来源:内容由半导体行业观察(ID:icbank)编译自「
HPCWIRE
」,谢谢。
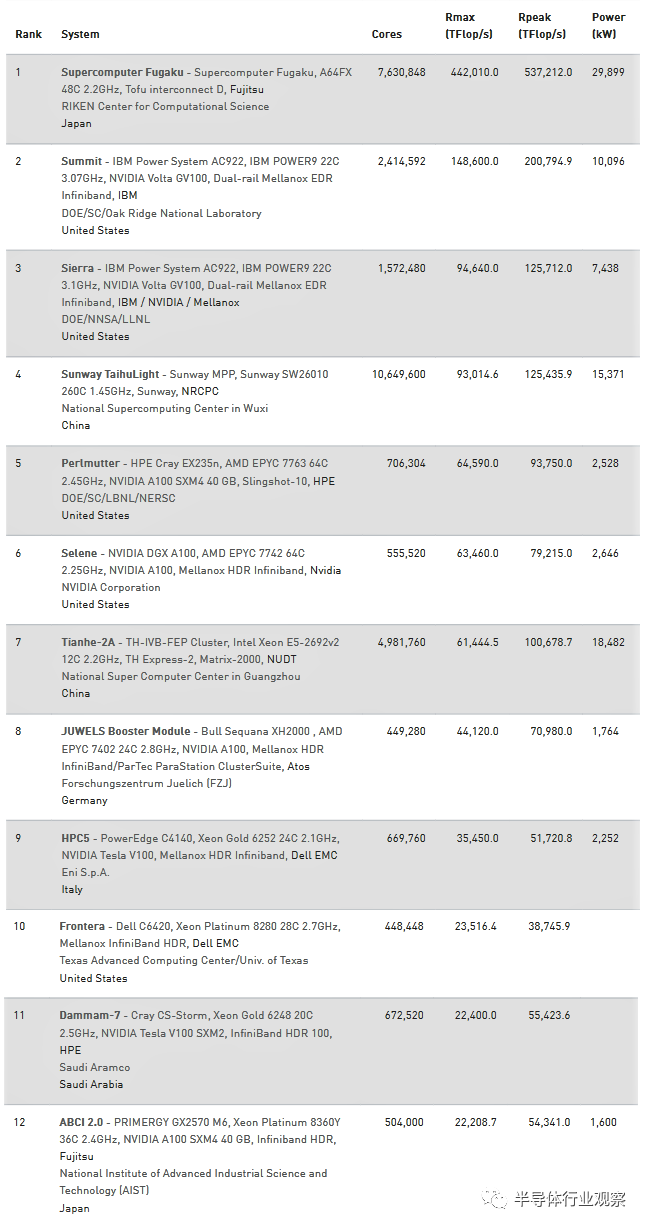
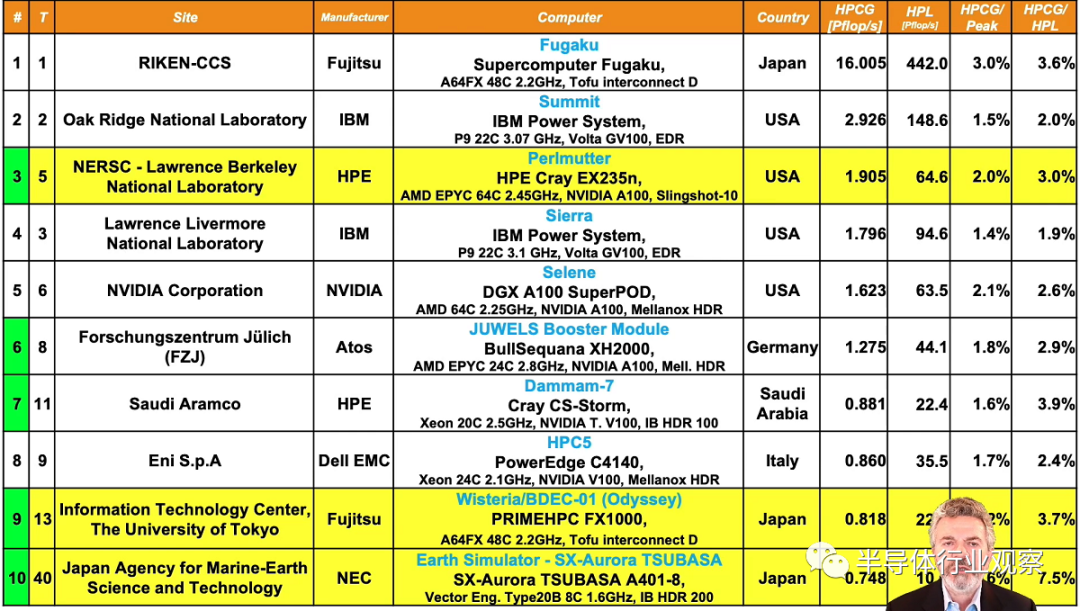
在今天举办的ISC 2021 数字活动中,第 57 届 Top500超算榜单被正式公布。从榜单中我们看到了许多与上一届相同的名字,其中,日本Fugaku 保持着显著的领先地位,并且在前 10 名中只有一个新进入者。那就是美国能源部劳伦斯伯克利国家大学的 Perlmutter 系统实验室,它以 65.69 Linpack petaflops 位列第五。Perlmutter 是迄今为止最大的 Nvidia A100 GPU 系统和最大的 HPE Cray EX 系统(公开,基于以前称为“Shasta”的架构)
日本的 Fugaku 系统以 442 Linpack petaflops 保持其王冠。在Riken安装了一年多,基于富士通 Arm 的机器在对抗 COVID-19的斗争中发挥了重要作用。Fugaku 还在同时发布的 HPCG、Graph500 和 HPL-AI 基准测试中保持领先优势。
Summit 和 Sierra(IBM/Mellanox/Nvidia,美国)分别保持在第二和第三位。橡树岭国家实验室的 Summit 声称为 148.6 petaflops,而劳伦斯利弗莫尔国家实验室的 Sierra 提供了 94.6 petaflops。Sunway TaihuLight(神威太湖之光,中国)以 93 petaflops 稳居第四。
第五个位置由Perlmutter 获得,安装在伯克利实验室的国家能源研究科学计算中心 (NERSC)。HPE Cray EX 系统由 AMD Milan CPU 和 Nvidia A100 40GB GPU 驱动,并通过 HPE 的 Slingshot 技术连接。与 Saul Perlmutter 同名,该系统在 93.75 petaflops 的潜在峰值 (rPeak) 中提供了 65.69 Linpack rMax petaflops,达到了 70% 的 Linpack 效率。请注意,rPeak 与系统的营销峰值约 62 双精度标准 IEEE petaflops(仅 GPU 提供 59.6 petaflops)不同;因此,与 Selene 一样,我们看到一个由 Nvidia 驱动的系统返回的Linpack 分数高于其营销峰值。
排名第六的是英伟达的 Selene 系统。Selene在 79.22 petaflops 的 rPeak 中提供了 63.46 petaflops,效率为 80.1%。Selene 使用 AMD Eypc Rome CPU 和 Nvidia 的 80GB A100 GPU 实现了 Nvidia 的 SuperPod A100 DGX 模块化架构。
中国制造的天河 2A 以 61.4 Linpack petaflops 的速度下降一位,排名第七。配备英特尔至强芯片和定制 Matrox-2000 加速器的天河 2A(又名 MilkyWay-2A)在 2018 年进入第四名。它安装在广州国家超级计算机中心。
排名第八的是 Atos 制造的 JUWELS Booster Module——这仍然是欧洲最强大的超算,具有 44.12 Linpack petaflops。该系统安装在德国 Forschungszentrum Juelich (FZJ),由 AMD Eypc Rome CPU 和 Nvidia A100 GPU 驱动。
在前十名中,戴尔仍然是顶级学术和顶级商业供应商,HPC-5/Eni 和 Frontera/TACC 分别排名第九和第十。34.5-petaflops 的HPC-5 是一个 Nvidia GPU 加速机器,而 23.4-petaflops 的Frontera则是一个直接的 x86 Intel Cascade Lake 系统。这两个系统都依赖于 Mellanox HDR InfiniBand。
让我们将我们的范围扩展到前 20 名细分市场,然后将焦点放在了榜单中的三个新进入者身上。以 22.2 petaflops 排在第 12 位的是 ABCI 2.0。新系统由富士通制造,取代了原来的 ABCI,后者在 2018 年的基准测试为 19.9 petaflops。
排在第 13 位的是日本的Wisteria/BDEC-01 (Odyssey) 系统,具有25.95 Linpack petaflops。Odyssey 安装在东京大学,由富士通制造,利用其 A64FX Arm 内核。
排名第 19 的超级计算机是沙特阿拉伯的 Ghawar-1,它具有 19.3 petaflops 的性能,它是一种 HPE Cray EX 系统,集成了 AMD Epyc Rome CPU 和 HPE Slingshot 互连技术。它由 HPE 为沙特阿美公司建造。
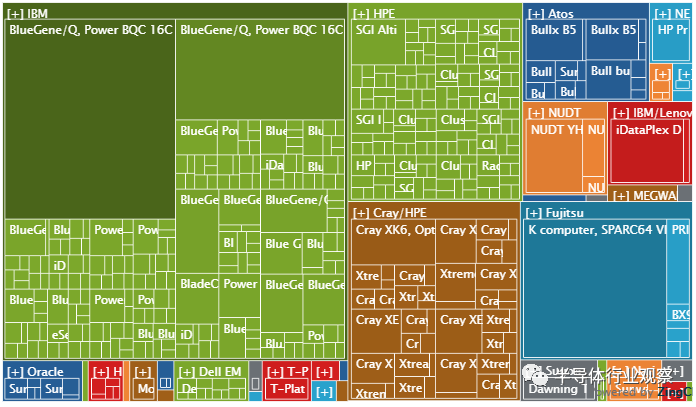
尽管从六个月前的 214 台机器和一年前的 226 台机器大幅下降到现在186 台,但中国在系统数量方面仍处于领先地位。中美之间的地缘政治紧张局势似乎抑制了中国对 Top500 的兴趣。据可靠消息来源称,中国两年前对两个大型系统(200-300+ petaflops 范围)进行了基准测试,但并未正式列入名单。
美国在当前列表中有 123 个系统,而上一个列表中有 113 台机器。在前 100 个系统中,美国的份额最高,为 33 个。日本次之,为 19 个。其次是德国,拥有 11 个系统。中国有3个系统进入前100名,没有一个是新的。
在上榜的 58 款新系统中,美国声称有 16 款,中国排名第二, 8 款新系统均来自联想。德国以七名紧随其后,日本以五名紧随其后。
由于 IBM 系统的数量从九个减少到八个,因此没有新的 IBM 系统。下车的是Blue Joule,它是安装在 STFC Daresbury 实验室(英国)的 IBM BlueGene/Q。这台拥有 9 年历史的机器是名单上的最后一台 BlueGene,它的离开象征着曾经统治 HPC/超级计算的架构时代的结束。
Top500 团队指出,自六个月前以来,互连使用模式没有太大变化。他们报告说:“大约一半的系统 (245) 仍在使用以太网,大约三分之一的机器 (169) 使用 InfiniBand,OmniPath 互连不到十分之一 (42),只有一个系统依赖于 Myrinet . 自定义互连占 37 个系统,而专有网络在 6 个系统上被发现。”
尽管在 Cornelis Networks 的指导下有一个新的 OmniPath 路线图,但此列表中没有新的 Cornelis-OmniPath 系统。不过,名单上有一个这样的系统;Livermore 的 Ruby 超级计算机于六个月前首次亮相,并使用 Cornelis Networks 的 OmniPath。
同样值得注意的是,HPE 的 Slingshot 互连现在用于七个系统,从最后一个列表 (CSCS Alps) 上的一个系统开始。
专注于前 100 名细分市场,InfiniBand 仍然占据主导地位。它用于前 100 名系统中的 65 个,包括使用 HDR InfiniBand 半定制版本的 Sunway TaihuLight 系统。这比去年 11 月的 61 台连接 IB 的机器有所增加。OmniPath 的安装量稳定在 13 次。
八台 EuroHPC 系统中有四台如期交付并首次上榜。其中两个系统有两个分区,所以实际上有六个系统,都是 Atos 制造的:Vega(#107,3.8 petaflops,斯洛文尼亚),MeluXina 加速器模块(#37,10.5 petaflops,卢森堡),MeluXina 集群模块(#232 ,2.3 petaflops,卢森堡),Karolina GPU 分区(#70,6.0 petaflops,捷克),Karolina CPU 分区(#149,2.8 petaflops,捷克)和 Discoverer(#92,4.5 petaflops,保加利亚)。Petascale Deucalion(葡萄牙)和更大的 pre-exascale 系统 Leonardo(意大利)和 LUMI(芬兰)仍在开发中。我们仍在等待有关第八个 EuroHPC 系统 MareNostrum 5(西班牙)的详细信息。
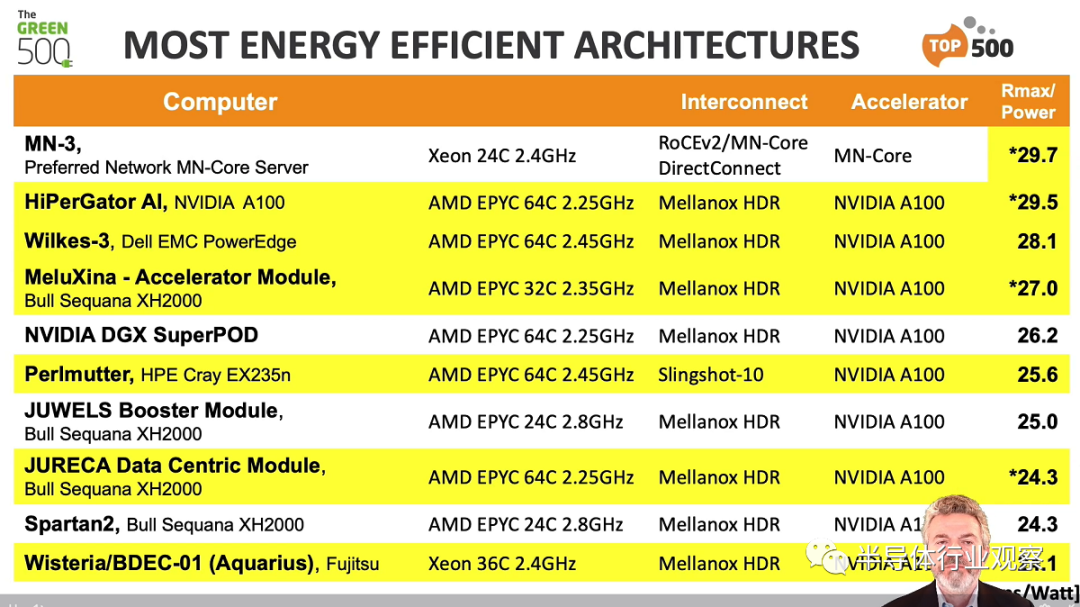
重新夺回 Green500 第一名的是 Preferred Networks 的 MN-3 系统。在六个月前被英伟达的 DGX Superpod 反超后,PFN 提高了其深度学习优化的 MN-3 系统的能效,从 26.0 gigaflops-per-watt 提高到 29.70 gigaflops-per-watt。MN-3 由 MN-Core 芯片驱动,MN-Core 芯片是一种针对矩阵运算的专有加速器。该系统以 1.8 Linpack petaflops 在 Top500 中排名第 337 位。
Green500 的第二名是佛罗里达大学的 HiPerGator AI,提供 29.52 gigaflops-per-watt 的能源效率。Nvidia DGX A100 系统使用 AMD Epyc Rome CPU、Nvidia A100 GPU 和 InfiniBand HDR 网络。在 Top500 中排名第 22 位,具有 17.20 petaflops,这是一台比排名第一的最环保系统大得多的机器。
在 Green500 上排名第三的是 Wilkes-3,它由戴尔制造并安装在剑桥大学。这个新进入者 由 AMD Eypc Milan CPU 和具有 HDR InfiniBand 的 Nvidia A100 80GB GPU 提供支持 ,能提供 28.14 gigaflops-per-watt 的能效。它以 4.1 petaflops 的速度在 Top500 中排名第 101。
在前 10 名最节能的系统中,有 6 台是新机器。前 20 名 Green500 机器中有 17 台加速。其他三台(非加速)机器都是基于富士通 Arm 的:Fugaku、Fugaku 原型和 Odyssey。
再一次,我们在过去几年中看到的 Green500 上层国际代表的多样性是一个令人鼓舞的趋势。日本、美国、英国、卢森堡、德国、法国、捷克和意大利都有机器进入前 25 名。
Green500 幻灯片,由 Erich Strohmaier 介绍(2021 年 6 月 28 日)
Microsoft Azure 作为四个基于云的集群的制造商首次登上第 57 位 Top500 榜单,在第 26 至 29 名的位置上名列前茅。这四台机器——每台基准测试为 16.6 petaflops——基于 Azure 的 NDv4 集群。这是一种基于Nvidia HGX 的设计,利用了 8 个 Nvidia A100 GPU 和两个 AMD Epyc Rome 48 核处理器,通过200 Gbps HDR InfiniBand互连。
微软告诉我们,实际的 Azure ND A100 v4 系列集群明显大于四台基准机器。“我们没有透露有多大,但我们选择只在每个集群的一部分上运行基准测试,部分是为了更好地满足客户对访问的难以置信的需求,” Azure HPC Group 高级项目经理Ian Finder 指出.
Anther 云提供商 Amazon Web Services 通过客户 Descartes Labs 刷新了其在列表中的地位。这家地理空间情报公司使用 Xeon 24 核 Cascade Lake CPU 和 25G 以太网启动了由 AWS EC2 xlarge R5 实例组成的第 41 台机器。2019 年的机器在 15.11 petaflops(66% 的效率)的理论峰值中提供了 9.96 Linpack petaflops。“我们今天的云使用涵盖了千万亿级地球观测数据集的分析范围,特别是从光学图像转向更深奥的地球观测类型,如雷达、InSAR 和 AIS 数据,”笛卡尔实验室联合创始人兼CTO Mike Warren 说。
该列表包括 144 个使用加速器/协处理器技术的系统,低于 6 月份的 148 个。在当前的 144 个加速系统中,138 个(96%)采用了 Nvidia 技术。列表中只有一个条目使用了 AMD GPU:位于浦口高级计算中心的,由曙光制造的中国系统,该系统由 AMD Epyc “Naples” CPU 和 AMD Vega 20 GPU 提供支持。该系统现在位于#378,于 2019 年 11 月首次亮相。
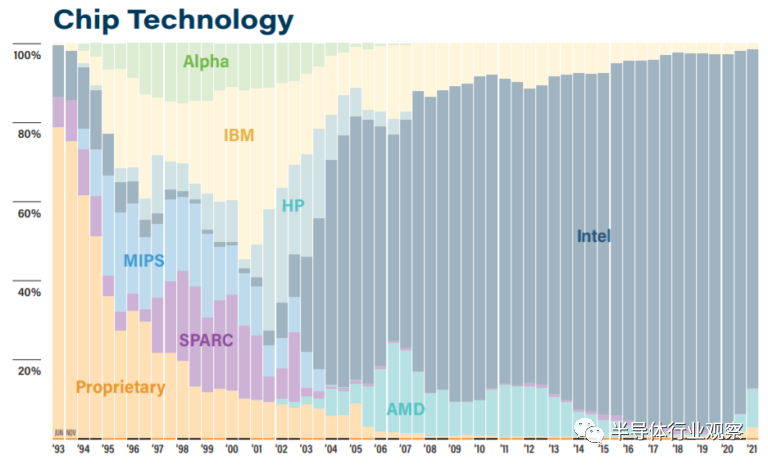
Top500 报告称,英特尔继续是Top500 系统中的最大份额( 86.20% )处理器供应商,低于六个月前的91.80 % 和一年前的 94%。英特尔 Ice Lake 处理器在八个系统中首次亮相。
AMD 为 49 个系统提供 CPU (9.8%),高于六个月前的 4.2% 和一年前的 2%。AMD Epyc 处理器占据了 2021 年 6 月名单中 58 个新条目的一半。四个第三代 Epyc Milan 系统首次在此列表中亮相,其中包括 Perlmutter。
AMD 在 Selene(#5)和 Perlmutter(#6)方面的排名高于 Intel 在天河 2A(#7)方面的排名。列表中排名前四的系统不是基于 x86 的。
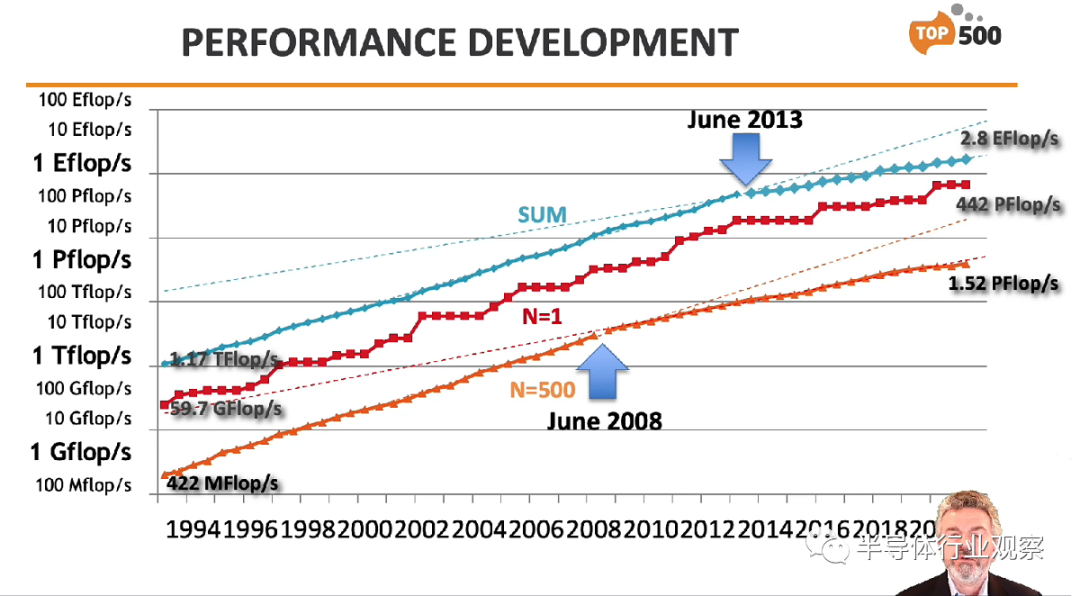
所有 500 个系统提供的总 Linpack 性能为 2.80 exaflops,高于 6 个月前的 2.43 exaflops 和 12 个月前的 2.22 exaflops。整个榜单的 Linpack 效率与六个月前的 63.3% 相比基本稳定在 63.1%,前 100 名细分市场的 Linpack 效率略有下降:70.7% 与六个月前的 71.2% 相比。排名第一的系统 Fugaku 提供了 82.28% 的健康计算效率。
列入第 57 名 Top500 名单所需的最低 Linpack 分数为 1.52 petaflops,而六个月前为 1.32 petaflops。前 100 名细分市场的入口点是 4.13 petaflops,而上一个列表的入口点是 3.16 petaflops。当前的第 500 系统在上一版中排名第 450。
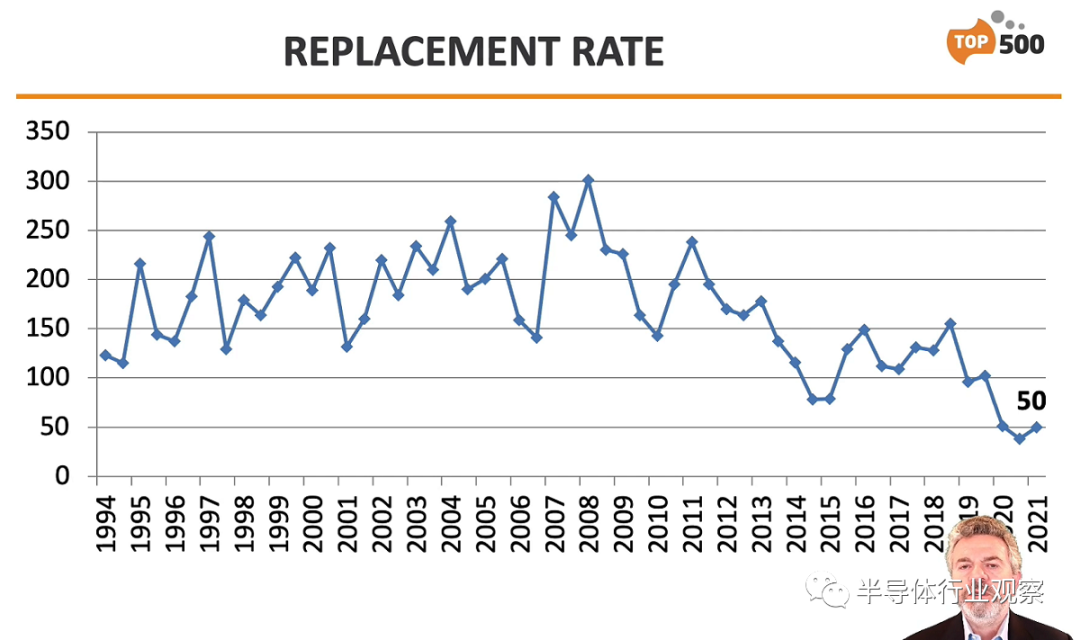
仅有 50 个系统被排除在外,扁平化趋势仍在继续。最后三个列表是该项目历史上最低的替代率。
由 Erich Strohmaier 提出(2021 年 6 月 28 日)。
2021 年 6 月的名单上有五个当前或以前的排名第一的系统。除富岳外,还有 Summit、神威太湖之光、天河二号A和天河一号A。天河一号A在高性能计算方面已经很老了,实际上它是名单上最古老的系统。十多年前安装在天津(中国)国家超级计算中心的天河一号 A 于 2010 年 11 月首次进入 Top500 名单。名单上第二古老的系统于 2011 年 6 月首次亮相,是一个内部英特尔集群,称为(适当地)努力。它现在以 1.6 petaflops 排在第 379 位。
由 Erich Strohmaier 提出(2021 年 6 月 28 日)
又到了对百亿亿次目标期望的时刻,到2020年,百亿亿次级系统尚未提上了前500强名单。美国有望在今年晚些时候在橡树岭国家实验室建立其首个百亿亿级系统 Frontier。他们能否及时对 11 月的 Top500 榜单进行基准测试,这是一个悬而未决的问题。中国正在努力在 2020 年至 2021 年的时间范围内建立一个百亿亿级系统,并且可能已经这样做了。
由 Erich Strohmaier 提出(2021 年 6 月 28 日)。
原文链接:
https://www.hpcwire.com/2021/06/28/top500-fugaku-still-on-top-perlmutter-debuts-at-5/
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2721内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|MLCC|英伟达|模拟芯片
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!