
Graphcore的AI芯片什么水平?MLPerf告诉你!
2021-07-06
14:27:12
来源: 互联网
点击
在近几年兴起的的AI芯片市场里,有一家初创公司在全球名声大噪,那就是起源于英国的Graphcore。
Arm联合创始人Hermann Hauser曾经表示,在计算机历史上只发生过三次革命,第一次是70年代的CPU,第二次是90年代的GPU,而第三次革命,则来自于IPU。这个“新兴”的IPU,就是由Graphcore公司打造的Intelligence Processing Unit的简称。
Graphcore IPU:第三类处理器
Graphcore的CEO Nigel Toon也指出,现在的AI硬件有三类解决方案:第一类是一些非常简单的小型化加速产品,应用于手机、传感器或摄像头中;第二类是ASIC,这是一些超大规模的公司为解决超大规模的问题而研发出的产品,比如谷歌的TPU就属这类。这些产品旨在用数学加速器解决问题。
第三类是可编程的处理器(Programmable Processor)。在Nigel Toon看来,这类市场目前还是GPU的天下。“我认为Graphcore也隶属这类市场,未来Graphcore在这个市场会产生非常多的应用场景,通过不断创新赢得更多市场份额。”Nigel Toon进一步指出,“Graphcore要做的是一个非常灵活的处理器,一个从零开始专门针对AI而生的处理器。”这也正是上文谈到的IPU。
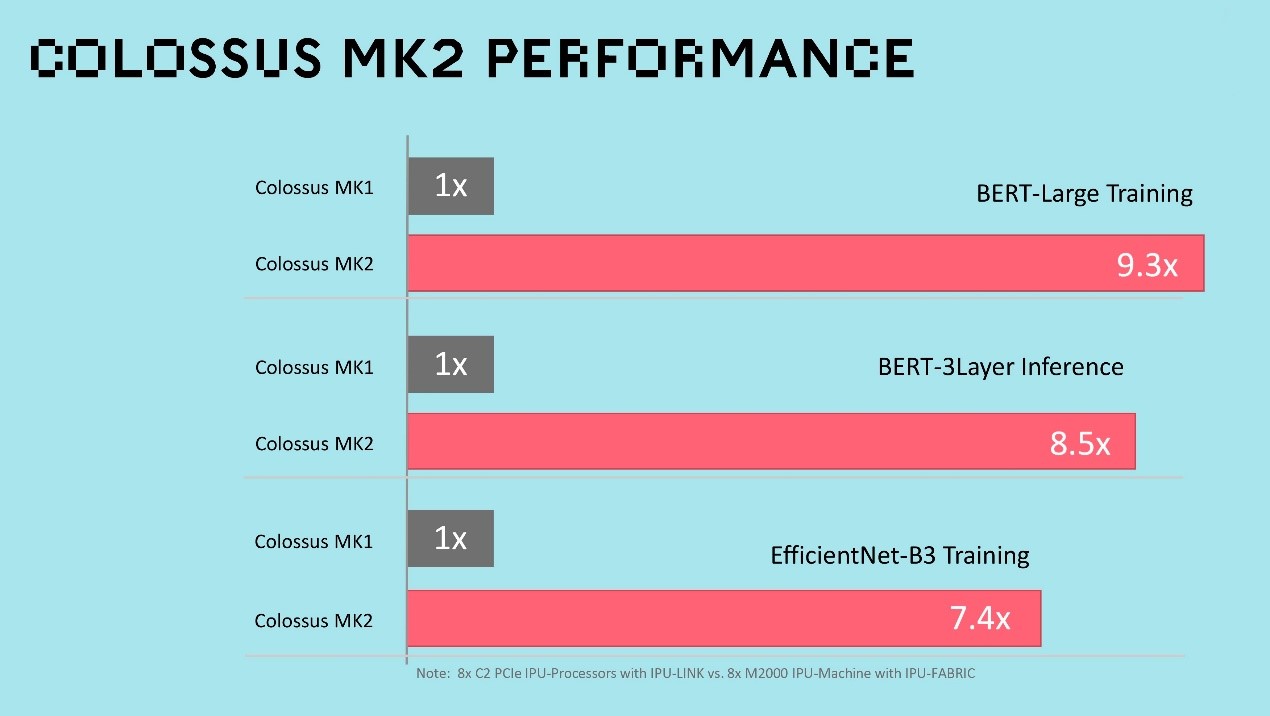
继2019年推出第一代的IPU之后,Graphcore在2020年又带来了新一代的IPU产品Colossus MK2。据介绍,与第一代IPU(MK1 IPU)相比,第二代IPU(MK2 IPU)实际性能提高了8倍。公司基于此打造的革命性系统解决方案IPU-M2000能以纤薄的1U尺寸提供1 PetaFLOPS的AI计算和高达450GB的Exchange-Memory。
得益于其具有智能工作负载的巧思设计,IPU-M2000能提供从一个到几个的扩展性。搭配接近零时延的IPU-Fabric,IPU-M2000可以作为一个独立的系统工作,或者8个堆叠在一起,也可以在IPU-POD64系统中将16个连接的IPU-M2000扩展到超级计算规模。
如上所述,从Graphcore提供的数据中,公司的这些芯片和系统不但获得了惊人的提升,在客户端也获得了高度的认可。这种情况在多家其他公司的AI芯片产品上,也同样出现。但和CPU以及GPU这些经历了多年考验的产品不一样,大多数AI芯片在做对比的时候,并没有统一的标准来衡量,而MLPerf的出现正是为了解决这个问题。
MLPerf:AI芯片的Benchmark
所谓MLPerf,据介绍,这是一套由MLCommons提出的,用于测量和提高机器学习软硬件性能的国际基准。自提出以来,该基准获得了亚马逊、Arm、百度、谷歌和微软等40多家公司和研究人员的支持。在实际使用中,它将主要用来测量训练不同深度神经网络所需要的时间,这些神经网络所执行的任务包括物体识别、语言翻译以及经典的下围棋等。
相关介绍也指出,MLPerf的努力旨在构建一组通用的基准,使机器学习(ML)领域能够测量从移动设备到云服务的训练和推理的系统性能。在MLPerf官方看来,一个被广泛接受的基准测试套件将使整个社区受益,当中包括研究人员、开发人员、机器学习框架的构建者、云服务提供商、硬件制造商、应用程序提供商和最终用户。
Graphcore高级副总裁兼中国区总经理卢涛在日前接受媒体采访时也指出,全球有各种各样的处理器,也有各种各样衡量性能的维度,所以在对比不同处理器的时候,所对比的维度可能不尽相同。

Graphcore高级副总裁兼中国区总经理 卢涛
“MLCommons所提出的各种基准测试(Benchmark)是想定义一些业界相对来说有一定实际应用的、有一定代表意义的任务,比如数据集是什么样的?使用什么样的优化器?达到什么样的精度?”,卢涛强调。他进一步指出,各方基于这些要求进行基准测试,这从某种意义上说将大家拉到了同一个维度里进行对话,对于业界有较大的参考意义。例如用户在选择一个新的AI处理器时,可能就不用特别关注各个厂商的基准测试之间的差别。
在这种思路支持下,Graphcore首次参与了MLPerf并提交了结果。数据显示,Graphcore产品表现优异,AI性能稳居领先地位。
初战告捷:AI性能稳居领先地位
据卢涛介绍,Graphcore今年提交的MLPerf训练1.0版本的任务包括了两个模型:一是计算机视觉模型ResNet-50,二是自然语言处理模型BERT。
“之所以选择这两个模型,是因为它们在相应领域里面颇具代表意义,且被广为使用。今天的许多视觉模型,其骨干网络还是基于ResNet;至于BERT,虽然现在有各种各样的BERT变种版本,但是一个标准的BERT还是大家比较认可的Benchmark基准。所以此次我们提交了这样两个任务。”卢涛接着说,“我们提交的硬件也包括两个,分别是IPU-POD16和IPU-POD64。”
据介绍,这两个硬件形态都是基于Graphcore的基础构建块IPU-M2000进行不同配置组合的。其中IPU-POD16是由4个1U的IPU-M2000加上一个双路服务器(Dual-CPU Server)构成的,可以提供4 PetaFLOPS的AI计算;另外一个硬件形态IPU-POD64是由16个IPU-M2000组成,配置了四台双路服务器。在做ResNet相关工作的时候用了4台,而在做BERT相关工作的时候只用了其中1台x86的服务器。
在IPU-POD16和IPU-POD64上,Graphcore都提交了ResNet-50和BERT两个训练任务的结果。
Graphcore方面表示,MLPerf测试包含开放分区和封闭分区两个提交分区。封闭分区严格要求提交者使用完全相同的模型实施和优化器方法,包括定义超参数状态和训练时期。开放分区保证和封闭分区完全相同的模型准确性和质量,但支持更灵活的模型实施以促进创新。因此,该分区支持更快的模型实现,更加适应不同的处理器功能和优化器方法。对于像Graphcore IPU这样的创新架构,开放分区更能体现出产品的优异性能,但Graphcore还是选择在开放和封闭分区都进行了提交。
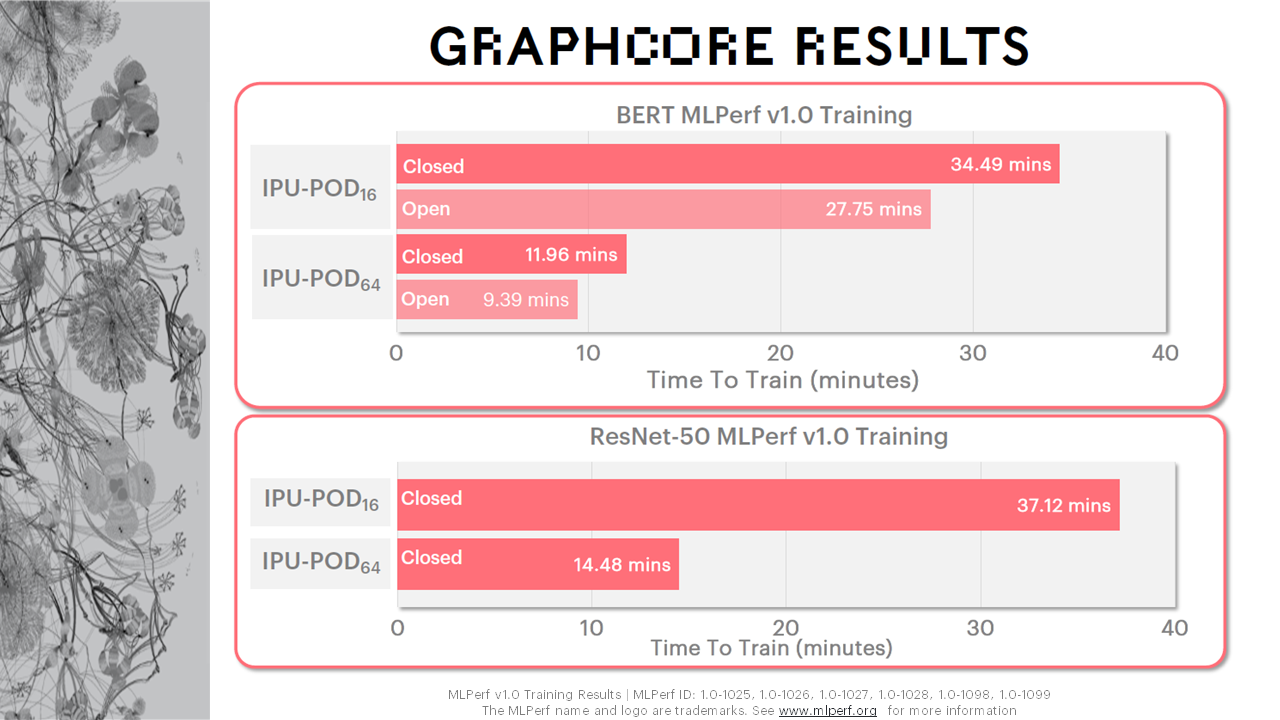
Graphcore中国工程总负责人、AI算法科学家金琛则同时指出,如图所示,在IPU-POD16上,BERT在MLPerf v1.0 Training开放分区(Open Division)中的训练时间(Time To Train)基本上是小于半个小时的。而在IPU-POD64上,其Scaling Factor基本上可以达到3.5倍,在开放分区提交中的训练时间基本上是小于10分钟的,这对于很多科研工作者来说是非常令人兴奋的一个消息,这意味着在训练过程中他们可以更快地得到研究结果。

Graphcore中国工程总负责人 AI算法科学家 金琛
除了性能的对比外,MLPerf还对比了市面上的Graphcore系统与NVIDIA的最新产品,结果证实Graphcore在“每美元性能”(Performance-Per-Dollar)指标上稳居领先地位。对客户而言,这项重要的第三方测试确认了Graphcore系统不仅具有新一代AI的优异性能,同时在目前的广泛应用中也表现得更出色。

据介绍,Graphcore的IPU-POD16是一个5U的系统,标价149,995美元。如前所述,它由4个IPU-M2000加速器以及行业标准主机服务器构成。每个IPU-M2000由4个IPU处理器构成。MLPerf中使用的NVIDIA DGX-A100 640GB是一个6U机盒,标价约为300,000美元(基于市场情报和公布的经销商定价),有8个DGX A100芯片。IPU-POD16的价格是它的一半。在这个系统中,IPU-M2000的价格和一个DGX A100 80GB的价格是一样的,或者在更细的层次上,一个IPU的价格是它的四分之一。

在MLPerf比较分析中,Graphcore采用了严格监管的封闭分区的结果,并针对系统价格对其进行了归一化。对于ResNet-50和BERT,很明显Graphcore系统提供了比NVIDIA产品更好的每美元性能。在IPU-POD16上进行ResNet-50训练的情况下,Graphcore的每美元性能是NVIDIA的1.6倍。在BERT上,Graphcore的每美元性能是NVIDIA的1.3倍。Graphcore系统的经济性可以更好地帮助客户实现其AI计算目标,同时,由于IPU专为AI构建的架构特点,Graphcore系统还可以解锁下一代模型和技术。
卢涛强调,公司这次的MLPerf结果,佐证了Graphcore IPU的强大。公司后续也会持续提交MLPerf的结果,为追求更优性能、更大规模和添加更多模型,贡献Graphcore的所有智慧和力量。
责任编辑:sophie
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 共筑国产汽车芯片未来,中国汽车芯片联盟全体大会即将开启
- 2 国产EDA突破,关键一步
- 3 英特尔至强6强势驱动,火山引擎g4il服务器性能飙升
- 4 汽车大芯片,走向Chiplet:芯原扮演重要角色
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号