
英伟达3U一体的实现,网络平台很关键
2022-04-14
17:43:30
来源: 互联网
点击
随着数据中心成为了新的计算单元,英伟达提出了3U一体的数据中心新加速计算架构,3U具体是指,GPU解决并行计算的工作负载,DPU承担加速数据移动的工作负载,CPU承担通用计算业务应用的一些工作负载。而在3U一体数据中心新架构中,网络平台起到很重要的连接作用。

专为AI构建的以太网平台Spectrum-4
随着数据中心呈现指数级增长,应用层面、服务器层面对网络带宽的要求越来越高,同时还要提供更好的安全性和强大的功能。所以要在大规模应用场景中提供高性能、低延时,以及高级的虚拟化和模拟仿真支持的以太网平台,在这方面,英伟达的Spectrum-4是一个必不可少的解决方案。
Spectrum -4以太网平台由三大部分构成:Spectrum -4交换机可以加速整个云网络架构;ConnectX-7智能网卡,可以加速服务器节点中的网络性能适配器;再就是可编程数据中心基础架构BlueField-3 DPU 。这三个组成部分共同搭建成端到端的400G 超大规模的网络平台Spectrum-4。

作为全球首个 400Gbps 端到端以太网网络平台,NVIDIA Spectrum-4 的交换吞吐量比前几代产品高出 4 倍,达到 51.2 Tbps。Spectrum-4 交换机实现了纳秒级计时精度,相比普通毫秒级数据中心提升了五到六个数量级。这款交换机还能加速、简化和保护网络架构。与上一代产品相比,其每个端口的带宽提高了 2 倍,交换机数量减少到 1/4 ,功耗降低了 40%。

除了硬件的构成之外,软件方面也起着很大的作用,所以还有一个重要的组成部分是DOCA数据中心基础架构软件。通过DOCA可以更好的做软件开发应用,可以在大规模云原生应用场景下 加速整个数据中心 , 基于基础设施的虚拟化和软件定义、硬件加速的网络、存储、安全提供更多的应用和服务。
NVIDIA网络专家崔岩介绍到,Spectrum-4不仅仅是一个网络 平台,它将与NVIDIA其他的平台软件和应用做整合。Spectrum-4的作用是在底层提供更好的以太网 连接和对上层应用的支持,凭借支持 128 个 400GbE 端口的 51.2Tbps 聚合 ASIC 带宽,以及自适应路由选择和增强拥塞控制机制,Spectrum-4优化了基于融合以太网的RoCE (RDMA over Converged Ethernet)网络架构,并显著提升了数据中心的应用速度。Spectrum -4 平台具有加速、创新、优化、可靠的优势。
Spectrum-4的目标客户主要是在大规模云计算、企业AI、模拟仿真部分提供更好的网络性能的优化。凭借其速度、安全性和功能,Spectrum-4 平台已成为建立先进数据中心的理想选择,已有越来越多的合作伙伴选择使用 Spectrum-4 平台。
为Omniverse 数字 孪生技术而生的OVX 服务器
在上月的GTC大会上,英伟达发布了数字孪生概念的Omniverse,为了进一步扩大Omniverse , NVIDIA 在GTC 大会宣布名为NVIDIA OVX 的服务器架构,专为Omniverse 各式应用而生,并可借助OVX SuperPOD 标准化架构扩大系统规模。

OVX 服务器
单一的OVX服务器将8个NVIDIA A40 GPU、顶级CPU、超快NVMe 存储和领先的NVIDIA ConnectX®-6 Dx 网络适配器与企业级管理和编排软件相结合 。结合 NVIDIA Omniverse Enterprise,OVX 提供了一个完全集成的平台,可以为任何规模的数字双胞胎转换复杂的工作流程。
由OVX服务器组成的NVIDIA OVX SuperPOD具有网络结构、存储和企业级软件的优化组合,可为最苛刻的工作负载提供前所未有的性能。OVX 计算系统允许扩展至32台OVX 服务器,一个可扩展单元,无需额外开销或重新布线。
OVX SuperPOD则能够建构更大规模的数位孪生模拟环境。OVX Super POD 架构支持部署一个或多个 OVX 可扩展单元,提供工厂、城市或行星规模的大规模复杂模拟和实时数字双胞胎所需的低延迟网络、带宽和计算性能。
NVLink实现GPU高速互联
人工智能和高性能计算 (HPC)中不断增长的计算需求,正在推动对多节点、多 GPU 系统的需求,这些系统在每个 GPU 之间实现无缝、高速通信。为了构建能够满足业务速度的最强大的端到端计算平台,需要快速、可扩展的互连。因此,相比于传统的PCIe,英伟达自己开发了NVLink,NVLink是一种直接的GPU到GPU互连,可在服务器内扩展多GPU 输入/输出 (IO)。而在最新发布的H100 GPU中,英伟达升级了NVLink,到了第四代。
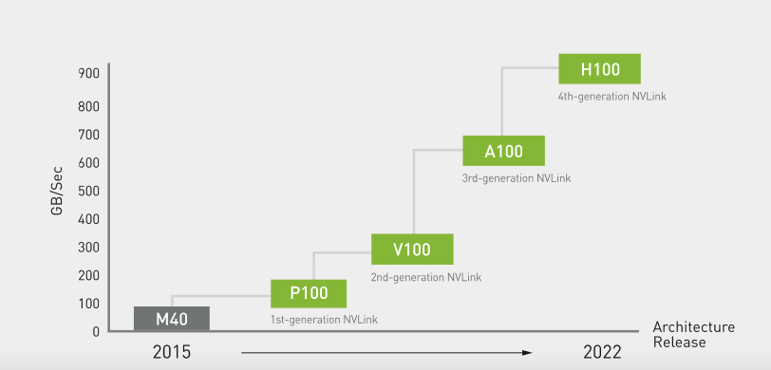
NVLin K性能(图源:英伟达)
第四代NVLink技术为多GPU系统配置提供了1.5倍的带宽和改进的可扩展性。单个 NVIDIA H100 Tensor Core GPU 支持多达18个 NVLink 连接,总带宽为每秒 900 GB (GB/s),是 PCIe Gen5 带宽的7倍以上。
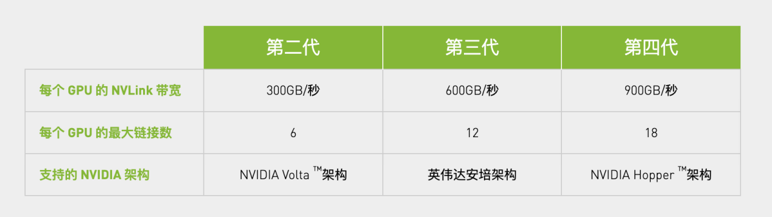
NVLin K每代的性能(图源:英伟达)
而NVSwitch则可以连接多个NVLink,以在单个节点内和节点之间以全 NVLink 速度提供全对全 GPU 通信。借助 NVSwitch,NVLink 连接可以跨节点扩展,以创建无缝、高带宽、多节点 GPU 集群,有效地形成数据中心大小的 GPU。通过在服务器外部添加第二层 NVLink 交换机,NVLink Switch系统以900GB/s互连每个GPU对,可以连接多达 256 个GPU,并提供57.6 TB/秒 (TB/s) 的总带宽,从而可以快速解决即使是最大的人工智能工作。
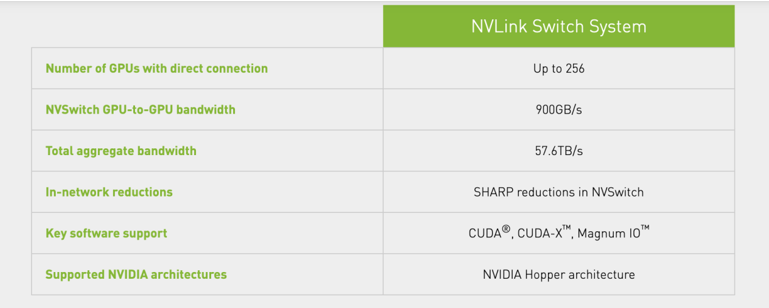
NVLink Switch系统(图源:英伟达)
那么,NVLink Switch和InfiniBand的区别是什么?据网络市场总监孟庆的解答,两者最大的区别是,NVLink只连接GPU。它连的是GPU计算的内存,或可以理解为显存。而其他所有的通用计算网络,就需要InfiniBand来发挥连接作用。凡是对计算的并行性、时延、带宽需求很大的情况下,InfiniBand仍然是AI和超级计算的首选网络。
结语
如黄仁勋所说:“不要将英伟达视为一家GPU公司,而是一家计算平台公司。”得益于在网络平台上的构建,英伟达的芯片在AI领域得以发挥更大的功能和作用。
责任编辑:sophie






-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 复杂SoC芯片设计中有哪些挑战?
- 2 进迭时空完成A+轮数亿元融资 加速RISC-V AI CPU产品迭代
- 3 探索智慧实践,洞见AI未来!星宸科技2024开发者大会暨产品发布会成功举办
- 4 重磅发布:日观芯设IC设计全流程管理软件RigorFlow 2.0
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号