来源:内容由半导体行业观察(ID:icbank)编译自「
anandtech
」,谢谢。
自Marvell 发布OCTEON TX2 基础架构处理器以来,已经过去了一年多时间。但其实从那时开始,整个生态系统一直在以极快的方式发展——无论是在 Marvell 内部还是外部。今天,我们将介绍新一代 OCTEON 10 系列 DPU,这是一个全新的 SoC 系列,建立在 TSMC 的 5nm 工艺节点之上,在这个处理器上,将首次展示 Arm 的新型基础设施处理器——Neoverse N2 。
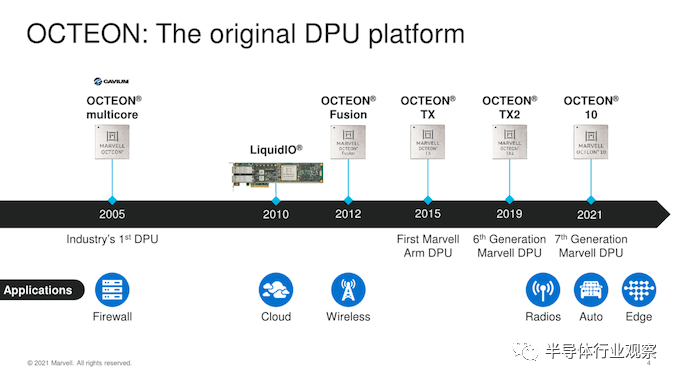
从一些历史和命名法开始,Marvell 为此类芯片和加速器类型采用了“DPU”术语。如上图所示,从上一代的 OCTEON TX 和 OCTEON TX2 开始,除了名称之外,他们还有另一个称谓,那就是DPU。在以前,它们只是被称为“基础架构处理器”。然后最近,随着最近该术语在行业中日益流行以及竞争对手的解决方案得到支持,我们似乎看到 DPU 现在正在被广泛接受。其定义是基于这样一个事实,即它是在数据通过网络传输时,有助于帮助处理和移动数据。
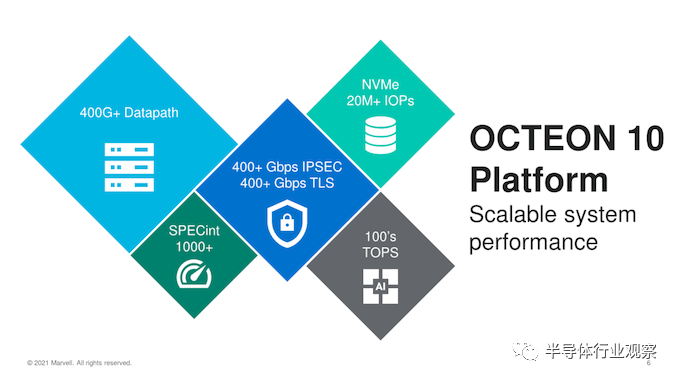
从概述开始,新的 OCTEON 10 具有不少我们在上一代中看到的,相同的多功能构建块阵列,这次带来的新产品不但升级到最新的、最先进的 IP 块,还引入了一些新功能,例如集成机器学习推理引擎、新的内联和加密处理器以及矢量数据包处理器,所有这些都能够以虚拟化方式运行。
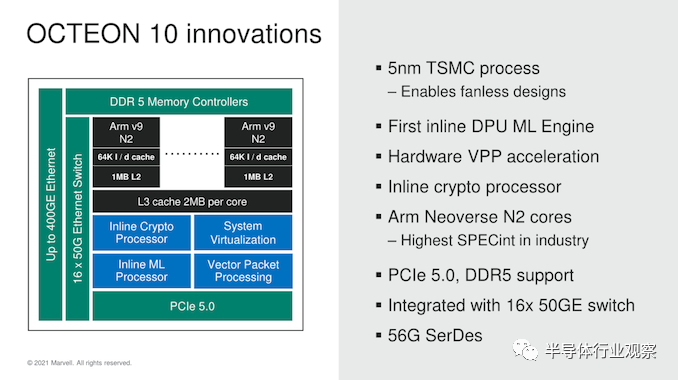
这也是 Marvell 第一个 基于TSMC N5P 工艺的芯片设计,实际上也是同类中第一个采用该工艺的 DPU,也是第一个公开宣布在产品中实现Neoverse N2 集成的企业。此外,该芯片具有最新的 PCIe 5.0 I/O 功能以及 DDR5 支持。
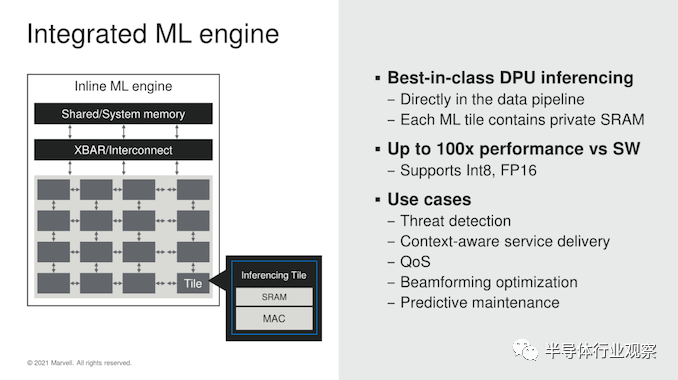
在Marvell 看来,当中有不少功能是 DPU 的重要补充。首先是一个新的内部 ML 引擎。Marvell 曾表示,这个IP 的设计实际上最初是为专用推理加速器而创建的。据了解,这个设备实际上已于去年已经完成,但由于竞争激烈,Marvell 选择不将其推向市场。相反,Marvell 选择将 ML 加速器集成到他们的 OCTEON DPU 芯片中。Marvell 表示,将推理加速器放在同一个单片硅芯片上,直接集成到数据pipeline中,这对于实现此类数据流用例所需的高吞吐量处理的低延迟非常重要。
从本质上讲,Marvell 正在成为Nvidia 下一代 BlueField-3 DPU的直接竞争对手。在 AI 处理能力方面,Marvell的新产品遥遥领先。此外,首批 OCTEON 10 解决方案预计将在今年年底推出样品,而 Nvidia 预计BF3 将于 2022 年才能到来。
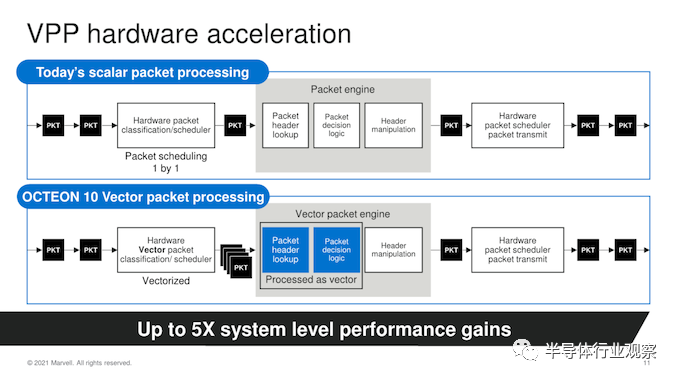
此新 OCTEON 10 系列的又一项新功能是引入了矢量数据包处理引擎,与当前的一代标量处理引擎相比,它能够将数据包处理吞吐量大幅提高 5 倍。
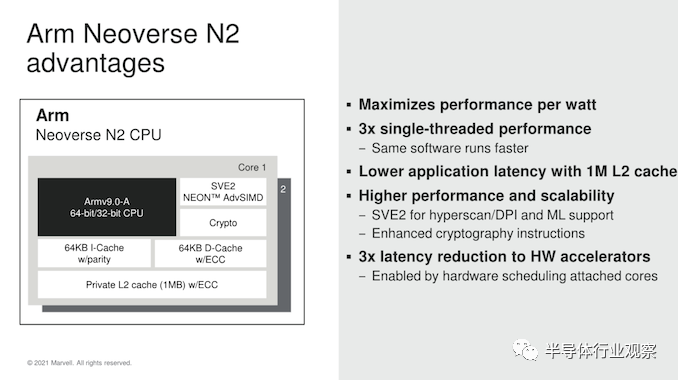
如前所述,新的 OCTEON 10 DPU 系列是第一个公开宣布采用Arm 最新 Neoverse N2 基础架构 CPU IP 的硅设计。在几个月前,我们就已经详细介绍了 N2 及其 HPC 兄弟V1 。其要点是新一代核心是 Arm 的第一个 Armv9 核心,与用在Arm服务器CPU(如 Amazon Graviton2 或 Ampere Altra)的N1 核心相比,新的产品承诺将带来40%的IPC提高 。
对于 Marvell 而言,性能提升更为显着,因为该公司正在从公司之前的内部“TX2”CPU IP 切换到 N2 内核。为此他们承诺将单线程性能提升 3 倍。去年年底,Marvell 宣布已停止使用自己的 CPU IP,转而支持 Arm 的 Neoverse 内核,今天重申该公司计划在可预见的未来坚持 Arm 的路线图,这是对 Arm 新 IP 的大力支持。这与Ampere或高通等其他行业参与者形成鲜明对比。
对于 DPU 用例来说,重要的是这是一个 Armv9 CPU,同时也支持 SVE2,还包含有助于数据处理和机器学习功能的新重要指令。这实际上比 Nvidia 的 BlueField3 DPU 设计具有很大的优势,后者仍然只使用 Armv8.2+ 的 Cortex-A78 内核。
Marvell 为其 N2 实现使用完整缓存配置选项,这意味着 64KB L1I 和 L1D 缓存,以及完整的 1MB L2。然而,该公司与 SoC 的集成继续使用他们自己的内部网状网络解决方案——在非常高的层面上,这在基本规格方面看起来仍然相似,网状中有 256 位数据路径(datapaths ),还有一个包含 2MB 缓存切片的共享 L3,可扩展随着核心数量的增加。
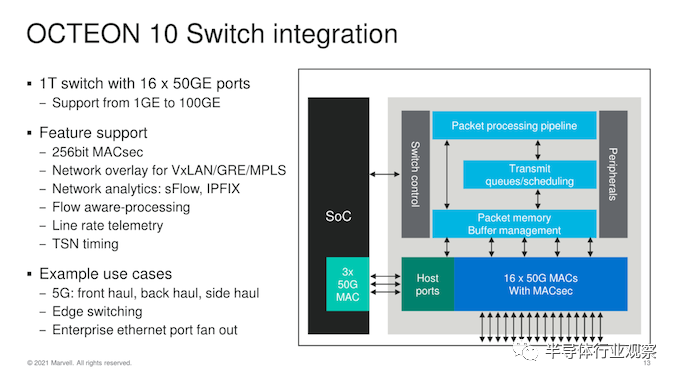
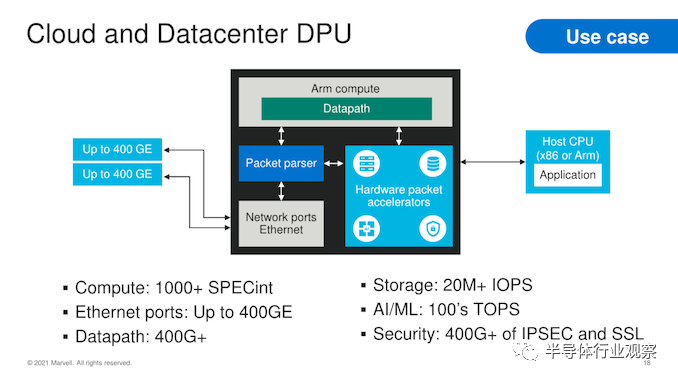
在交换机集成和网络吞吐量方面,Marvell 将 1 Tb/s 交换机与多达 16 个 50G MAC 集成在一起——这里的功能会根据实际 SKU 和芯片设计而有很大差异。
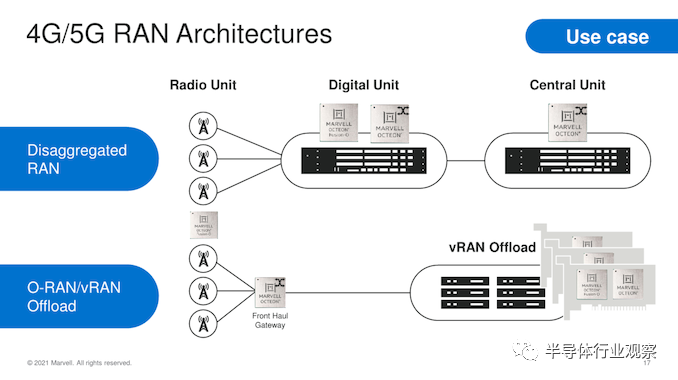
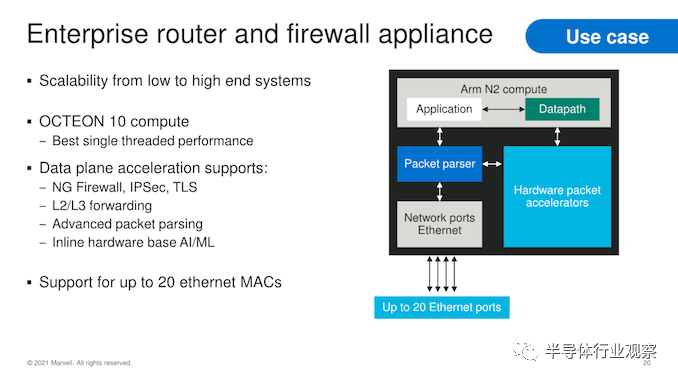
在用例方面,OCTEON 10 系列涵盖了广泛的应用,覆盖了 4G/5G RAN 数字单元或中央单元、前传网关甚至 vRAN 卸载处理器。在云和数据中心,这些解决方案可以在计算和网络吞吐量性能方面提供广泛的多功能性,而对于企业用例,该系列提供深度集成的数据包处理和安全加速功能。
第一个 OCTEON 10 产品和样品将基于 CN106XX 设计,在 PCIe 5.0 外形尺寸上具有 24 个 N2 内核和 2 个 100GbE QSFP56 端口,可在第四季度送样。
在规格方面,Marvell 对各种 OCTEON 10 系列设计进行了细分:
注:本文中的 DDR5 控制器是指 40 位通道(32+8 位 ECC)。Marvell 还表示,它仍然使用 SPECint2006,因为它与上一代和竞争对手的解决方案相比具有历史重要性——一旦第一个芯片准备好,它将发布SPECint 2017 的数据。
CN106XX 是 OCTEON 10 系列的首款芯片设计,已流片,预计今年下半年出样。除了这第一款芯片之外,Marvell 还有 3 款其他 OCTEON 10 设计,包括只有 8 个 N2 内核和 10-25W 低 TDP 的低端 CN103XX 和两个具有改进网络连接的高端 CN106XXS,最后是具有多达 36 个 N2 内核的 DPU400 旗舰,并具有最大的处理能力和网络连接吞吐量。非常令人兴奋的是,即使采用最大的实现,产品的TDP 也仅达到 60W,远低于当前一代 CN98XX Octeon TX2 旗舰实现的 80-120W。这些额外的部件尚未流片,计划在 2022 年全年进行采样。
Marvell 表示,它在 DPU 出货量方面一直处于行业领先地位,并且在所有大型数据中心部署中都很普遍。从技术角度来看,这款全新的 Octeon 10 代显然极具侵略性,具有领先的 IP 和制造工艺,这将使 Marvell 在性能和能效方面在快速发展的 DPU 市场竞争中具有显着优势。
★ 点击文末
【阅读原文】
,可查看本文原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2721内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|MLCC|英伟达|模拟芯片
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!