
芯片设计上云——弹性计算篇
引言:
心之官则思,思则得之,不思则不得也。
-- 《孟子·告子章句上·第十五节》
1- 弹性计算的需求
在芯片项目研发过程中,随着设计流程的推进,在不同的项目阶段,对算力的需求呈现非线性的需求特征。
项目资源需求曲线
一般来说,后端算力需求大于前端算力需求,以一个开发周期为11个月的14nm芯片项目为例,分别从全项目、全后端、STA这三个需求场景来看,其对算力和存储的需求体现为下面的图表:

图二:项目算力需求曲线
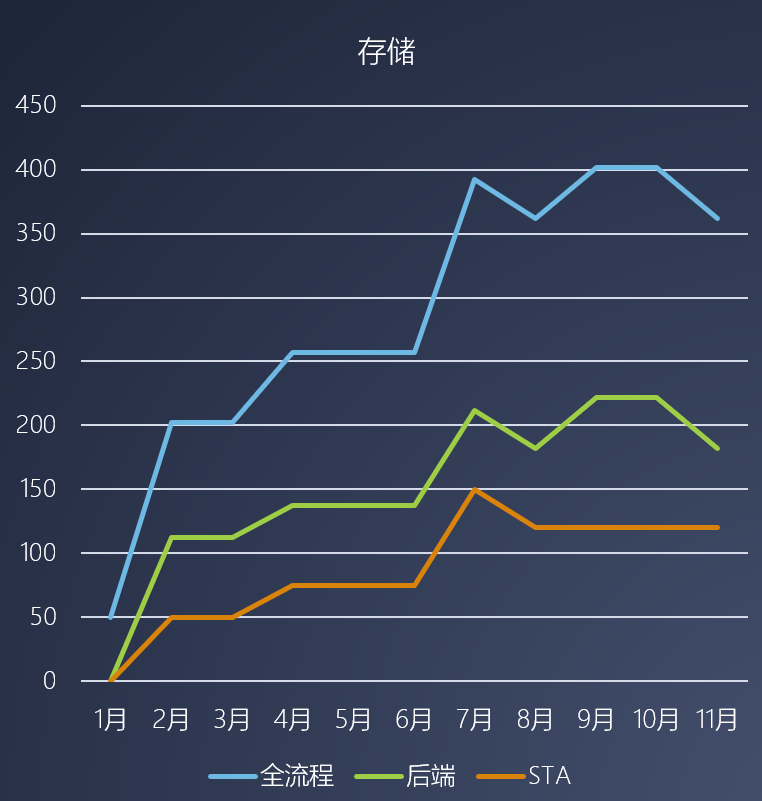
图三:项目存储需求曲线
可以看出,在芯片设计过程中,从成本优化、运维管理、资源调度等方面来说,“弹性计算”是一个不可回避的“刚性需求”。
伴随着2006年“云计算”这个新模式术语的出现,芯片设计上云给芯片设计“弹性计算”的需求提供了一个可行的技术解决方案。随着2016年半导体行业出现典型性上云案例以来,如何实现“弹性计算”就一直是一个吸引从业人员在研究和探索的专题。
从2018年起,笔者基于各大云厂商的芯片设计上云方案进行了大量的测试研究和项目实践,并于2019年和2020年发表了两版关于芯片设计上云的技术白皮书。本文我们将基于Azure的弹性云计算方案进行阐述。

左图:芯片设计云计算白皮书1.0
右图:芯片设计云技术白皮书2.0
2- 基于Azure实现弹性计算方案
在传统的芯片设计环境中,计算平台管理是CAD六大管理核心职能之一,它依赖IT硬件底层的支撑,解决了计算集群配置与运维的核心问题,并与其它五个方面进行配合,从而满足更高效、更安全的大量EDA计算的需要。

图六:CAD管理核心职能图
大多数芯片设计公司仍以本地计算集群为主构建计算平台,他们大多数是采用集群调度工具IBM LSF来搭建整个HPC高性能计算集群。CAD管理内容的其他几个方面,往往也都是基于这样的底层架构来进行定制化管理,包括设计流程自动化、EDA工具与调度工具的集成、设计环境标准化、设计数据管理的标准化、License管理和调度等。
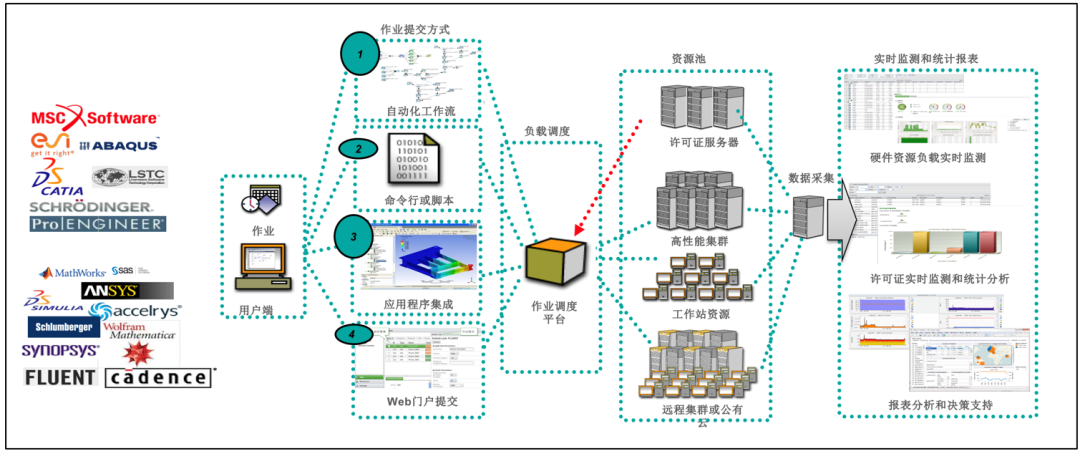
图七:EDA高性能计算平台的逻辑架构图
在本地化的静态计算集群的方案中, IBM LSF这类作业调度工具已经是非常成熟的方法了,在行业中已经沿用了20年。然而对于弹性计算来说,仅仅IBM LSF还不够,还需要云端有一个可以配合的HPC部署和管理工具,将LSF的指令与云端的对象进行联动,才能实现真正的无缝无感的弹性方案。
Azure云平台上提供了一个Cyclecloud工具,Cyclecloud是一个帮助在云上构建HPC系统的工具。它对这些系统进行了编排,使它们能够根据手头的HPC任务灵活地调整大小,而无需管理基本的云构建模块。Cyclecloud是由一个经验丰富的HPC专业团队为HPC管理员和用户设计的,特别是那些希望在云中构建类似他们熟悉的内部HPC基础设施的HPC系统的用户。
Cyclecloud提供了一个丰富的声明性模板语法,使用户能够描述他们的HPC系统,从集群拓扑(集群节点的数量和类型),到将部署在每个节点上的挂载点和应用程序。Cyclecloud设计用于与IBM LSF、PBSPro、Slurm、Sun Grid Engine和htcondor等HPC调度程序一起工作,允许用户在每个调度程序中创建不同的队列,并将它们映射到Azure上不同VM大小的计算节点。此外,autoscale插件与调度器头节点集成,调度器头节点侦听每个系统中的作业队列,并通过与应用服务器上运行的autoscale rest api交互来相应地调整计算集群的大小。
3-Cyclecloud 相关介绍
功能详解
AzureCyclecloud 是在 Azure 中部署 HPC 集群并管理其工作负载的工具。它提供各种 HPC 功能,包括:
基于模板的 HPC 集群部署。AzureCyclecloud 为最常见的作业调度程序(包括 Slurm、OpenPBS、LSF、Grid Engine 和 HTCondor)的部署提供可自定义的内置模板。Cyclecloud GitHub 存储库中提供了许多其他预定义模板,你可以将其导入 AzureCyclecloud 实例中。

图八:Azure CycleCloud用户图形界面
模板是 INI 格式的文件,使用声明性语法来描述节点在Cyclecloud 集群中的组织方式,包括其各自的关系。模板包含对定义节点配置的项目的引用。
手动和自动缩放集群节点。AzureCyclecloud 允许根据作业队列的长度和治理策略,手动和自动对托管集群进行水平缩放。它还提供了用于为自定义作业调度工具开发自动缩放适配器的 REST API。
通过 cloud-init 脚本进行节点配置。AzureCyclecloud 支持基于自定义脚本的配置管理,在所有其他特定于Cyclecloud 的配置任务之前,这些脚本在托管集群节点中运行。
管理内部和外部集群存储。AzureCyclecloud 允许你通过预配、装载和格式化 Azure 托管磁盘和网络连接存储(例如 NFS 服务器或 BeeGFS 集群)来配置集群存储。
监视、记录和警报。AzureCyclecloud 提供内置的集群监视功能,并与 Azure Monitor 集成。还可以将Cyclecloud 集群中的日志数据存储到 Log Analytics 并创建自定义指标仪表板。还可以创建由遥测数据触发的自定义警报和电子邮件通知。所有 AzureCyclecloud 活动都会记录。

图九:Azure CycleCloud集群监控界面
身份验证和授权。AzureCyclecloud 支持内置的本地身份验证。或者,可以将它与 Active Directory Domain Services (AD DS) 或其他基于轻型目录访问协议 (LDAP) 的标识提供程序集成。默认情况下,本地定义的用户可以访问托管集群节点上的操作系统,但也可以单独管理集群用户。
准实时成本报告和控制。AzureCyclecloud 跟踪集群使用情况并估算相应的成本。此功能允许你设置当集群成本超过指定货币金额时触发的预算警报。AzureCyclecloud 也可与 Azure 成本管理集成。
弹性计算集群生命周期
用户可以根据芯片设计需求自定义“弹性计算集群生命周期”:
集群的生命周期从选择包含其定义的模板开始。可选择使用其中一个内置模板,也可以创建一个自定义模板,然后将其导入Cyclecloud 应用程序。该模板通常包含多个参数,可用于在其创建期间自定义集群配置。
创建集群后,可启动它。启动集群将为基于集群模板的定义中的每个节点触发一系列任务。此序列包括对请求预配 Azure VM 的 ARM 的调用,称为“获取”状态。接下来是 VM 的配置,包括执行在相应项目中定义的初始化项,执行脚本以安装和配置计划软件,以及预配和装载文件系统卷。序列完成后,节点将进入“已启动”状态。
集群节点运行后,可以通过作业调度系统提交集群作业。
在集群完成所有已提交的作业后终止集群。终止集群会停止和删除其节点,并删除任何非永久性卷,使集群处于“关闭”状态。
与作业调度系统集成以及自动缩放
自动缩放资源数量以满足用户使用模式是"云计算"敏捷性的核心组成部分,用户可充分利用 Azure 的超大规模功能,同时最大限度地降低与使用计算资源相关的运营成本。通常,作业调度工具(IBM LSF)负责协调集群节点的缩放,Azure Cyclecloud负责向提供计算资源的平台传达其需求。
Azure Cyclecloud 允许将托管集群的自动缩放行为与集群作业队列的长度关联起来,用户可以定义用于控制空闲节点终止前的时间长度或自动停止检查频率等的模板参数,进一步自定义此行为。所有内置模板直接在 Azure Cyclecloud 图形界面中公开自动缩放设置。在每种情况下,这些设置包括用于指定自动缩放范围下限和上限(以 CPU 核心数表示)的选项。上限可最大程度地降低意外收费的可能性。
如果将下限阈值设置为 0,则创建集群只会配置作业调度工具头节点。当作业调度工具检测到已排队的作业时,它将启动执行相应工作负载所需的计算节点的预配,直至达到定义的限制,并将在第一个节点可用时立即开始运行作业。在作业队列清空时长超过了允许的空闲时长后,计算节点将开始自动停止,并且集群将再次只包含作业调度工具头节点。
实现与Azure Cyclecloud自动缩放集成的两个主要组件是AzureCyclecloud自动缩放库和需求计算器。Azure Cyclecloud还提供基于REST API的编程接口和基于Python的客户端库,简化了相应作业调度工具的自动缩放功能的开发。
IBM LSF已利用这些API做了很好的集成,对于LSF管理员来说,只要在LSF的配置文件中做相应的设置,便能在Azure上直接实现“弹性计算”的功能,并且这种“弹性计算”对于用户来说是无感透明的,用户无需关心所使用的计算资源是本地的还是Azure上的。
4- 案例分析
今年我们刚刚帮助一家大型芯片设计公司完成了基于Azure的弹性算力方案,采用的就是LSF 与Cyclecloud的组合工具,实现了一个完全自动化伸缩的动态集群方案

图十:LSF +Cyclecloud案例图
需求背景:
用户ITCAD部门打造混合云,利用本地的机房进行运算,弹性高峰期间会启用云上服务,给设计部门提供灵活的算力供给方案,芯片设计业务以后端设计为主。
采用机型:
E48sv4(48vCPU/384GiB RAM)
M64s(64vCPU/1024GiB RAM)
M128s(128vCPU/2048GiB RAM)
弹性伸缩策略:
1)集群的负载(cpu或者内存使用率)阈值超过90%或者无可用slot时启动新节点安装.
2)针对不同队列或特定任务,配置对应机型:
轻量任务队列Light:E48sv4
中型任务队列Medium:M64s
大型任务队列Lager:M128s
3)集群设定总可使用vCPU核数来限定动态节点数目:
比如将集群总核数限定在5000核,则单E48sv4机型最大可用104台,单M64s机型最大可用78台,单M128s机型最大可用39台。集群中机型共享总可使用核数。
4)静态集群和动态集群的动静结合策略:
将谷峰资源使用量配置为静态部署,波峰资源使用量配置为按需动态生成。
5)动态集群缩容策略:
设定动态计算节点空闲时间可以有效回收资源,节约成本。

图十一:创建动态节点的系统过程
计量计费方法:
CPP+OnDemand 组合:
CPP(Compute Pre-Purchase):年预付费计算实例价格,不同机型具有不同的优惠折扣,所有机型均支持一年CPP,部分机型支持3年CPP。适用固定任务需求场景。
OnDemand(即用即付):标准预付费价格,无最低使用时间限制,适用临时型需求场景。(作者:摩尔精英王汉杰 )
推荐阅读:
信息安全之六大安全要素概述
摩尔云舟,助力芯片客户数据安全管理
芯片设计环境的安全体系概述
芯片上“云”的动力
中国芯片设计云技术白皮书2.0发布
CAD之轮胎说
集成电路IT/CAD设计环境今日与未来
国内半导体差距之IT/CAD篇
随时联系我们 MooreElite
邮箱: info@MooreElite.com;

如果您有
芯片设计
流片封测
教育培训
等业务需求
欢迎随时扫码联系我们
今天是《半导体行业观察》为您分享的第2826内容,欢迎关注。
推荐阅读
★ 一文看懂封装基板
半导体行业观察

『 半导体第一垂直媒体 』
实时 专业 原创 深度
识别二维码 ,回复下方关键词,阅读更多
晶圆|集成电路|设备 |汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复 搜索 ,还能轻松找到其他你感兴趣的文章!
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 青禾晶元携手合作伙伴在半导体器件“奥林匹克盛会”IEDM 2024上发布最新技术突破!
- 2 国产品牌康盈半导体自研存储产品获国际认可,斩获两大国际奖项
- 3 再掀FPGA浪潮,Lattice多款新品重磅发布
- 4 英特尔至强6强势驱动,火山引擎g4il实例性能飙升
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号