来源:内容由半导体行业观察(ID:icbank)转载自公众号【
5G行业应用
】,作者:半山,谢谢。
未来DC数据中心的终极目标,是变成一台超级计算机,有着几乎无限的计算能力和存储资源,超大带宽、超低延迟,上面跑无数的虚拟机或者容器之类的云计算平台
。谷歌近期发布一篇关于Aquila网络架构的文章,今天我们就顺着最近大热的DPU,来聊聊网络架构。
作为芯片和通讯行业从业者,我们先从承载网聊起(也叫传输网),然后再说数据中心网络,最后对照谷歌Aquila架构,展望一下网络架构未来的演进趋势。
一般我们说到承载网,是指基站和核心网各网元之间的组网。手机通过空口接入基站,基站通过光纤、交换机,和核心网各网元进行组网,最后通过核心路由器,汇入互联网。如图1所示。从2G时代到5G时代,承载网技术在不断演进,如图2所示。
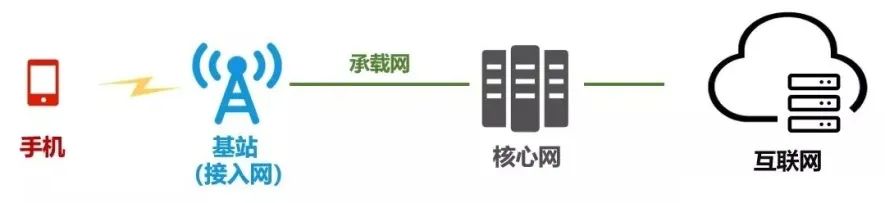 图1 承载网位置
图1 承载网位置
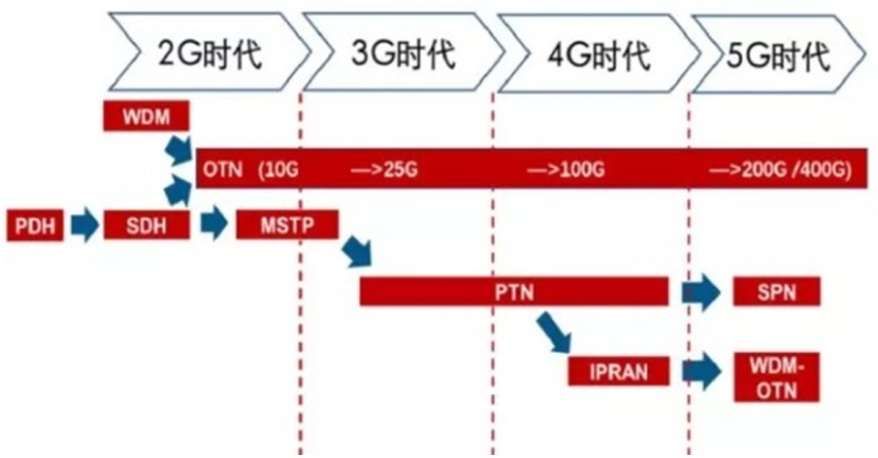 图2 承载网技术演进路线图(图片来源:无线深海)
SDH主要用在GSM/2G时代的语音承载(也叫CS电路交换,不是那个真人射击游戏CS,而是Circuit Switching),TDM时分复用、双向环状组网、块状帧结构,凭借着极高的服务质量和可管理性,一度统治了传输网,如图3所示。市场经济中,做生意最难的不是生产,而是找到合适、持续的买家来消费。语音时代,就是打电话,需求刚性、稳定、明确,一切都好说。
图2 承载网技术演进路线图(图片来源:无线深海)
SDH主要用在GSM/2G时代的语音承载(也叫CS电路交换,不是那个真人射击游戏CS,而是Circuit Switching),TDM时分复用、双向环状组网、块状帧结构,凭借着极高的服务质量和可管理性,一度统治了传输网,如图3所示。市场经济中,做生意最难的不是生产,而是找到合适、持续的买家来消费。语音时代,就是打电话,需求刚性、稳定、明确,一切都好说。
 图3 SDH组网图(图片来源:ITU)
到了3/4G时代,语音通话占比急剧降低,IP业务比重越来越大,原因也不复杂,大家看一下自己打电话、玩微信、刷抖音的时间分配。IP和Eth这俩货,都是秉承着无连接、尽力而为的原则(这两点后面会反复提及),包大小变长、不固定,和SDH的刚性网络格格不入。为了填平这个GAP,MSTP(MSTP = SDH + 以太网 + ATM)、MSTP+被推了出来,给SDH续了十年左右的命。
但随着IP占比逐渐达到压倒性优势,SDH再也凑活不下去了,PTN应运而生。之前看过一个公式,PTN = MPLS + OAM + 保护 - IP,要理解这个公式,咱们得先看看MPLS是啥,如图4所示。
图3 SDH组网图(图片来源:ITU)
到了3/4G时代,语音通话占比急剧降低,IP业务比重越来越大,原因也不复杂,大家看一下自己打电话、玩微信、刷抖音的时间分配。IP和Eth这俩货,都是秉承着无连接、尽力而为的原则(这两点后面会反复提及),包大小变长、不固定,和SDH的刚性网络格格不入。为了填平这个GAP,MSTP(MSTP = SDH + 以太网 + ATM)、MSTP+被推了出来,给SDH续了十年左右的命。
但随着IP占比逐渐达到压倒性优势,SDH再也凑活不下去了,PTN应运而生。之前看过一个公式,PTN = MPLS + OAM + 保护 - IP,要理解这个公式,咱们得先看看MPLS是啥,如图4所示。
 图4 IP与MPLS转发的基本行为对比
(图片来源:《图解网络硬件》)
OSI参考模型中,ATM和Eth都位于L2(当然Eth也是有L1物理层规范的),但设计原则、帧结构完全不同。以太帧的原则是变长、无连接、尽力而为,ATM是定长、有连接(其实ATM是TDM技术的一个升级、优化版本),在两者的竞争中,凭借着和IP的设计理念一致,Eth逐渐胜出,现在ATM都不咋用了。
Eth和IP网络中,无连接和尽力而为,是柄双刃剑。在非超低延迟组网中,这个问题不大,交换机根据MAC地址,进行存储转发,路由器根据IP地址和子网掩码,进行最长匹配,而且中高端的Switch和Gateway,目前都是ASIC硬件加速,部分掩盖了QoS和延迟的缺陷。
但在超低延迟组网中,比如5G uRLLC承载和数据中心网络,QoS和延迟是关键指标。既然Eth/IP和ATM各有千秋,业界就搞出了个MPLS。简单来讲,MPLS属于OSI参考模型中的2.5层,向IP提供连接服务,本质是隧道技术的一种,L2可以采用Eth,也可以用其他的层二技术。
传统路由中,分为动态路由和静态路由。动态路由主要由RIP、OSPF、BGP这些路由协议(通过UDP/TCP承载),在Gateway之间同步路由表,实际上是无连接的分布式处理。因为IP网络是M国军方设计的,一开始的目标,就是在极端情况下,各核心部门,依然能够保持通讯畅通,所以分布式、去中心化的设计是必然的。带来的额外负担,就是每个路由器节点,都要维护一个巨大的路由表。如果你仔细阅读谷歌论文,会发现Aquila中,会在TiN中只维护一个小表,这个和MPLS类似。
MPLS架构中,为了建立连接、减少路由表的查找和维护负担,会根据路由协议下发的路由表信息,由边缘路由器节点,生成局部标签,这个Tag就相当于一条虚拟的链接标识,后面MPLS的内部路由器,根据标签直接转发,相当于对路由表进行了提取和抽象,后面直接用即可,所以MPLS和动态路由,还是有很多关联。
PTN公式中的 - IP,实际上就是把MPLS中的动态路由,改成了由控制面的网管,进行统一的配置和下发,同时L2层面,硬件支持OAM PDU帧的解析、处理,这方面借鉴了SDH中丰富的可维护性设计,大家都在互相融合,或者说互相抄袭。
图4 IP与MPLS转发的基本行为对比
(图片来源:《图解网络硬件》)
OSI参考模型中,ATM和Eth都位于L2(当然Eth也是有L1物理层规范的),但设计原则、帧结构完全不同。以太帧的原则是变长、无连接、尽力而为,ATM是定长、有连接(其实ATM是TDM技术的一个升级、优化版本),在两者的竞争中,凭借着和IP的设计理念一致,Eth逐渐胜出,现在ATM都不咋用了。
Eth和IP网络中,无连接和尽力而为,是柄双刃剑。在非超低延迟组网中,这个问题不大,交换机根据MAC地址,进行存储转发,路由器根据IP地址和子网掩码,进行最长匹配,而且中高端的Switch和Gateway,目前都是ASIC硬件加速,部分掩盖了QoS和延迟的缺陷。
但在超低延迟组网中,比如5G uRLLC承载和数据中心网络,QoS和延迟是关键指标。既然Eth/IP和ATM各有千秋,业界就搞出了个MPLS。简单来讲,MPLS属于OSI参考模型中的2.5层,向IP提供连接服务,本质是隧道技术的一种,L2可以采用Eth,也可以用其他的层二技术。
传统路由中,分为动态路由和静态路由。动态路由主要由RIP、OSPF、BGP这些路由协议(通过UDP/TCP承载),在Gateway之间同步路由表,实际上是无连接的分布式处理。因为IP网络是M国军方设计的,一开始的目标,就是在极端情况下,各核心部门,依然能够保持通讯畅通,所以分布式、去中心化的设计是必然的。带来的额外负担,就是每个路由器节点,都要维护一个巨大的路由表。如果你仔细阅读谷歌论文,会发现Aquila中,会在TiN中只维护一个小表,这个和MPLS类似。
MPLS架构中,为了建立连接、减少路由表的查找和维护负担,会根据路由协议下发的路由表信息,由边缘路由器节点,生成局部标签,这个Tag就相当于一条虚拟的链接标识,后面MPLS的内部路由器,根据标签直接转发,相当于对路由表进行了提取和抽象,后面直接用即可,所以MPLS和动态路由,还是有很多关联。
PTN公式中的 - IP,实际上就是把MPLS中的动态路由,改成了由控制面的网管,进行统一的配置和下发,同时L2层面,硬件支持OAM PDU帧的解析、处理,这方面借鉴了SDH中丰富的可维护性设计,大家都在互相融合,或者说互相抄袭。
聊完运营商的承载网,再来看看数据中心(DC)网络。在这两种网络的组网拓扑中,都可以分为接入层、汇聚层、核心层,只是DC网络的演进更为剧烈。如图5所示。
 图5 数据中心网络架构(图片来源:Cisco官网)
通信企业经常说端、管、云协同演进,这里面的端,主要指手机移动终端,管主要指承载网,云要稍微解释一下。
通常意义上,云计算是互联网厂商的领域,毕竟他们的各种业务,比如微信、支付宝、抖音的后端,都是通过PaaS、IaaS这些云计算平台,承载在数据中心机房的一堆服务器上。但实际上,现在核心网的网元,都已经云化了,这一点和互联网厂商是一致的。
早期亚马逊这些互联网巨头,发现他们自家的服务器和云服务,在满足自身业务需求的同时,还有富余,可以对外售卖,这就是目前主流的公有云由来。另外说一句,亚马逊在云计算领域,目前是无可争议的王者,引领各种技术路线的演进。
云计算都是承载在大量的服务器上,这些机器部署在数据中心机房中。本来传统的C/S架构,终端发请求,比如访问某个网站页面,通过承载网、骨干网的一堆交换机、路由器,一路到了数据中心的机房,服务器就给你返回一堆网页数据,终端收到数据后,浏览器引擎解析、展示。
但随着搜索引擎、大数据处理、人工智能这些领域的应用兴起,DC的单台服务器无法满足大量计算和存储的需求,分布式架构成为必然。同时云计算中的热迁移、备份、容灾和隔离需求日渐增多,DC原有的南北向(C/S)和东西向(内部节点之间)流量对比关系发生变化,原有的松耦合带来的通信瓶颈,日趋明显。
这里多说一句存储,在SSD固态硬盘之前,HDD是绝对的主流。受限于物理磁盘的寻道时延,HDD读写延迟早已逼近物理极限,所以那个时候DC内部存储部分的网络时延,都显得问题不大。SSD没有物理磁盘,内部是一堆Flash器件 + 控制器,速度极快,配合专为非易失性存储设计的NVMe和NVMeOF,网络时延从小头变成了大头,木桶效应之下,网络带宽、时延和QoS优化势在必行。
在DPU之前,业界整了一堆技术和解决方案,比如英特尔,他们一直是以处理器为核心,主推DPDK加速,通过用户态驱动,ByPass内核协议栈,中断改为Poll轮询,降低了用户态和内核态的切换开销,以及内存Copy负担,配合一些新增的类似AVX 512的专用指令,但本质上还是TCP/IP那一套。
Mellanox(已被Nvidia收购),搞出了个IB(Infinite Band,听名字就很牛,无限带宽),上层承载RDMA协议,凭借其超高带宽、超低延迟、超可靠传输,在DC内部大行其道,但IB需要专用的NIC网卡、连接线缆和交换机,一套下来贵的吓人,急需降成本。如图6所示。
这里说一下,RDMA和TCP/IP是并列或者说竞争关系,TCP/IP的优点是生态繁荣、稳定,缺点是软件参与过多,准确说是内核协议栈,所以延迟很大。SmartNIC中,会通过硬件offload一部分TCP/IP软件开销,但TCP/IP协议栈的设计理念和实现复杂度,就不是为了硬件设计的。
图5 数据中心网络架构(图片来源:Cisco官网)
通信企业经常说端、管、云协同演进,这里面的端,主要指手机移动终端,管主要指承载网,云要稍微解释一下。
通常意义上,云计算是互联网厂商的领域,毕竟他们的各种业务,比如微信、支付宝、抖音的后端,都是通过PaaS、IaaS这些云计算平台,承载在数据中心机房的一堆服务器上。但实际上,现在核心网的网元,都已经云化了,这一点和互联网厂商是一致的。
早期亚马逊这些互联网巨头,发现他们自家的服务器和云服务,在满足自身业务需求的同时,还有富余,可以对外售卖,这就是目前主流的公有云由来。另外说一句,亚马逊在云计算领域,目前是无可争议的王者,引领各种技术路线的演进。
云计算都是承载在大量的服务器上,这些机器部署在数据中心机房中。本来传统的C/S架构,终端发请求,比如访问某个网站页面,通过承载网、骨干网的一堆交换机、路由器,一路到了数据中心的机房,服务器就给你返回一堆网页数据,终端收到数据后,浏览器引擎解析、展示。
但随着搜索引擎、大数据处理、人工智能这些领域的应用兴起,DC的单台服务器无法满足大量计算和存储的需求,分布式架构成为必然。同时云计算中的热迁移、备份、容灾和隔离需求日渐增多,DC原有的南北向(C/S)和东西向(内部节点之间)流量对比关系发生变化,原有的松耦合带来的通信瓶颈,日趋明显。
这里多说一句存储,在SSD固态硬盘之前,HDD是绝对的主流。受限于物理磁盘的寻道时延,HDD读写延迟早已逼近物理极限,所以那个时候DC内部存储部分的网络时延,都显得问题不大。SSD没有物理磁盘,内部是一堆Flash器件 + 控制器,速度极快,配合专为非易失性存储设计的NVMe和NVMeOF,网络时延从小头变成了大头,木桶效应之下,网络带宽、时延和QoS优化势在必行。
在DPU之前,业界整了一堆技术和解决方案,比如英特尔,他们一直是以处理器为核心,主推DPDK加速,通过用户态驱动,ByPass内核协议栈,中断改为Poll轮询,降低了用户态和内核态的切换开销,以及内存Copy负担,配合一些新增的类似AVX 512的专用指令,但本质上还是TCP/IP那一套。
Mellanox(已被Nvidia收购),搞出了个IB(Infinite Band,听名字就很牛,无限带宽),上层承载RDMA协议,凭借其超高带宽、超低延迟、超可靠传输,在DC内部大行其道,但IB需要专用的NIC网卡、连接线缆和交换机,一套下来贵的吓人,急需降成本。如图6所示。
这里说一下,RDMA和TCP/IP是并列或者说竞争关系,TCP/IP的优点是生态繁荣、稳定,缺点是软件参与过多,准确说是内核协议栈,所以延迟很大。SmartNIC中,会通过硬件offload一部分TCP/IP软件开销,但TCP/IP协议栈的设计理念和实现复杂度,就不是为了硬件设计的。
 图6 Infinite Band架构(图片来源:知乎 @Savir)
RDMA则不同,设计之初,和IB的L2/Phy配合,都是硬化实现,软件开销急速降低,省出来的CPU资源,给云计算的用户和上层应用来用,如图7所示,就问你香不香。IB好是好,就是太贵,能不能像ATM和Eth融合一样,搞出了个类似MPLS的新玩意呢,这就是后来的RoCE和RoCEv2。通过以太网卡和以太交换机,来承载RDMA协议,这样一来,只要网卡升级一下,线缆和交换机都是现成的,只是上层应用需要调用Verbs接口,替换原来的Socket接口。
图6 Infinite Band架构(图片来源:知乎 @Savir)
RDMA则不同,设计之初,和IB的L2/Phy配合,都是硬化实现,软件开销急速降低,省出来的CPU资源,给云计算的用户和上层应用来用,如图7所示,就问你香不香。IB好是好,就是太贵,能不能像ATM和Eth融合一样,搞出了个类似MPLS的新玩意呢,这就是后来的RoCE和RoCEv2。通过以太网卡和以太交换机,来承载RDMA协议,这样一来,只要网卡升级一下,线缆和交换机都是现成的,只是上层应用需要调用Verbs接口,替换原来的Socket接口。
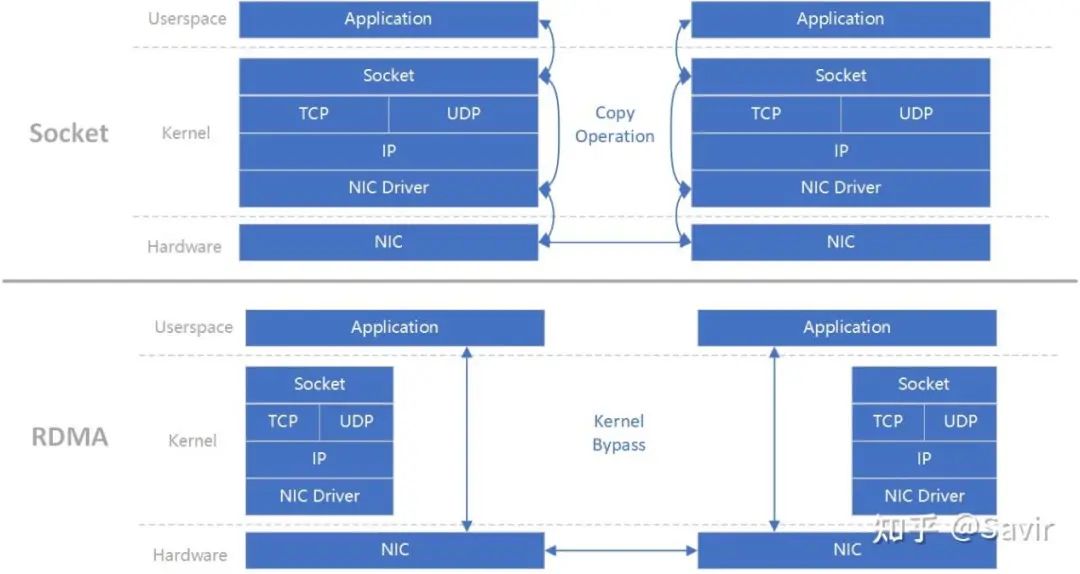 图7 RDMA(图片来源:知乎 @Savir)
最近DPU赛道很火,Nvidia收购Mellanox、Intel收购Barefoot,最近AMD把几位前Cisco员工创办的Pensando揽入麾下,加上亚马逊的Nitro、阿里的神龙架构,还有最近国内几家初创公司,市场热闹的一塌糊涂。
我们来看DPU几个核心的功能,首先是硬件Offload:
2、存储:NVMeOF(Over Fabric)等
3、虚拟化:Virtio、SR-IOV、VxLAN(基于UDP的一种大二层隧道技术)
6、双Hypervisor:原有的Hyper变轻、变薄,新增的下沉到DPU内置的核,一般是ARM,最近有采用RISC-V替换的苗头。
目前关于DPU,业界还没有统一的定义或者规范,将来也不一定会有。DPU是DSA架构的一种实践,属于SmartNIC的升级版或者说下一代,同时ToR交换机、Spine - Leaf架构网络,都还是存在的。
图7 RDMA(图片来源:知乎 @Savir)
最近DPU赛道很火,Nvidia收购Mellanox、Intel收购Barefoot,最近AMD把几位前Cisco员工创办的Pensando揽入麾下,加上亚马逊的Nitro、阿里的神龙架构,还有最近国内几家初创公司,市场热闹的一塌糊涂。
我们来看DPU几个核心的功能,首先是硬件Offload:
2、存储:NVMeOF(Over Fabric)等
3、虚拟化:Virtio、SR-IOV、VxLAN(基于UDP的一种大二层隧道技术)
6、双Hypervisor:原有的Hyper变轻、变薄,新增的下沉到DPU内置的核,一般是ARM,最近有采用RISC-V替换的苗头。
目前关于DPU,业界还没有统一的定义或者规范,将来也不一定会有。DPU是DSA架构的一种实践,属于SmartNIC的升级版或者说下一代,同时ToR交换机、Spine - Leaf架构网络,都还是存在的。
现在,我们终于可以开始讨论谷歌的Aquila,先对照图8所示框架图,说下论文中的几个关键术语:
1、Aquila:数据中心的一种新型实验性质的网络架构
2、TiN:ToR in NIC,NIC和ToR交换机二合一,实现网卡+交换
3、GNet:谷歌自定义二层子网和外部Eth/IP网络之间的网关。
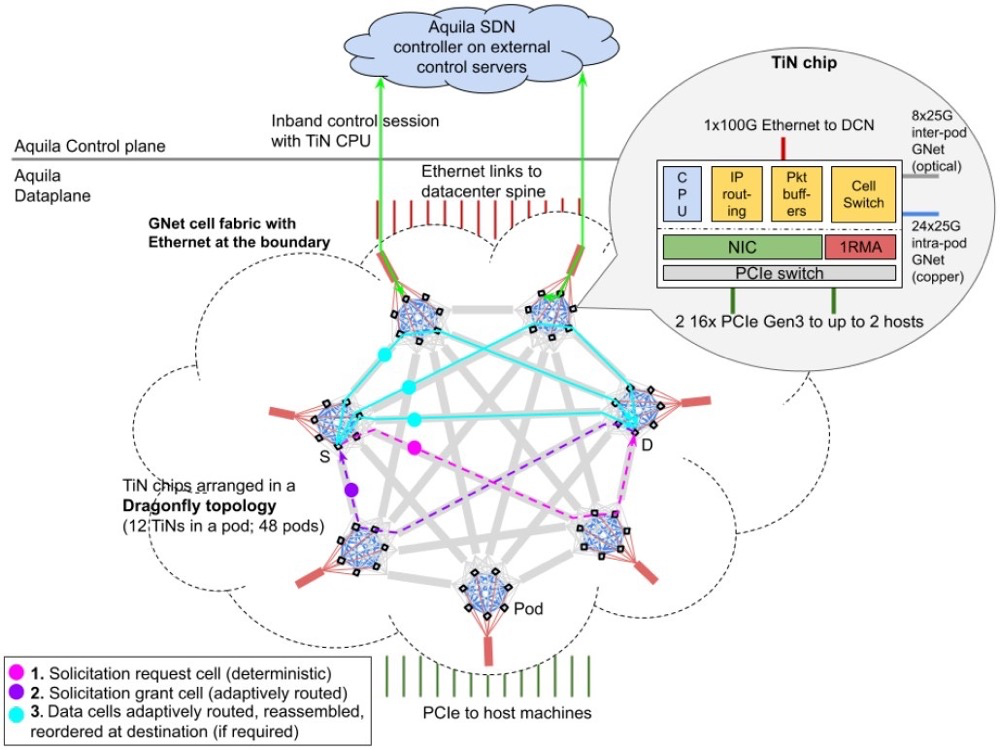 图8 Aquila框架图(图片来源:谷歌Aquila论文)
从论文中可以看出,谷歌在现有的DC以太局域网基础上,增加了自己设计的一个二层子网,在不动现有DC Spine Leaf + Eth/IP架构的基础上,构建一个超低延迟的L2内网,满足数据中心分布式计算、存储的超低时延要求。
从架构上看,Aquila = 自建IB + 传统Eth/IP,既不是Overlay,也不是Underlay。TiN既然实现了NIC + 交换机的功能,那就绕不开SDN。Eth/IP都是尽力而为的分布式设计,加上多设备厂商混战,所以在前期,QoS、组网、网优、清障都非常麻烦,长期下去要炸毛。
原有的交换机/路由器中,控制面和数据面都有,各自为战。SDN实际上就是把各个交换机/路由器的控制面职能回收,统一管理,让SW/Gateway只负责数据面转发。控制器和交换机之间建立安全通道,通过各种消息,在合适的时机下发流表,也就是大家常说的OpenFlow,指挥交换机如何对各个以太帧/IP报文进行处理。
OpenFlow流表中,有三个关键要素,key + action + counter。交换机通过key(比如经典的五元组),查找TCAM表,进行Eth帧/IP报文匹配,然后执行流表中的action,同时更新各种counter计数。流表类似于处理器架构中的指令集,比如指令中有Opcode,取指完成后会进行译码,根据指令类型,进行ALU计算或者访存,最后将结果写回寄存器或者内存。
从生态角度,NIC和交换机/路由器大家各司其职,Aquila中的TiN搞了个二合一,相当于是把DC市场切了一份出来,搞自己独立的L2子网,这部分市场的NIC/DPU/ToR都被干掉了,然后谷歌还要搞自己的SDN控制器。
回忆一下开篇介绍的ATM、Eth、MPLS,有没有发现相似之处。其实现在交换机、路由器内部设计中,Eth帧进来以后,也会转换成各家自定义的信元,进行CrossBar的交换和处理。基于信元和有连接的设计,流控和QoS实现会简单很多。
可以对照一下最近很火的Chiplet。传统的中小型SoC设计中,片上网络一般是共享总线,比如AMBA3 AXI。随着片内核的数量增多,衍生出Ring环形总线和Mesh网络,此时的片内,实际上已经有了交换/路由的影子,几十上百个核,通过内部专用信号线,连上片内的路由节点,然后多个路由节点之间,进行报文收发,实现Mesh组网,只是内部的报文,格式一般都是CPU厂商自定义的,比如ARM的AMBA5 CHI。
随着单Die面积变大,受晶圆面积和良率关系限制,单芯片方案逐渐显露瓶颈,无法集成更多的核或者加速引擎,多芯片拼接需求增多,加上2.5D/3D高级封装技术,应用日趋成熟,类似HBM这种堆叠的Chiplet方案也开始增多。前段时间英特尔搞了个UCIe联盟,想在Chiplet领域复制PCIe的辉煌,其实本质就是片间互联网络的生态,开始构建了。
回到开篇的超级计算机话题,从SoC片内总线,到Chiplet片间互联网络,再到谷歌Aquila实验性的数据中心全新二层子网,其实本质都是为了这个终极的目标来服务,
从晶圆、基板、PCB,到数据中心服务器之间,超大带宽、超低延迟、超强流控的网络,在从内向外扩展
。因为在数据中心领域,运营商的话语权不像电信承载网这么大,芯片巨头和云计算厂商,有动力、有预算、也有技术空间去进行重构、优化。
运营商的承载网,在5G eMMB超高带宽、URLLC超低延迟的压力和需求下,正在进行剧烈的变化和演进,5G承载和LTE承载之间,已经发生了巨大的变化和改进。MPLS、PTN、OTN这些技术能在承载网落地生根,除了其高效的OAM外,强大的QoS亦功不可没,当然前提是基站和核心网之间的组网中,网络的动态拓扑变化不是非常大。如图9所示。
图8 Aquila框架图(图片来源:谷歌Aquila论文)
从论文中可以看出,谷歌在现有的DC以太局域网基础上,增加了自己设计的一个二层子网,在不动现有DC Spine Leaf + Eth/IP架构的基础上,构建一个超低延迟的L2内网,满足数据中心分布式计算、存储的超低时延要求。
从架构上看,Aquila = 自建IB + 传统Eth/IP,既不是Overlay,也不是Underlay。TiN既然实现了NIC + 交换机的功能,那就绕不开SDN。Eth/IP都是尽力而为的分布式设计,加上多设备厂商混战,所以在前期,QoS、组网、网优、清障都非常麻烦,长期下去要炸毛。
原有的交换机/路由器中,控制面和数据面都有,各自为战。SDN实际上就是把各个交换机/路由器的控制面职能回收,统一管理,让SW/Gateway只负责数据面转发。控制器和交换机之间建立安全通道,通过各种消息,在合适的时机下发流表,也就是大家常说的OpenFlow,指挥交换机如何对各个以太帧/IP报文进行处理。
OpenFlow流表中,有三个关键要素,key + action + counter。交换机通过key(比如经典的五元组),查找TCAM表,进行Eth帧/IP报文匹配,然后执行流表中的action,同时更新各种counter计数。流表类似于处理器架构中的指令集,比如指令中有Opcode,取指完成后会进行译码,根据指令类型,进行ALU计算或者访存,最后将结果写回寄存器或者内存。
从生态角度,NIC和交换机/路由器大家各司其职,Aquila中的TiN搞了个二合一,相当于是把DC市场切了一份出来,搞自己独立的L2子网,这部分市场的NIC/DPU/ToR都被干掉了,然后谷歌还要搞自己的SDN控制器。
回忆一下开篇介绍的ATM、Eth、MPLS,有没有发现相似之处。其实现在交换机、路由器内部设计中,Eth帧进来以后,也会转换成各家自定义的信元,进行CrossBar的交换和处理。基于信元和有连接的设计,流控和QoS实现会简单很多。
可以对照一下最近很火的Chiplet。传统的中小型SoC设计中,片上网络一般是共享总线,比如AMBA3 AXI。随着片内核的数量增多,衍生出Ring环形总线和Mesh网络,此时的片内,实际上已经有了交换/路由的影子,几十上百个核,通过内部专用信号线,连上片内的路由节点,然后多个路由节点之间,进行报文收发,实现Mesh组网,只是内部的报文,格式一般都是CPU厂商自定义的,比如ARM的AMBA5 CHI。
随着单Die面积变大,受晶圆面积和良率关系限制,单芯片方案逐渐显露瓶颈,无法集成更多的核或者加速引擎,多芯片拼接需求增多,加上2.5D/3D高级封装技术,应用日趋成熟,类似HBM这种堆叠的Chiplet方案也开始增多。前段时间英特尔搞了个UCIe联盟,想在Chiplet领域复制PCIe的辉煌,其实本质就是片间互联网络的生态,开始构建了。
回到开篇的超级计算机话题,从SoC片内总线,到Chiplet片间互联网络,再到谷歌Aquila实验性的数据中心全新二层子网,其实本质都是为了这个终极的目标来服务,
从晶圆、基板、PCB,到数据中心服务器之间,超大带宽、超低延迟、超强流控的网络,在从内向外扩展
。因为在数据中心领域,运营商的话语权不像电信承载网这么大,芯片巨头和云计算厂商,有动力、有预算、也有技术空间去进行重构、优化。
运营商的承载网,在5G eMMB超高带宽、URLLC超低延迟的压力和需求下,正在进行剧烈的变化和演进,5G承载和LTE承载之间,已经发生了巨大的变化和改进。MPLS、PTN、OTN这些技术能在承载网落地生根,除了其高效的OAM外,强大的QoS亦功不可没,当然前提是基站和核心网之间的组网中,网络的动态拓扑变化不是非常大。如图9所示。
 图9 网络切片(图片来源:无线深海)
谷歌的Aquila数据中心网络架构,从某种程度上,也是借鉴了CT网络架构的一些理念,来解决IT网络中的时延确定性需求,撇开了传统的二层以太网,绕过了Nvidia收购Mellanox后把持的Infinite Band,构建了一个类似RDMA的软硬件全栈生态,为此还专门设计了TiN和GNet芯片(工艺节点未知),投入如此巨大的资源,相信如同其AI领域的TensorFlow框架一样,这一切只是个开始,DPU的大幕正在徐徐拉开,我们拭目以待。
正如计算机体系结构的一代宗师,David Patterson和John Hennessy,在其2017年著名的论文《计算机体系架构的新黄金时代》中所预言的那样,“计算机体系结构领域将迎来又一个黄金十年,就像20世纪80年代那时一样,新的架构设计将会带来更低的成本,更优的能耗、安全和性能。”
正所谓软件定义一切、硬件加速一切、网络连接一切
。
图9 网络切片(图片来源:无线深海)
谷歌的Aquila数据中心网络架构,从某种程度上,也是借鉴了CT网络架构的一些理念,来解决IT网络中的时延确定性需求,撇开了传统的二层以太网,绕过了Nvidia收购Mellanox后把持的Infinite Band,构建了一个类似RDMA的软硬件全栈生态,为此还专门设计了TiN和GNet芯片(工艺节点未知),投入如此巨大的资源,相信如同其AI领域的TensorFlow框架一样,这一切只是个开始,DPU的大幕正在徐徐拉开,我们拭目以待。
正如计算机体系结构的一代宗师,David Patterson和John Hennessy,在其2017年著名的论文《计算机体系架构的新黄金时代》中所预言的那样,“计算机体系结构领域将迎来又一个黄金十年,就像20世纪80年代那时一样,新的架构设计将会带来更低的成本,更优的能耗、安全和性能。”
正所谓软件定义一切、硬件加速一切、网络连接一切
。
小知识1:DPU是Data Processing Unit的简称,它是最新发展起来的专用处理器的一个大类,是继CPU、GPU之后,数据中心场景中的第三颗重要算力芯片,为高带宽、低延迟、数据密集的计算场景提供计算引擎。
小知识2:Aquila是一种实验性的数据中心网络架构,将超低延迟作为核心设计目标,同时也支持传统的数据中心业务。Aquila使用了一种新的二层基于单元的协议、GNet、一个集成交换机和一个定制的ASIC,ASIC和GNet一同设计,并具有低延迟远程存储访问(RMA)。Aquila能够实现40µs以下的IP流量拖尾结构往返时间 (RTT) 和低于10µs的跨数百台主机的RMA执行时间。
「5G行业应用」特邀作家。近15年ICT芯片从业经历,从芯片到软件,从终端到云端,长期关注计算、通信和存储技术演进,软硬件融合践行者,对相关产业领域应用和生态建设有深度洞察。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3032内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!



