来源:内容由半导体行业观察(ID:icbank)编译自「
allaboutcircuit
」,谢谢。
今年举办的特斯拉人工智能日的一大亮点是该公司内部人工智能框架的发布,一款名为 Dojo 的超级计算机。
Dojo 基于自定义计算芯片 D1 芯片打造,它是基于大型多芯片模块 (MCM) 的计算平面的构建块。这些 MCM 将被平铺以创建用于训练自动驾驶 AI 网络的最终超级计算机。
虽然对如此庞大的多学科项目的全面评估超出了单个报道的范围,但从电路设计的角度来看,这里有一些该项目的亮点,特别是在 MCM 级别。
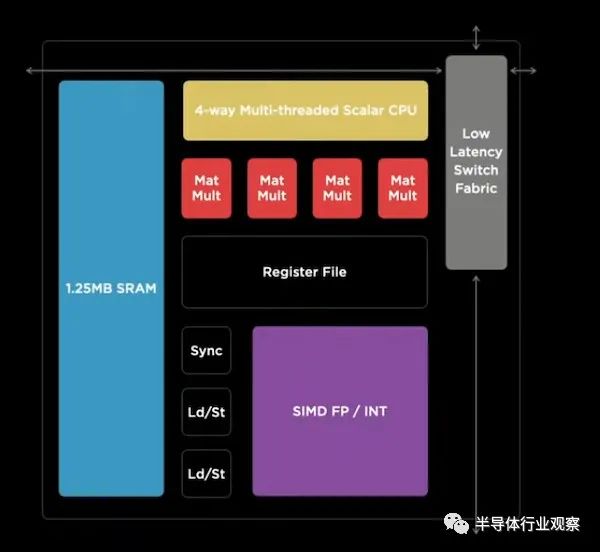
特斯拉提议的超级计算机中使用的最小规模实体称为训练节点。训练节点的框图如下所示。
训练节点是一个 64 位 CPU,针对机器学习工作负载进行了全面优化。它优化了矩阵乘法单元和 SIMD(单指令多数据)指令,并包含 1.25 MB 的快速 ECC 保护 SRAM。
尽管这是 Dojo 中使用的最小计算元素,但它能够进行超过 1 teraflop 的计算。训练节点的物理尺寸是根据信号在所需时钟频率的一个周期内可以传播的最远距离来选择的——在特斯拉的设计中约为 2 GHz。
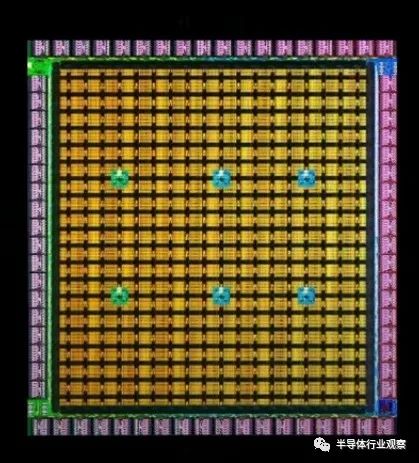
训练节点采用模块化设计。通过使用这些训练节点的阵列,可以创建更大的计算平面。
D1 芯片由 354 个训练节点组成的阵列创建。其能实现362 teraflops 的机器学习计算。
训练节点之间的通信带宽(或 D1 的片上带宽)为 10 TBps。该芯片集成了 576 个高速、低功耗 SerDes 单元,支持 4 TBps/边缘的 IO 带宽。IO带宽是D1芯片最重要的特性之一。
据特斯拉称,D1的IO带宽大约是最先进的网络交换芯片的两倍。下图比较了新芯片和未指定的可比解决方案的 IO 带宽与计算的 teraflops。
一些高性能 ML 解决方案的 IO 带宽与计算的 teraflops
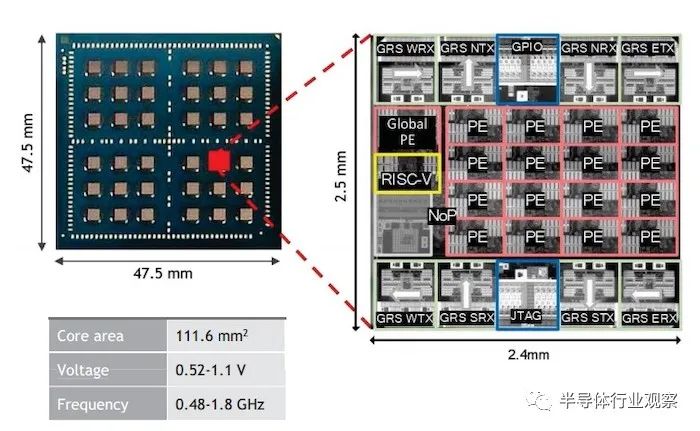
D1 采用 7 nm 技术制造,芯片面积为 645 mm 2。芯片的热设计功率 (TDP) 为 400 W。
D1 芯片提供了一些有趣的特性,例如高 IO 带宽,毫无疑问,我们在创建它时付出了很多努力。然而,到目前为止,该项目的真正挑战之一将是将大量 D1 芯片连接在一起,以创建具有优化带宽和最小延迟的超级计算机。
在正常的 IC 设计流程中,D1 芯片在经过晶圆级测试后会被分割和封装。然后,这些封装好的芯片将被焊接到 PCB 上以创建一个更大的系统。然而,在这种情况下,芯片之间的通信将通过芯片的 IO 和 PCB 走线发生。这就让芯片出现较低带宽和增加延迟的地方。
封装将芯片连接到系统的其余部分;然而,他们以一种非常低效的方式这样做。片上互连间距约为几微米,而 BGA 间距为 400-600μm。电路板走线间距也通常在 50-200μm 范围内。这些大的片外间距限制了封装可以具有的 IO 数量。
此外,只有有限数量的芯片凸点分配给 IO。例如,在具有 10,000 个凸点的处理器中,可能只有 1,000 个凸点分配给 IO。由于封装 IO 是有限的,我们无法在两个封装的裸片之间进行并行通信。我们必须通过 SerDes 单元对信号进行序列化、传输和反序列化。在典型的处理器芯片中,SerDes 电路通常会占用很大的面积(约占芯片面积的 25%)并消耗大量功耗(约占总功耗的 30%)。
处理器和片外存储器之间的通信也面临类似的挑战。此外,IO 电路会增加信号路径延迟并增加系统延迟。如您所见,封装以多种不同方式对设计产生不利影响。因此,如果我们可以在不封装的情况下将裸片相互连接,我们就可以实现更并行的通信(即更高的带宽),同时减少延迟、面积和功耗。
解决 IO 问题的一种方法是多芯片模块技术,其中多个die和/或其他分立元件集成到统一基板上。应用这种技术,我们可以实现具有最大芯片到芯片通信速度的高性能处理器。
特斯拉的Dojo就是基于这个想法设计的;不过需要注意的是,这并不是特斯拉的创新。例如,NVIDIA 已经实施了一个可扩展的基于 MCM 的深度神经网络加速器,以最大限度地提高芯片到芯片的通信速度。
训练tile是 Dojo 超级计算机的缩放。它是由 25 个 D1 芯片组成的 MCM。这些 D1 芯片使用扇出晶圆工艺紧密集成,从而保留了裸片之间的带宽。
这个 MCM 有什么特别之处?据特斯拉称,这可能是芯片行业最大的 MCM。
要了解这个 MCM 有多大,请考虑一个典型的基于 MCM 的解决方案,例如上面提到的 NVIDIA 处理器。NVIDIA MCM 尺寸约 2256 mm 2;相比之下,Dojo 训练tile大于 25 ✕ 645 mm 2 (约 16125 mm 2)。Dojo 训练tile至少比 NVIDIA 处理器大七倍。
如此大的 MCM 可能存在热和功率传输问题。如前所述,D1 芯片的热设计功率 (TDP) 为 400 W。25 个 D1 芯片紧密排列,仅处理器可以燃烧多达 10 kW。这没有考虑电压调节器模块消耗的功率,这可能很重要。
在大型 MCM 中,设计应该能够在相对较小的空间内安全地耗散如此大量的功率。由于热和电力输送方面的问题,特斯拉工程师不得不寻找一种新的方法来为 D1 芯片供电。
如此大的 MCM 的另一个挑战是良率问题。对于更大的设计,产量可能会更低。D1 芯片是“已知良好”的芯片。这意味着它们在放入 MCM 之前已经过全面测试。因此,晶圆的互连结构应该是这里主要的良率问题。
此外,CAD 工具不支持如此大的 MCM 的设计。就连特斯拉的计算机集群也处理不了。工程师们不得不寻找新的方法来解决这个问题。
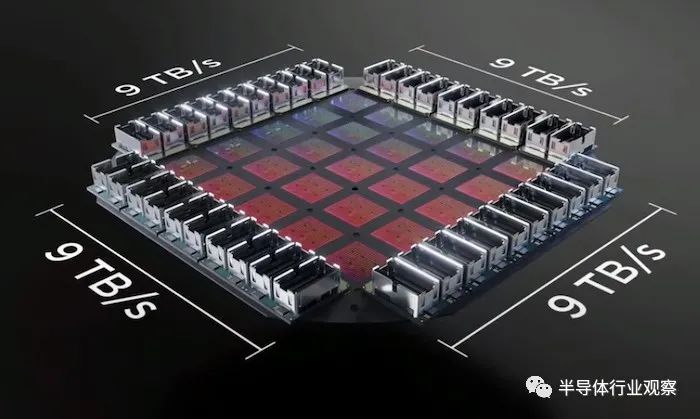
为了保持tile之间的高带宽,特斯拉创建了一个高密度、高带宽的连接器,围绕着训练tile,如下图所示。
Dojo 训练tile提供 36 TB/s 的ti le外带宽
训练tile提供 9 PFLOPS 的计算和 36 TB/s 的tile外带宽。为了给 MCM 供电,Tesla 工程师构建了定制的电压调节器模块,可以直接回流到扇出晶圆上。
这种为芯片供电的新方法应该会减少配电所需的晶圆金属层的数量,从而实现更具成本效益和紧凑的设计。在下一步中,工程师集成了机械和热部件,以得出所谓的完全集成的解决方案。
由于冷却和电源与计算平面正交,工程师们在不损失带宽的情况下创建了更大的计算平面。
特斯拉尚未将整个系统整合在一起。到目前为止,只有训练tile——Dojo 超级计算机的主要构建块——已经实现。这些训练tile中的 120 个将被排列起来,以实现一台能够达到 1.1 EFLOP 的超级计算机。
不过,马斯克认为,Dojo超级计算机将在明年全面投入使用。
你觉得这个项目怎么样?您认为 Dojo 超级计算机可以在带宽和延迟方面击败现有解决方案吗?
★ 点击文末
【阅读原文】
,可查看本文原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2786内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|台积电|AI|封装
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!