[原创] MLPerf跑分:Nvidia领跑,中国力量正在崛起
2021-07-05
14:00:03
来源: 半导体行业观察
六月底,MLPerf公布了最新的人工智能模型训练在不同的芯片上的跑分结果。该结果也是第一个正式版(版本号1.0)的结果,因此是我们比较各个芯片运行人工智能训练性能非常好的一个平台。
首先我们简单回顾一下MLPerf的背景。随着人工智能应用的崛起,其在不同的硬件芯片平台上的性能也逐渐变成了比较不同硬件和芯片的重要参考。然而,最初由各个芯片厂商自行公布的跑分结果往往很难直接比较,因为其中包括了许多不同的参数,例如模型版本(例如同一个ResNet50可以延伸出许多不同的版本,不同厂商可能会选取对自己芯片最有利的版本来做跑分),模型数字精度(浮点数还是整数)等等。在这种情况下,MLPerf就出现了,该跑分(benchmark)平台是一个由第三方机构(MLCommons)维护的平台,该第三方机构根据目前人工智能领域的发展,选取出数个具有代表性的标准人工智能模型(包括机器视觉领域的ResNet,Mask R-CNN,自然语言处理领域的BERT,推荐系统领域的DLRM等)以供有需要的机构做测评。不同的机构则可以上传这些标准模型在自己的硬件芯片上的跑分结果,并且由MLCommons收集并验证后统一公布在网站上。这样一来,不同硬件芯片平台在做AI模型跑分的时候,就可以有一个统一的模型,也可以直接相互比较。
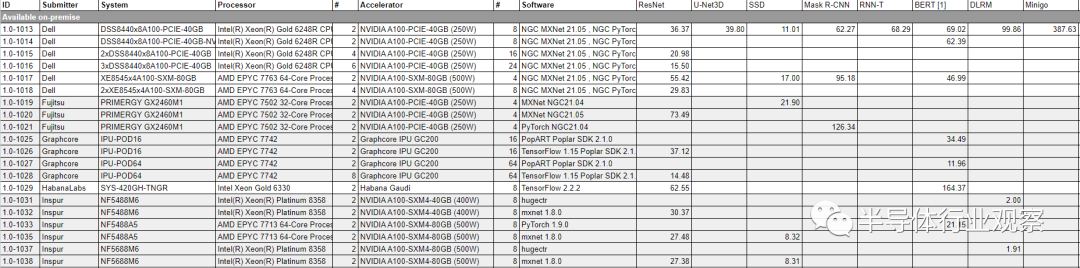
目前,MLPerf公布的跑分结果已经成为了业界的主流AI模型硬件性能指标。在这次最新公布的1.0版本AI模型训练结果中,既包括了主流GPU(Nvidia A100)的结果,也包括了Habana Gaudi,Graphcore IPU等来自初创公司AI加速芯片的结果,还有来自Google TPU和华为Ascend这样的来自巨头公司的自用ASIC的结果。此外,在结果部分也大体可以分为两类,一类是单机多卡训练结果,该结果主要突出芯片本身的性能;另一类是多机分布式训练结果,该结果则体现了芯片以及系统对于分布式计算的支持。
在MLPerf公布的单机训练结果主要包括Nvidia A100、Habana Gaudi以及Graphcore IPU的结果(谷歌的TPU和华为Ascend仅公布了多机训练结果)。从结果来看,Nvidia的下一代GPU A100性能仍然很强。
我们可以比较Habana Gaudi(目前Habana已经被Intel收购,因此可以认为是Intel出品的AI加速器)和Graphcore IPU相对于Nvidia A100的性能。在机器视觉类任务(在ImageNet数据集上训练ResNet50)的结果中,Habana Gaudi在使用八个加速器核心时训练需要62分钟,该结果与使用4张Nvidia A100 GPU所需要的时间接近。而在BERT训练任务中,Habana Gaudi的八加速卡训练结果甚至比4张A100还要慢三倍以上。对于Graphcore,使用16个加速器在机器视觉任务上性能大约与Nvidia 8张A100性能接近,而在自然语言处理(BERT)任务中则与4张A100接近。有趣的是,Graphcore还公布了使用64张IPU的结果,该结果与使用16-24张A100的结果比较接近。根据现有数据,尚不清楚使用64张IPU需要使用几台机器来实现。
从目前结果来看,至少在训练任务中,来自Habana和Graphcore的AI加速芯片与Nvidia最新的GPU的单卡性能处于同一数量级,同时在某些任务(例如自然语言处理)中Nvidia的GPU有更大的单芯片性能优势。由于没有公布大规模分布式训练的结果,我们还不清楚这些AI加速卡能否咋大规模训练的极限性能上超越Nvidia。
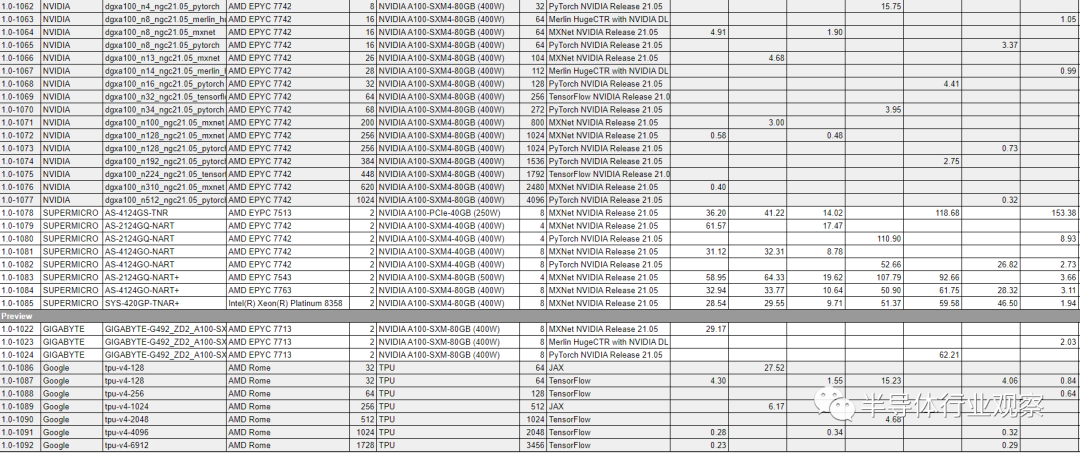
除了单机(单芯片)性能之外,AI模型的训练任务还关心分布式训练的极限性能。随着人工智能模型越来越复杂(例如GPT-3这样的超大型模型出现并成为主流),越来越多的人工智能模型需要能使用分布式计算才能完成训练,单机训练要么速度太慢(例如需要几个月才能完成),或者甚至根本无法装下模型。在分布式训练中,理想情况下训练速度与分布式机器的数量呈线性关系,但是现实中随着分布式机器数量上升,机器之间互相通信的开销越来越大,最终其训练速度会在机器数量增加到一定数量时达到饱和,即再继续增加机器数量也不会显著改善训练速度。这种训练速度的饱和值我们不妨称作极限性能。
在本次MLPerf公布的结果中,我们发现Nvidia和谷歌的TPU在大规模分布式训练性能(尤其是极限性能)方面旗鼓相当(谷歌在MLPerf中仅仅公布了TPU的分布式训练结果,并没有公布单机训练结果),甚至我们还可以发现谷歌在大规模训练的系统设计方面略胜一筹。
在极限性能方面,谷歌TPU在使用2048张TPU时在训练BERT时的性能和Nvidia使用4096张A100时几乎一致(同时如果使用3456张TPU可以将训练速度提升10%不到,可见该训练速度基本已经是极限性能)。值得注意的是,当使用64张TPU时,谷歌训练BERT的速度要比使用64张A100的训练速度慢20%左右。这意味着Nvidia的A100 GPU的性能在分布计算数量较少时优于TPU,但是当分布式数量上升时,基于TPU的系统性能在逐步追上,最后仅仅需要使用更少的TPU(2048)即可实现与更多A100 GPU(4096)相同的极限性能。我们认为这体现了谷歌在分布式计算领域的深厚积累,包括从系统架构定义,底层软件优化到相关的芯片设计优化上。
最后,值得我们关注的是北大和鹏城实验室基于华为Kunpeng CPU+Ascend加速卡+mindspore软件框架的分布式训练结果。
从结果来看,在自然语言处理领域,BERT训练结果的跑分华为Ascend 128卡的结果与介于64卡Nvidia A100和64卡TPU之间,而在机器视觉领域,Ascend 1024卡的结果与A100 1024卡的结果接近。我们认为这是一个非常优秀的结果,证明中国在AI计算领域处于全球领先水平。分布式训练并不是一个容易的领域,它需要芯片、系统和软件的深度协同设计和调优,而MLPerf的结果中,CPU、AI加速卡、机器学习软件框架以及分布式机器设计全部来自中国且能实现与Nvidia、谷歌等全球最高水准可媲美是一件值得我们自豪的事情。
展望未来,机器学习领域的芯片性能通常对于半导体工艺较为敏感,需要最好的工艺才能实现最强的单芯片性能。但是,如前所述,大规模分布式计算的极限性能(以及分布式计算规模较大时的性能)不仅仅取决于单芯片性能,还取决于整个系统设计。因此,即使已知无法使用最先进的工艺实现最强的单芯片性能,大规模分布式计算领域仍然是值得长期投入的领域,因为结合优化的系统设计,有可能可以弥补单芯片性能的短板。希望中国半导体芯片业界和人工智能系统设计行业可以进一步在这个领域加强合作并推动技术进步,我们认为该领域中国在未来有相当大的潜力。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2726内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|MLCC|英伟达|模拟芯片
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!
责任编辑:Sophie