来源:内容由半导体行业观察(ID:icbank)
编译自tomshardware
,谢谢。
英特尔最近发布的一项专利可能是其未来图形加速器设计的基石——它利用了多芯片模块 (MCM:Multi-Chip Module) 方法。英特尔描述了一系列协同工作以提供单帧的图形处理器。英特尔的设计指向工作负载的层次结构:主图形处理器协调整个工作负载。该公司将 MCM 作为一个整体方法构建为一个必要的步骤,以引导芯片设计人员远离在不断追求性能的过程中不断增加裸片尺寸所带来的可制造性、可扩展性和供电问题。
根据英特尔的专利,多个图形绘制调用(指令)传送到“多个”图形处理器。然后,第一图形处理器实质上运行整个场景的初始绘制通道。此时,图形处理器只是创建可见性(和障碍)数据;它决定渲染什么,这是在现代图形处理器上进行的高速操作。然后,在第一次通过期间生成的一些图块会转到其他可用的图形处理器。根据该初始可见性传递,他们将负责准确地渲染与其tiles相对应的场景,这表明每个tile中的图元或显示没有要渲染的地方。
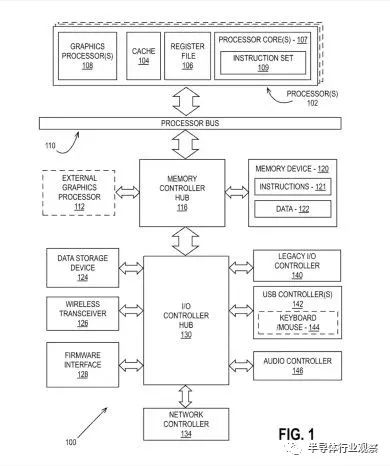
一种集成了英特尔专利中描述的图形处理器之一的计算机系统。请注意处理器和内核中的复数。(图片来源:英特尔)

英特尔“细节”之一的详细示意图(图片来源:英特尔)
因此,英特尔似乎正在考虑将基于图块的棋盘渲染(当今 GPU 中使用的一项功能)与分布式顶点位置计算(在初始帧传递之外)集成在一起。最后,当所有图形处理器都渲染了他们的单帧拼图(包括着色、照明和光线跟踪)时,它们的贡献被拼接起来,以在屏幕上呈现最终图像。理想情况下,这个过程每秒会发生 60、120 甚至 500 次。英特尔对多芯片性能扩展的希望就这样摆在我们面前。然后,英特尔使用 AMD 和 Nvidia 显卡在 SLI 或 Crossfire 模式下工作的性能报告来说明经典多 GPU 配置的潜在性能提升。但是,当然,它总是低于真正的 MCM 设计。

基于图块的渲染,其中单个帧被分成多个图块。在英特尔的专利中,这些图块将经过第一次通过,指示哪些图元可见以及在何处可见。这为每个图块提供了多个图形处理器必须在顶部渲染的框架,直到我们获得 Destiny 2 帧。(图片来源:英特尔)
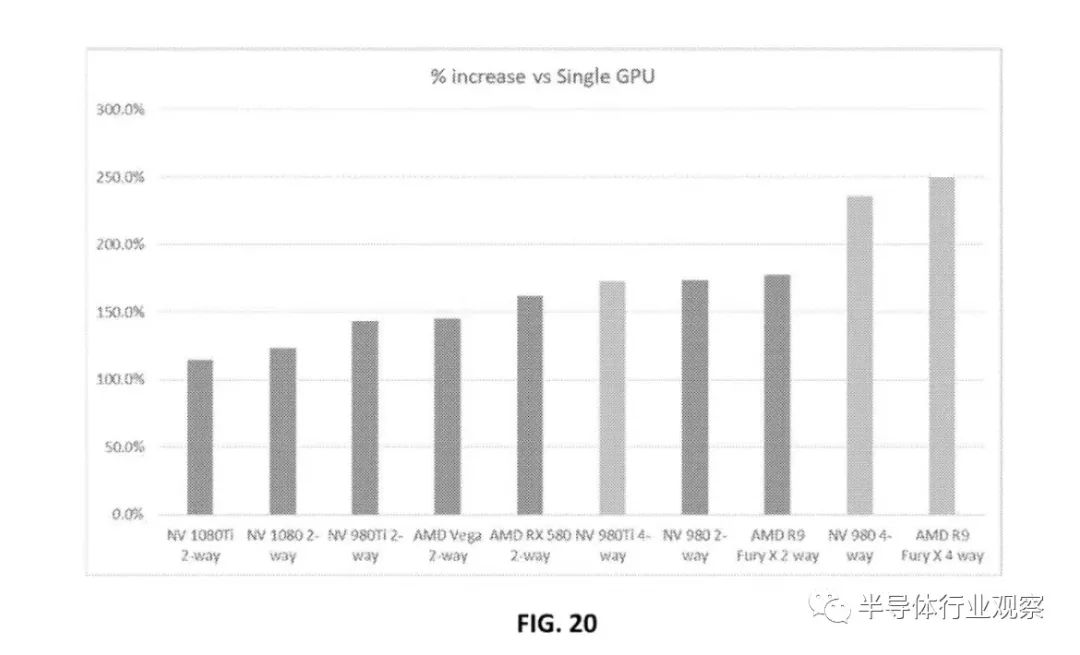
对多 GPU 配置的性能估计——英特尔没有分享任何关于这项专利申请的内部结果,至少可以说这很有趣。(图片来源:英特尔)
然而,英特尔的专利在架构层面的细节上是模糊的,并且涵盖了尽可能多的领域——这在这个领域也是很常见的。例如,它允许设计甚至包括多个协同工作的图形处理器或只是图形处理器的一部分。该方法适用于“单处理器桌面系统、多处理器工作站系统、服务器系统”以及用于移动的片上系统设计 (SoC)。这些图形处理器或实施例,正如 Intel 所称的那样,甚至被描述为接受来自 RISC、CISC 或 VLIW 命令的指令。但英特尔似乎直接从 AMD 的剧本中吸取了教训,解释说他们的 MCM 设计的“中心”
随着半导体微缩的速度放缓(并继续放缓),公司必须找到在保持良好良率的同时扩大性能的方法。与此同时,他们必须在架构上进行创新,半导体制造工艺越来越复杂和奇特,所需的制造步骤越来越多,掩模数量越来越多,最终集成了极紫外光刻 (EUV) 应用。一段时间以来,我们一直在研究等式中的收益递减部分:增加晶体管密度变得越来越难,而进一步增加裸片面积会降低晶圆产量。唯一的解决方案是将几个较小的die配对在一起:拥有两个正常工作的 400 平方毫米die比拥有一个完全工作的 800 平方毫米die更容易。
例如,自第一代以来,AMD 就凭借基于 MCM 的 Ryzen CPU 取得了巨大成功。这家公司仍然提供基于 MCM 的 GPU,但他们的下一代Navi 31 和 Navi 32可能采用该技术。我们也知道 Nvidia 也在积极探索 MCM 设计其未来的图形产品,遵循其新的可组合封装 GPU (COPA) 设计方法。这场竞赛已经进行了很长时间,甚至在 AMD 推出 Zen 之前。第一家部署 MCM GPU 设计的公司应该比其竞争对手更具优势,更高的产量有助于更高的利润,或更低的市场定价。在可预见的未来,由于 AMD、英特尔和英伟达这三家公司都与台积电相同的制造节点签约,每一个微小的优势都可能产生潜在的巨大市场影响。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2944内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!










