来源:内容由半导体行业观察(ID:icbank)编译自「
semianalysis
」,谢谢。
作为最重要的 AI 初创公司之一,Tenstorrent 获得了大量媒体报道。除了有前途的硬件和软件设计,媒体炒作这家公司的部分原因是因为他们由芯片行业的专家Jim Keller领导。公司成立以来,他就一直是其中的一名投资者。在特斯拉任职后,他又去英特尔工作,最终于 2021 年初,Jim Keller成为了Tenstorrent 的首席技术官。
据报道,Tenstorrent 采用了一种将硬件和软件紧密结合的独特方法。硬件专门用于该任务,但软件并不复杂。整个软件栈只有大约 50,000 行代码。与大多数其他需要自定义开发pipeline的特定于 AI 的 ASIC 不同,Tenstorrent 具有很强的适应性和灵活性,同时支持所有主要工具链、框架和runtime。那就意味着,英伟达极易开发的最大优势正在受到挑战。
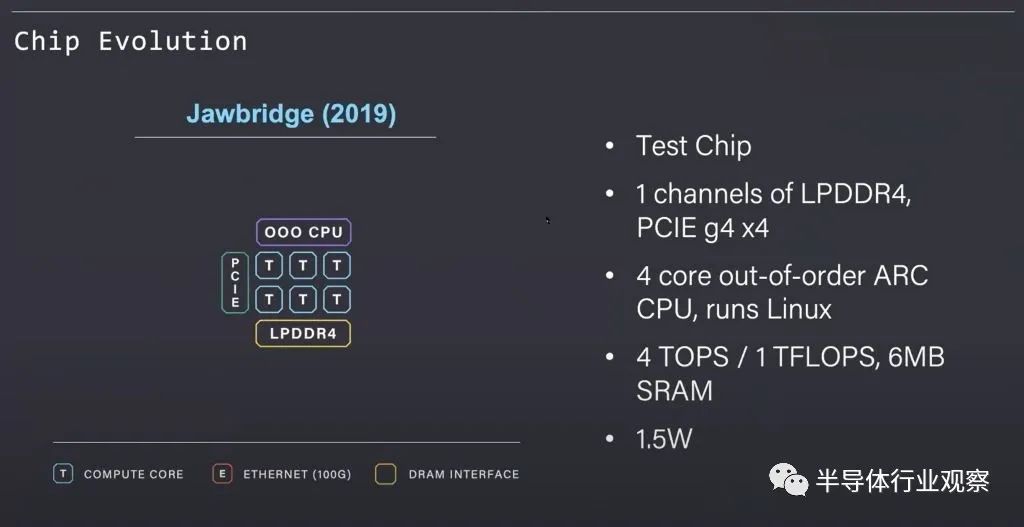
为了了解它们的架构和 Wormhole 处理器,我们将遍历它之前的历史和沿袭。当中的Jawbridge 是一个小型测试芯片,是作为架构概念验证而开发的。在其内部集成了一系列由 Tenstorrent 设计的“Tensix”处理核心,这些核心通过内部片上网络 (NOC) 连接。这与授权的 I/O 块(如 LPDDR 内存控制器和 PCIe 根)相结合。片上 CPU 内核可以管理工作负载并运行 Linux。
Jawbridge 是一种极小的芯片,具有极低的功耗要求。凭借有限的预算,他们将这款芯片进行了流片,并验证了其令人印象深刻的功耗/性能表现。基于这一概念证明的支持,他们能够筹集更多资金以扩展到下一代。
GraySkull 是下一个进化产品,它是一个商业产品,拥有 128 个 Tensix 核心,最重要的 是,该芯片的NOC 大幅扩展,IO 更大。该芯片采用 GlobalFoundries 12nm 工艺,面积为 620mm^2。Tenstorrent 设计实力的证明是他们正在出货A0 硅。这意味着他们正确地设计了芯片并且在他们的第一次流片中没有发现任何错误。即使对于 AMD、Apple、Intel 和 Nvidia 等公司经验丰富的团队来说,这种庆祝活动在行业内也非常罕见。
GraySkull 是一款 65W 芯片,但 PCIe 附加卡是 75W。这意味着它可以轻松插入现有服务器,无需任何额外的辅助电源。在完成流片和送样后,Tenstorrent 能够筹集更多资金来发展他们的下一代芯片。
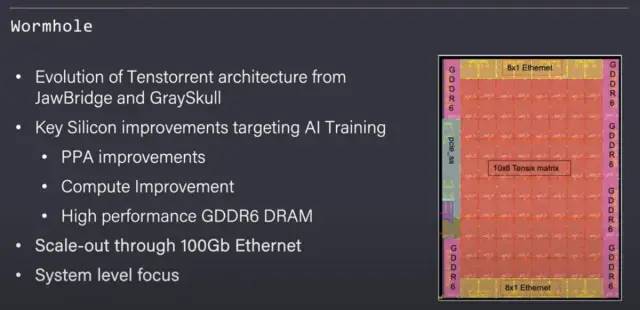
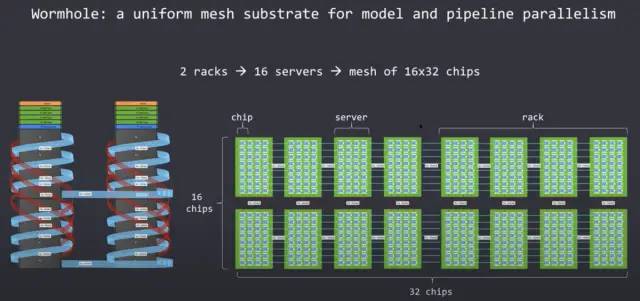
这将我们带到了 Wormhole,它是一个面积为 670mm^2 的芯片,采用相同的 GlobalFoundries 12nm 工艺节点。尽管硅面积和同一节点的利用率略有增加,但 Tenstorrent 能够显著扩展芯片的性能、IO 和可扩展性。除了更高的性能和更耗电之外,与之前设计的最大不同在于,新芯片增加了 16 个带有 100Gb 以太网的端口。以太网端口允许将许多芯片连接在一起,以便为大型 AI 网络横向扩展。
除了通过以太网扩展之外,每个 Tensix 内核都会进行一次大的升级。它们现在每个内核包含更多 SRAM,并且可以执行更复杂的数学和 SIMD 指令。Wormhole 包含一个 192 位 GDDR6 内存总线,能够提供 384GB/s 的内存带宽。尽管矩阵运算的性能提高了 2 倍,内存带宽提高了近 3 倍,并且包含 1.6Tbs 的网络交换功能,但 Wormhole 芯片的功率仅翻了一番,达到 150W。
Tenstorrent 在同样的 12nm 制程技术和不到 10% 的芯片面积增加上,做了相当于黑魔法的事情来实现这些目标。片上网络 (NOC) 设计巧妙,可通过以太网端口进行本地扩展。芯片到芯片通信需要 0 软件开销来横向扩展 AI 训练。
AI 训练工作负载的复杂性正在飙升。OpenAI 声称,训练最强大的网络所需的计算量每 3.5 个月翻一番。Facebook 最近宣布他们新生产的深度学习推荐系统是 12 万亿个参数。这超过了 OpenAI 的趋势。训练这些网络不仅需要服务器,还需要整个 AI 专用服务器机架。轻松扩展到大规模网络的能力是 Tenstorrent 虫洞的关键优势。
Wormhole 芯片将提供两种变体。一种是可轻松插入服务器的附加 PCIe 卡。真正有大量 AI 训练问题的客户会想要购买该模块。这使该芯片的全部功能能够承受所有暴露的以太网网络功能。
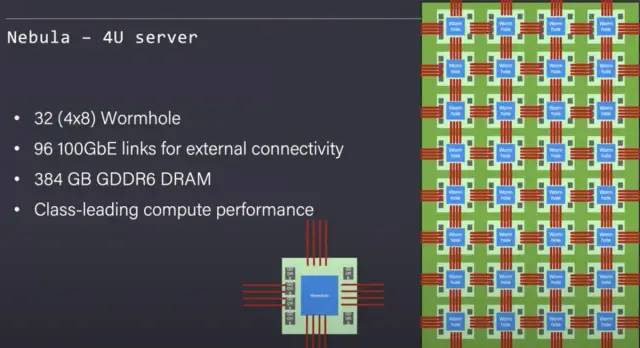
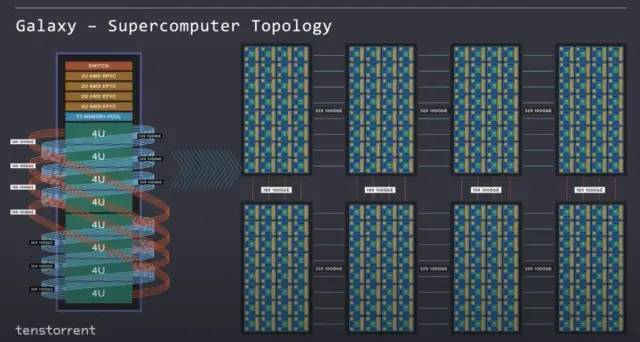
Tenstorrent 将 Nebula 设计为基础构建块。它是一个 4U 服务器机箱。在这台 4U 服务器中,他们能够塞满 32 个 Wormhole 芯片。这些芯片在内部以全网状连接,能够以透明的方式轻松地将此网状网络扩展到远远超出单个服务器的范围。
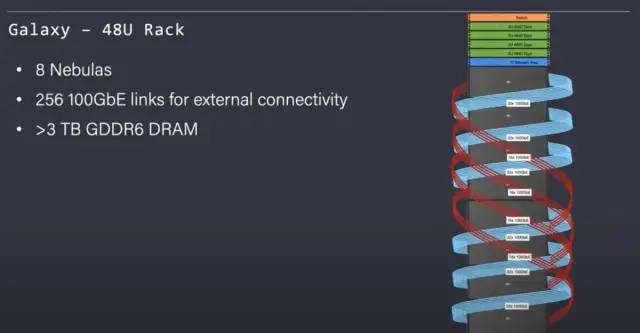
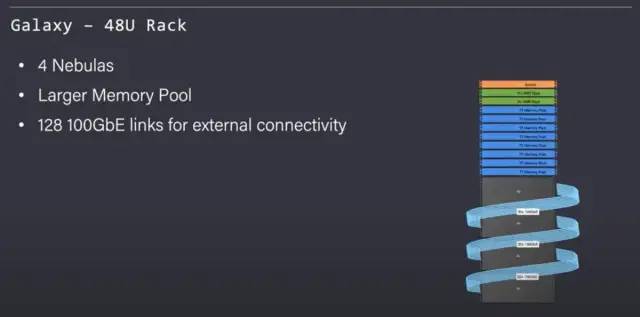
这家公司的乐趣不止于此,Tenstorrent 还展示了 Galaxy。这是在扩展网格中连接的 8 个Nebulas
。
该机架还包含 4 个 AMD Epyc 服务器和一个共享内存池。
该机架提供 >3TBs 的 GDDR6 和 256Gb 的外部以太网链接。
通用 AMD Epyc 服务器和内存池连接到以太网网格。
Tenstorrent 认识到所有 AI 工作负载都不是同质的。他们提供机架级服务器,提供一半的Wormhole计算能力。
AMD Epyc 服务器数量也减少了一半。这种计算权衡是为了换取更大的内存池。每个机架包含 8 倍的内存。这种类型的配置更适合内存密集型模型,例如深度学习推荐系统。
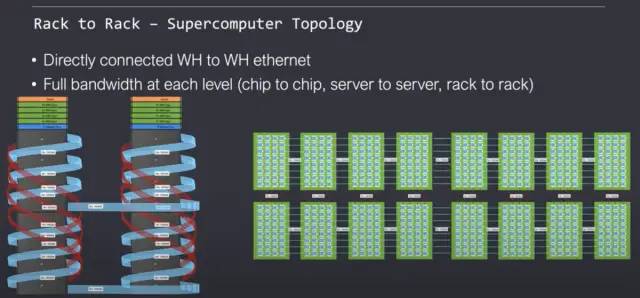
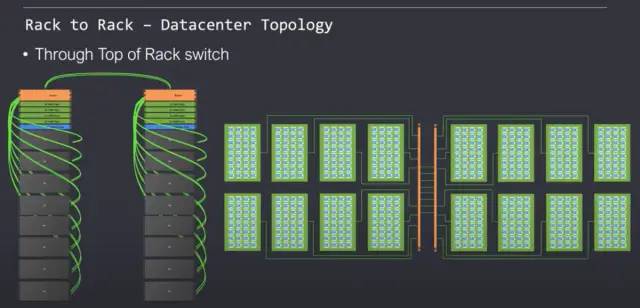
Tenstorrent 支持以 2D 网格连接的机架单元。关于它们如何扩展的重要事情是软件处理它的方式。对于软件来说,它看起来像是一个由 Tensix 核心组成的大型同构网络。片上网络可以透明地扩展到许多服务器机架,而无需任何痛苦的软件重写。他们的网状网络理论上可以扩展到无限大且具有完整和统一的带宽。这种拓扑不需要使用许多昂贵的以太网交换机,因为芯片上的Wormhole网络本身就是一个交换机。每个服务器顶部描绘的交换机仅用于将这些服务器连接到外部世界,而不是在网络内。
Tenstorrent 支持多种拓扑。每一种都有自己的优点和缺点。完全支持在许多数据中心内流行的经典叶(classic leaf )和spine 模型。尽管网络能力不均衡,但片上 NOC 可以干净地扩展而不会中断。完全支持弹性和多multitenant 架构。
Wormhole通过删除严格的层次结构来做到这一点。横向扩展服务器往往在带宽、延迟和编程层次结构方面具有芯片内、芯片间、服务器间和机架间通信的层次结构。Tenstorrent 声称已经找到了一种秘密武器,可以让这些不同级别的延迟和带宽对软件无关紧要。尽管具有这种灵活性,但芯片利用率仍然很高。我们当然怀疑他们如何能够如此干净地实现这一目标。
编译器和模型设计人员花了很多时间试图找出横向扩展问题,Tenstorrent声称他们拥有灵丹妙药。编译器和研究人员看到了“无限的内核流”。他们不必将模型调整到网络。因此,如果需要,机器学习研究人员可以不受束缚,可以将模型缩放到数万亿个参数。由于这种灵活性,网络的规模可以在以后轻松增加。
这个横向扩展问题非常困难,尤其是对于定制 AI 芯片。即使是在横向扩展硬件领域处于领先地位的 Nvidia,也迫使最大的模型开发人员处理这些严格的带宽、延迟和编程层次结构。如果 Tenstorrent 关于自动化这项痛苦任务的说法属实,他们已经颠覆了整个行业。
要了解他们是如何做到这一点的,我们需要回顾一下横向扩展培训的历史。从历史上看,为了跨 CPU 集群进行扩展,人们会利用大批量并将其拆分到集群中。将有一个中央参数服务器来聚合批次。由于带宽限制,这并没有很好地扩展。
接下来,GPU 集群之间的所有带宽都降低了,带宽水平更高了,这带来了进一步的进步。它仍然有局限性,除了增加批处理大小和跨集群分片数据外,早期还尝试结合其他类型的并行性。
最大的限制是在某些时候你会用完批量大小。如果您继续增加批量大小,模型将不再收敛并达到高精度。对于更大的模型,DRAM 容量成为一个限制因素,因为整个模型都在所有节点上复制。中间计算甚至不再适合需要大量 DRAM 带宽来存储这些中间数据的片上 SRAM。更高的 DRAM 尺寸和带宽带来的影响是每个节点的成本飙升。这种缩放方法适用于小型模型,但它很快就不再适用于大型模型。
随着更大的模型开始发挥作用,我们开始看到用于有效扩展库的出现。用户现在可以指定和组合跨服务器集群的模型、pipeline和分片数据并行。本质上,用户将跨节点拆分网络的模型和层。这允许模型保持缩放,因为它们不需要在每个节点内复制整个模型。这种缩放形式的最大问题是必须手动完成。研究人员必须选择将哪些层映射到哪些硬件并控制数据流。
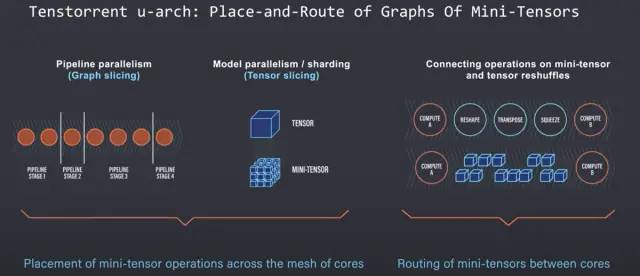
在扩展模型时,您需要在各个节点和硬件单元上对模型层进行切片和映射。除了流水线并行之外,单个张量操作也可能变得太大,以至于单个张量核心硬件单元无法单独执行。一层上一个节点内的这些张量操作也需要研究人员手动切成小张量。
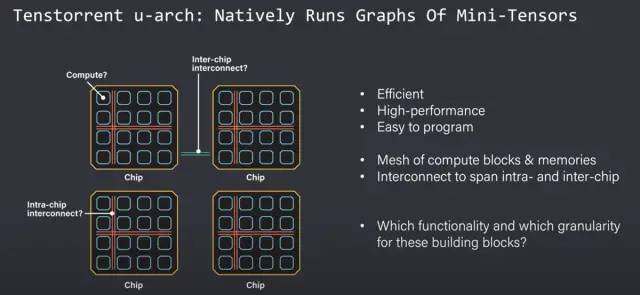
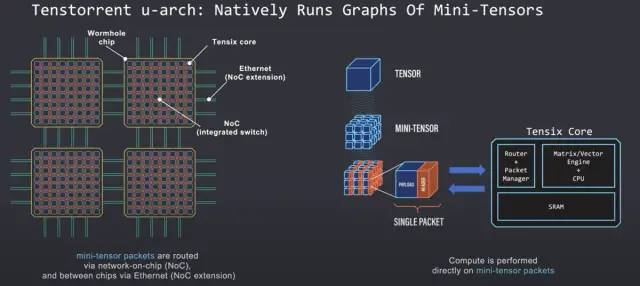
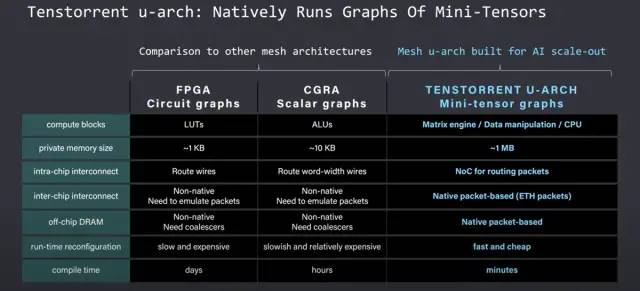
Tenstorrent 的目标是创建一个可以本地放置、路由和执行微型张量操作图的架构。微型张量被实现为 Tenstorrent 架构的原生数据类型。这意味着研究人员不必担心张量切片。每个微型张量都被视为单个数据包。这些数据包具有数据负载和标头,用于在核心网格内识别和路由数据包。Tensix 核心直接对这些微型张量数据包进行计算,每个核心都包括一个路由器和数据包管理器以及大量的 SRAM。路由器和数据包管理器处理同步并发送计算数据包以沿着网状互连流动,无论它是在片上还是片外通过以太网。
从软件的角度来看,整个内核网格中的数据包传输看起来是一致的。在同一芯片上的内核之间发送数据包看起来与在不同芯片上的内核之间发送数据包相同。因为每个芯片和 NOC 本身就像一个交换机,所以小张量数据包可以沿着内核的网格路由到它接下来需要转到的内核。
迷你张量数据包有 5 个关键原语。有用于在内核之间移动数据包的推/弹出。根据图中的消费者或生产者关系,复制、收集、分散和随机播放也可用于单播或多播。您可以手动将基元组合在一起,以在本地构建微型张量图。对于大多数人来说,更简单的方法是使用可以获取 PyTorch 输出的编译器。编译器将输出降低到由这些原语组成的图形中。然后可以在硬件上以 0 开销运行。
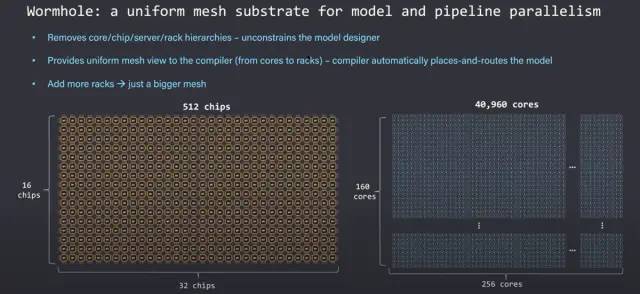
尽管包含许多芯片、服务器和Wormhole芯片机架,但软件本身只能看到这种内核网格。删除了严格的层次结构,从而使模型开发人员不受约束。编译器根据网络拓扑自动在网络中有效地放置和路由小张量,而不是让模型开发人员担心。添加更多服务器扩展了网格,并允许模型毫无顾虑地横向扩展。
这些边界允许大量模型pipeline并行。网络中的层可以使用任意数量的资源来满足计算需求。不需要太多计算的层可以使用半个服务器或半个芯片,但需要大量计算的另一个层可以跨机架延伸。第 4个示例表明,如果您的网格足够大,单个层甚至可以跨服务器机架延伸。编译器查看网格的大小并根据层的大小映射层,无论是内核网格是 1 个芯片还是内核网格是跨多个服务器机架的 10,000 个芯片。
与其他网格架构相比,Tensorrent 网格更大且更具可扩展性。FPGA 处于非常精细的水平,需要大量时间进行手动调整。CGRA 的运行标量图,但它们仍然有许多限制因素。Tenstorrent 的矩阵引擎中有多个 teraflops 和更大的内存大小。NOC、数据包管理器和路由器智能地处理芯片内和芯片间通信,让模型开发人员专注于难题的其他部分。这使得它可以更高效地横向扩展 AI 工作负载,同时也更容易开发。
如果他们的主张成真,Tenstorrent 已经取得了真正神奇的东西。他们强大的 Wormhole 芯片可以通过集成的以太网端口扩展到许多芯片、服务器和机架,而无需任何软件开销。编译器可以看到无限的内核网格,没有任何严格的层次结构。这使模型开发人员无需担心大规模机器学习模型的横向扩展训练中的图形切片或张量切片。
人工智能硬件和软件的领导者英伟达还没有接近解决这个问题。他们提供库、SKD 和优化帮助,但他们的编译器不能自动完成这些。我们怀疑 Tenstorrent 编译器能否完美地将 AI 网络中的层放置和路由到内核网格,同时避免网络拥塞或瓶颈。这些类型的瓶颈在网状网络中很常见。如果他们真的在没有软件开销的情况下解决了横向扩展 AI 问题,那么所有的 AI 训练硬件都将被敲响警钟。由于易用性的大幅提升,每个研究大型模型的研究人员都会迅速涌向 Tenstorrent Wormhole 和未来的硬件。
★ 点击文末
【阅读原文】
,可查看本文原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2720内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备
|汽车芯片|存储|MLCC|英伟达|模拟芯片
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!