
英伟达让AI可以富有情感的说“人话”
人工智能正在推动全球各个行业的变革。在现实生活中,我们经常能听到一些机器人的“机言机语”,这其中不乏有AI语音技术的参与,但真人对话和机器合成的语音对话还是有很大的出入,这是因为人在说话时会有复杂的节奏、音调和音色,而AI很难在这些方面进行模仿。而作为AI领域的佼佼者,英伟达正在开发一种人工智能技术,可以像真人一样表达。
就在近日召开的INTERSPEECH 2021大会上,英伟达展示了其高质量、可控制的新的AI语音合成模型和工具,这些模型和工具能够捕捉人类语音的丰富性,并且不会出现音频杂音。
RAD-TT模型:可将任何文本转换成人声
在过去的一年中,NVIDIA文本-语音研究团队开发出更强大、更可控的语音合成模型,如RAD-TTS。NVIDIA在SIGGRAPH Real-Time Live比赛中的获奖演示就采用了这个模型。通过使用人类语音音频来训练文本-语音模型,RAD-TTS可以将任何文本转换成说话人的声音。
英伟达已将其AI语音合成模型用于I AM AI系列视频中。I AM AI系列视频是2017 GTC主题演讲中作为合成语音的应用实例。直到最近,该视频系列的旁白都由人类配音的,但现在该视频中使用的女声正是使用该语音合成技术生成的。下面是一些列的演示:

David Weissman将台词读入麦克风
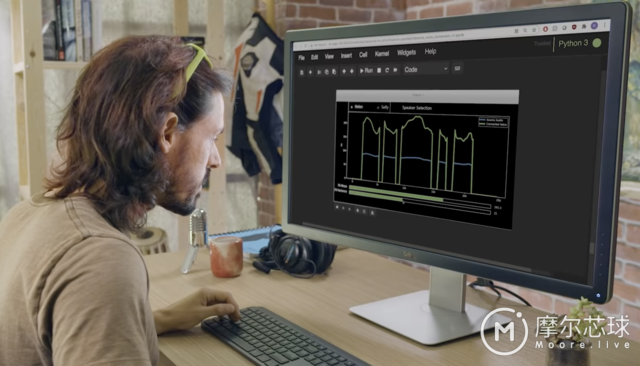
工程师使用 AI 模型来转换语音
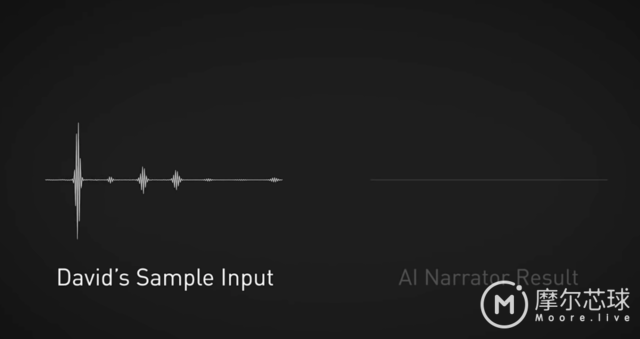
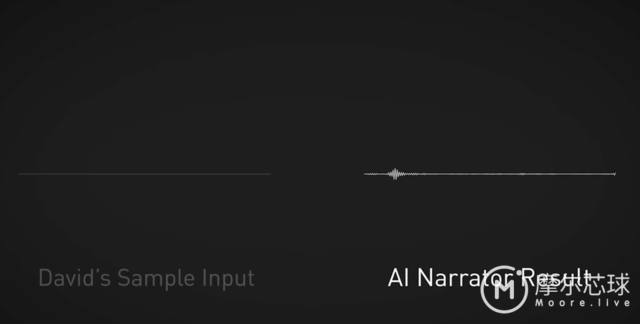
接着David Weissman的叙述就被翻译成女性叙述者的声音,而且声音很近似人声,再现的非常流畅。还可以像人类一样强调特定的单词,或者更改叙述速度以此来与视频想匹配。
该模型的另一项功能是语音转换,即使用一名说话人的声音讲述另一名说话人的话语(甚至歌唱)。RAD-TTS界面的灵感来自于将人的声音作为一种乐器这一创意。用户可以使用它对合成声音的音调、持续时间和强度进行精细的帧级控制。
英伟达也指出,可能的应用不仅仅是视频中展示的简单的画外音工作,例如帮助有声音障碍的人或帮助人们用自己的声音在语言之间进行翻译。人工智能模型甚至可以用来重现标志性歌手的表演,不仅匹配歌曲的旋律,还匹配人声的情感表达。
NeMo工具包让开发者玩转语音
熟悉英伟达的都知道,其每一项技术的背后都少不了工具包的支持。在AI语音合成领域自然也不是例外。为了给AI开发者和研究者提供强大的语音功能,英伟达推出了NeMo,这是一款用于GPU加速对话式AI的开源Python工具包。研究者、开发者和创作者通过使用该工具包,能够在自己的应用实验和和微调语音模型方面取得先机。
NeMo中易于使用的API和预训练模型能够帮助研究人员开发和自定义用于文本-语音转换、自然语言处理和实时自动语音识别的模型。其中几个模型是在NVIDIA DGX 系统上使用数万小时的音频数据训练而成。开发者可以根据自己的使用情况对任何模型进行微调,运用NVIDIA Tensor Core GPU上的混合精度计算加快训练速度。
值得一提的是,NVIDIA NeMo 中包含的 AI 模型已经在NVIDIA DGX 系统上进行了数万小时的音频数据训练,并在NVIDIA GPU 的 Tensor 核心上运行。此外,NVIDIA NeMo 还提供了一个使用 Mozilla Common Voice 学习的模型,这是一个包含 76 种语言的约 14,000 小时语音数据的数据集。“凭借世界上最大的开放语音数据集,我们的目标是实现语音技术的大众化,”NVIDIA 表示。
AI语音的下一步
不过,情感语音合成只是英伟达研究院万里长征的一小步,Nvidia 应用深度学习研究副总裁 Bryan Catanzaro 在新闻发布会上表示,语音研究是该公司的一个战略领域,因为它实际上有数十种潜在应用,从视频会议中的实时字幕到医学转录、聊天机器人与语音接口等等。“我们觉得现在是让这些技术更有用的好时机,”他说。
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 复杂SoC芯片设计中有哪些挑战?
- 2 进迭时空完成A+轮数亿元融资 加速RISC-V AI CPU产品迭代
- 3 探索智慧实践,洞见AI未来!星宸科技2024开发者大会暨产品发布会成功举办
- 4 重磅发布:日观芯设IC设计全流程管理软件RigorFlow 2.0
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号