在 GPU 上,有像 CPU 内存一样工作的全局内存。有恒定的内存,它是只读的。还有本地内存,它充当由一小组线程共享的快速暂存器。每个人对这个暂存器都有不同的名字。Intel 称之为 SLM(共享本地内存),Nvidia 称之为 Shared Memory,AMD 称之为 LDS(Local Data Share)。Apple 称之为 Tile Memory。为简单起见,我们将使用 OpenCL 术语,并将其称为本地内存。
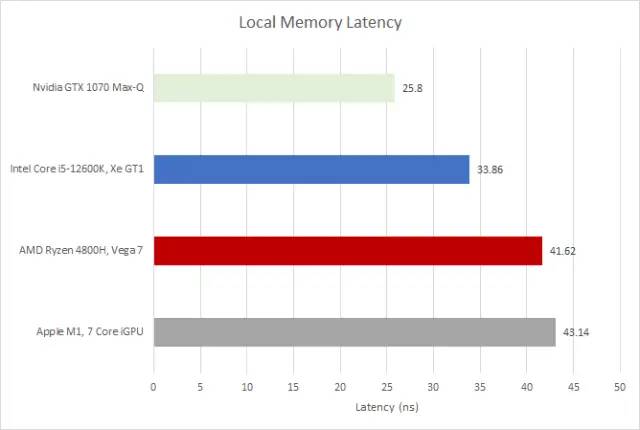 使用本地内存的Pointer chasing
使用本地内存的Pointer chasing
AMD 和 Apple 访问本地内存所需的时间与访问其一级缓存所需的时间差不多。当然,延迟并不是这里的全部。AMD 的每个 GCN CU 都有 64 KB 的 LDS——是其 L1D 缓存容量的四倍。本地内存的带宽也可能更高,尽管我们目前没有对此进行测试。M1 上的 Clinfo 显示 32 KB 的本地内存,因此 M1 至少有这么多可用。该数字可能仅表明一组线程的最大本地内存分配,因此硬件价值可能更高。
与此同时,英特尔享受对本地内存的快速访问,英伟达也是如此。在 Gen10 之前,英特尔将他们的 SLM 放在 iGPU 的 L3 上,在子切片之外(英特尔的 cloest 相当于 Apple 的 GPU 内核和 AMD 的 CU)。长期以来,这意味着英特尔 iGPU 的本地内存延迟不高。
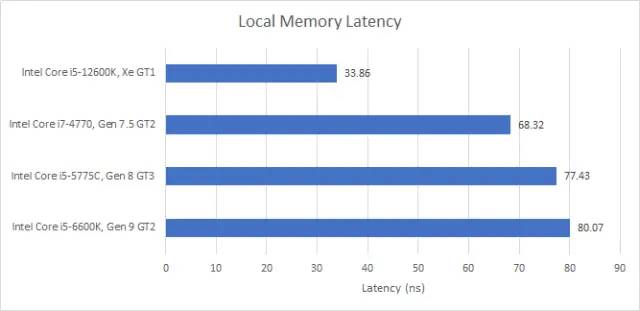 表现不错的英特尔
从第 11 代开始,英特尔将 SLM 移到了子片中(subslice),使本地内存配置类似于 AMD 和 Nvidia 的。Apple 可能也会这样做(在 iGPU 内核中放置“tile memory”),因为 Apple iGPU 上的本地内存延迟也非常低。
表现不错的英特尔
从第 11 代开始,英特尔将 SLM 移到了子片中(subslice),使本地内存配置类似于 AMD 和 Nvidia 的。Apple 可能也会这样做(在 iGPU 内核中放置“tile memory”),因为 Apple iGPU 上的本地内存延迟也非常低。
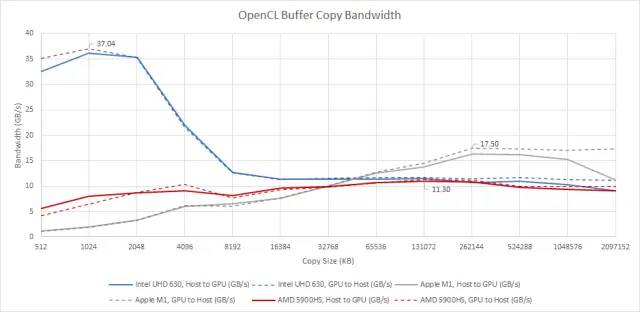
共享的芯片级缓存可以带来其他好处。理论上,CPU 和 GPU 内存空间之间的传输可以通过共享缓存,基本上在 CPU 和 GPU 之间提供了非常高的带宽链接。由于时间和资源的限制,这里测试的设备略有不同。但Renoir 和 Cezanne应该是相似的,英特尔的行为不太可能从 Skylake 倒退。
测试显示,只有英特尔能够利用共享缓存来加速不同块之间的数据移动。只要缓冲区大小适合 L3,Skylake 就会完全在芯片内处理副本,性能计数器显示的内存流量非常少。较大的副本仍然受到内存带宽的限制。这里测试的 Core i7-7700K 只有双通道 DDR4-2400 设置,所以这并不是一个强项。
苹果理论上应该也能做到。但是,对于应该适合 M1 系统级缓存的小副本大小,我们没有看到任何改进。有几种解释。一是 M1 无法保持 CPU 到 GPU 的片内传输。另一个是小传输保持在裸片上,但是到 GPU 的命令延迟非常高,导致小副本的性能很差。英特尔的 Haswell iGPU 也存在同样的问题,因此第二个很可能是解释。当我们获得更大的副本大小时,M1 的高带宽 LPDDR4X 设置做得非常好。
AMD的表现很容易理解。没有共享缓存,因此 CPU 和 GPU 之间的带宽受到内存带宽的限制。
最后,值得注意的是,这里的所有 iGPU 以及现代专用 GPU 理论上都可以通过在 CPU 和 GPU 上映射适当的内存来进行零拷贝传输。但是我们目前没有编写测试来分析映射内存的传输速度。
GPU 往往是内存带宽消耗者,为集成 GPU 提供数据尤其具有挑战性。它们的内存子系统通常不如专用 GPU 强大。更糟糕的是,iGPU 不得不与 CPU 争夺内存带宽。
苹果和英特尔都通过复杂的缓存层次结构来应对这一挑战,包括为 CPU 和 GPU 提供服务的大型片上缓存。这两家公司根据他们如何改进他们的设计,采用不同的方法来实现该缓存。英特尔拥有最集成的解决方案。它的 L3 缓存具有双重职责。它与高速环形互连上的 CPU 内核非常紧密地联系在一起,以便为 CPU 端访问提供低延迟。iGPU 只是环总线上的另一个代理,L3 切片以相同的方式处理 iGPU 和 CPU 核心请求。
英特尔拥有快速、灵活的环形总线,可以连接各种代理。iGPU 只是环形总线上的另一个代理
Apple 使用更专业的缓存,而不是尝试为 CPU 和 GPU 优化一个缓存。M1 在 Firestorm CPU 集群中实现了一个 12 MB L2 缓存,从 CPU 的角度来看,它的作用与 Intel 的 L3 相似。一个单独的 8 MB 系统级缓存有助于减少芯片上所有块的 DRAM 带宽需求,并作为到达内存控制器之前的最后一站。通过划分职责,Apple 可以严格优化 12 MB L2 以实现 CPU 内核的低延迟。由于 L2 足够大,可以吸收大量 CPU 端请求,因此系统级缓存的延迟可以更高,以节省电力。
M1还有一点改进的余地。它的缓存带宽与计算比率可能会更高一些。CPU 和 GPU 之间的传输可以充分利用系统级缓存来提高带宽。但这些都是很小的抱怨,总体而言,Apple 的设置非常可靠。
Apple 有一个速度较慢的 SoC 范围的互连和各种模块。仅绘制 Firestorm 集群和 GPU 以节省空间
相比之下,AMD 的缓存设置很简单。Renoir (和Cezanne)基本上是将 CPU 和 GPU 粘合在一起。额外的 GPU 端 L2 是为降低内存带宽要求而做出的唯一让步。而这里的“额外”仅适用于与离散 GCN 卡相比。与 Apple 和 Intel 相比,1 MB 的 L2 并没有什么特别之处,它们的 iGPU 中都有 1 MB 或更大的缓存。如果 L2 丢失,AMD 直接进入内存。内存带宽并不是 AMD 的强项,这让 Renoir 缺乏缓存更加糟糕。Renoir 的 CPU 端设置也无济于事。只有桌面 Zen 2 大小的 1/4 的 L3 设置将导致来自 CPU 内核的额外内存流量,给内存控制器带来更大的压力。
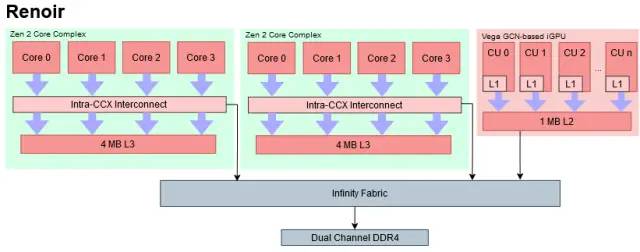 Cezanne 的布局非常相似,但 Zen 3 核心位于单核心复合体中
AMD 的 APU 缓存设置还有很多不足之处。不知何故,AMD 的 iGPU
仍然能够与英特尔的 Tiger Lake iGPU 竞争
,这说明了他们的 GCN 图形架构的实力。我只是希望他们利用这种潜力来提供杀手级 APU。毕竟,AMD 有很多可以改进的低级成果。基于 RDNA 2 的离散 GPU 使用位于 Infinity Fabric 后面的大型“Infinity Cache”来降低内存带宽需求。实施该缓存所获得的经验可能会渗透到 AMD 的集成 GPU 上。
Cezanne 的布局非常相似,但 Zen 3 核心位于单核心复合体中
AMD 的 APU 缓存设置还有很多不足之处。不知何故,AMD 的 iGPU
仍然能够与英特尔的 Tiger Lake iGPU 竞争
,这说明了他们的 GCN 图形架构的实力。我只是希望他们利用这种潜力来提供杀手级 APU。毕竟,AMD 有很多可以改进的低级成果。基于 RDNA 2 的离散 GPU 使用位于 Infinity Fabric 后面的大型“Infinity Cache”来降低内存带宽需求。实施该缓存所获得的经验可能会渗透到 AMD 的集成 GPU 上。
 AMD 的 RDNA2 使用巨大的 128 MB 无限缓存来与 Nvidia 竞争,同时内存带宽要少得多
不难想象,Infinity Cache 除了降低 GPU 内存带宽需求外,还能带来其他好处。例如,缓存可以在 GPU 和 CPU 内存之间实现更快的复制。而且它可以提高 CPU 性能,特别是因为与台式机芯片相比,AMD 喜欢为其 APU 提供更少的 CPU 端 L3。
但这样的举动在下一代或两代人中不太可能发生。随着 AMD 转向 LP/DDR5,带宽提升以及大型架构更改使 AMD 能够将 Rembrandt 的 iGPU 性能提高一倍。考虑到Renoir (and Cezanne)已经获得足够的图形性能、英特尔无法利用其卓越的缓存设置以及苹果封闭的生态系统,AMD 几乎没有采取积极行动的压力。
APU 上的无限缓存也需要很大的芯片面积才能有效。使用 8 MB 系统级缓存的命中率(hitrate)非常糟糕:
AMD 的 RDNA2 使用巨大的 128 MB 无限缓存来与 Nvidia 竞争,同时内存带宽要少得多
不难想象,Infinity Cache 除了降低 GPU 内存带宽需求外,还能带来其他好处。例如,缓存可以在 GPU 和 CPU 内存之间实现更快的复制。而且它可以提高 CPU 性能,特别是因为与台式机芯片相比,AMD 喜欢为其 APU 提供更少的 CPU 端 L3。
但这样的举动在下一代或两代人中不太可能发生。随着 AMD 转向 LP/DDR5,带宽提升以及大型架构更改使 AMD 能够将 Rembrandt 的 iGPU 性能提高一倍。考虑到Renoir (and Cezanne)已经获得足够的图形性能、英特尔无法利用其卓越的缓存设置以及苹果封闭的生态系统,AMD 几乎没有采取积极行动的压力。
APU 上的无限缓存也需要很大的芯片面积才能有效。使用 8 MB 系统级缓存的命中率(hitrate)非常糟糕:
 28% 的带宽减少意味着 28% 的命中率。
缓存命中率往往会随着大小的对数而增加,因此 AMD 可能希望从至少 32 MB 的缓存开始以使其值得付出努力。这意味着更大的芯片,不幸的是,我不确定消费级 x86 领域是否有强大的 APU 市场。
28% 的带宽减少意味着 28% 的命中率。
缓存命中率往往会随着大小的对数而增加,因此 AMD 可能希望从至少 32 MB 的缓存开始以使其值得付出努力。这意味着更大的芯片,不幸的是,我不确定消费级 x86 领域是否有强大的 APU 市场。
★ 点击文末
【阅读原文】
,可查看本文原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3048内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!