来源:内容由半导体行业观察(ID:icbank)编译自「
nextplatform
」,谢谢。
因为冠状病毒的大流行,Arm的年度技术日活动采取了线上举办的模式。在今年的会上,他们正式揭开了全新Neoverse内核和处理器设计的神秘面纱。这些新的内核和处理器设计将被渴望加入的人采用和修改,用于挑战X86处理器的霸主地位。众所周知,在现在的数据中心和边缘处理器中,Intel和AMD的CPU建立了相当坚固的地位。
从发布会上我们可以看到,未来的Neoverse服务器体系结构与一个月前发布的未来Armv9-A体系结构紧密结合,并将在Neoverse“ Perseus” N2内核中首次亮相。尽管有许多Arm服务器芯片供应商离开了该领域,但Arm Holdings却一直呆在那里,似乎有许多芯片设计人员和供应商为Arm替代方案提供动力。
像Neoverse N2内核一样,它的设计已经完成并且可以从Arm Holdings获得许可,“ Zeus” V1内核也已经完成,并且在Neoverse设计系列以及数据中心和边缘的各种CPU中提供了显着的差异。
实际上,虽然我们还不知道,但在今年下半年和明年年初的某个时候,我们应该可以看到不止一个基于Arm Holdings的Zeus和Perseus平台打造的的处理器。
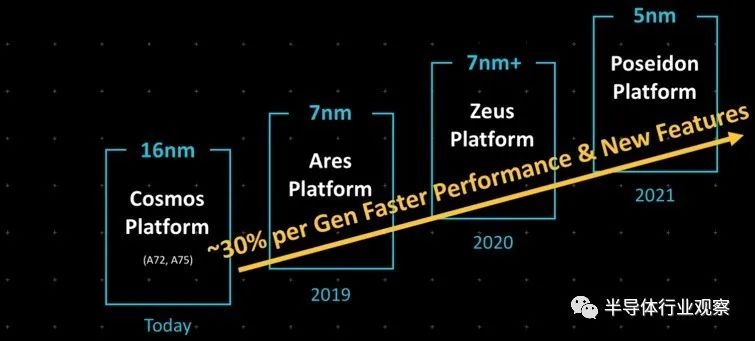
在本文中,我们将分别探讨Arm在服务器市场的性能和前景。首先,我们将仅介绍V1和N2架构。这是对原始Neoverse平台路线图的回顾:
当Arm的Neoverse最早于2018年10月提出时,那时Arm的想法是希望能拥有专门针对服务器的专用IP。而在当时,只有16纳米的“ Cosmos” N0(实际上是Cortex-A72和Cortex-A75)设计,7纳米的“Ares”原计划于2019年面世,使用增强型7纳米工艺的“Zeus” 则在2020年面世,5纳米的“Poseidon”在2021年。
Arm说,它在每年的设计中可以提供30%的性能提高约,合作伙伴也可以利用它们在自己的服务器路线图中创建的年度节奏。
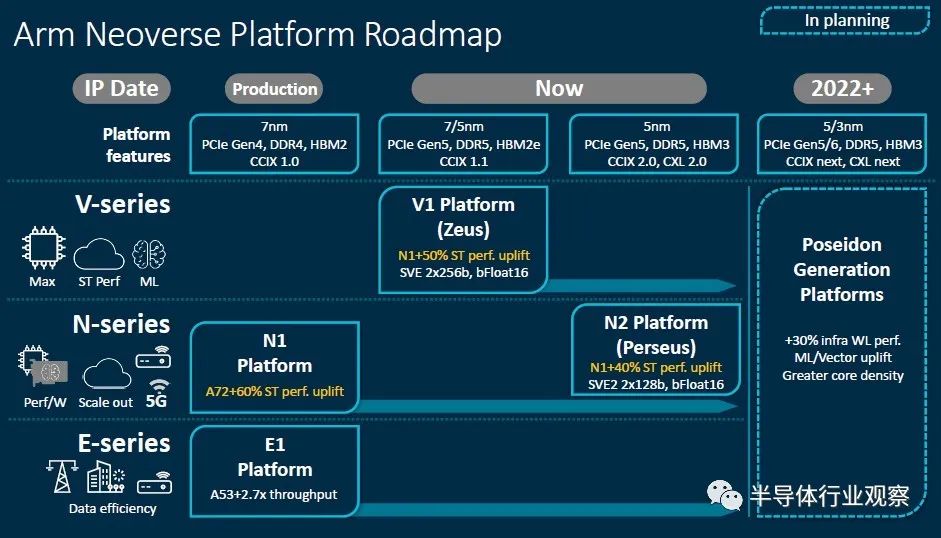
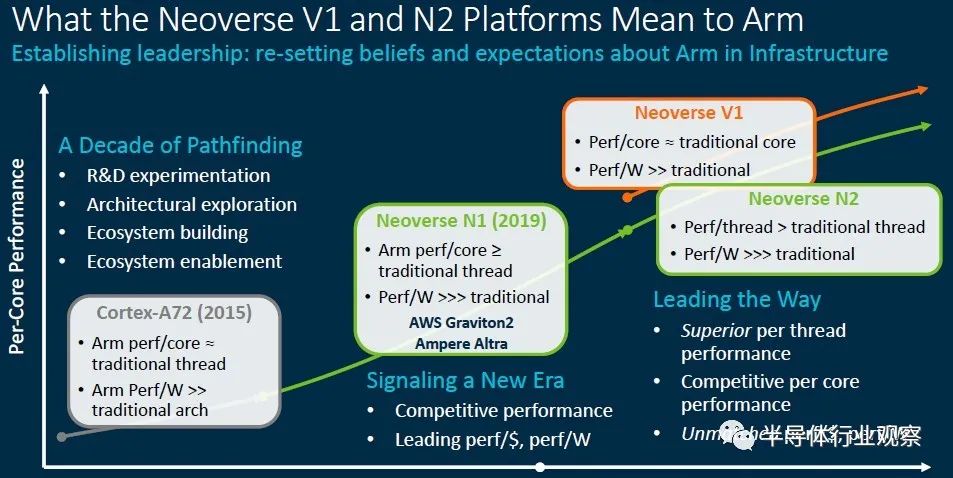
然而事实证明,这种年度节奏被证明是棘手的,而且数据中心市场已经分为核心数据中心(N系列),边缘计算(E系列)和非常高性能(V系列)核心。为此Arm似乎把Zeus N2重新命名为Perseus N2,然后在V1高性能芯片上增加了很多功能,并赋予了旧的Zeus新代号。
去年9月,当Arm推出Neoverse V1设计并将其投入使用时,N2设计尚不可用。两大Arm服务器芯片Ampere Computing Altra和Amazon Web Services Graviton2均是基于N1内核和平台设计,并进行了各种自定义。N1设计支持常规DDR4内存或HBM2堆叠内存,以及PCI-Express 4.0外围控制器和CCIX 1.0互连器(用于加速器),并在处理器之间提供NUMA共享内存。CCIX是许多互连中的一种,以提供CPU和加速器之间的缓存一致性内存共享。Arm从一开始就与CCIX一起使用,并一直将其用作CPU互连,就像AMD具有Infinity Fabric(PCI-Express的超集或HyperTransport的子集,取决于您如何看待它)一样。英特尔CXL的非对称内存模型也被加速器所采用,并运行在PCI-Express 5.0传输之上,并且正在逐渐被CPU制造商广泛采用。但这不适用于NUMA链接,仅适用于各种存储和计算加速器。
在深入了解具体细节之前,Arm整理了一些不错的图表,这些图表显示了Neoverse平台中不同核心之间的区别。这个很有趣:
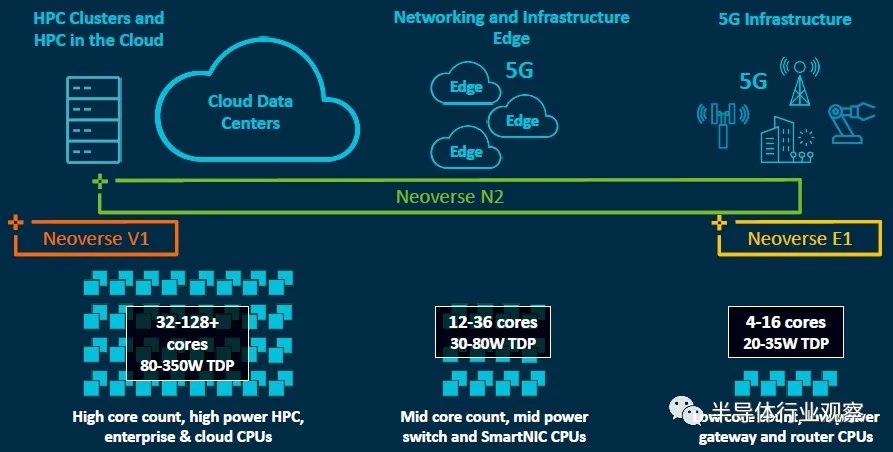
这是另一个显示E系列,N系列和V系列在不同热范围,内核数和用例中的位置的视图:
确实,这种区别并不新鲜。Arm在三年前就针对边缘和各种数据中心计算工作负载谈论了与Neoverse N1设计有关的各种设计SKU。它只是通过三个不同的芯片系列明确完成的,因此Arm许可商为特定市场生产服务器芯片的某些核心和非核心工作将不再需要做。
V1内核将进一步突破内核数,时钟速度和每秒操作数的限制。一切都变成了11个。这并不是因为Arm想要炫耀什么,而是因为一些运行搜索引擎,机器学习培训和推理,HPC仿真和建模以及数据分析工作负载的客户需要一个怪物来处理他们的数据。此外,大型公共云希望拥有一个大型实例,可以将其分解为小实例,但重要的是,还可以将大型实例作为一个昂贵的实例出售给需要运行该实例的用户,例如SAP HANA内存数据库在云中。
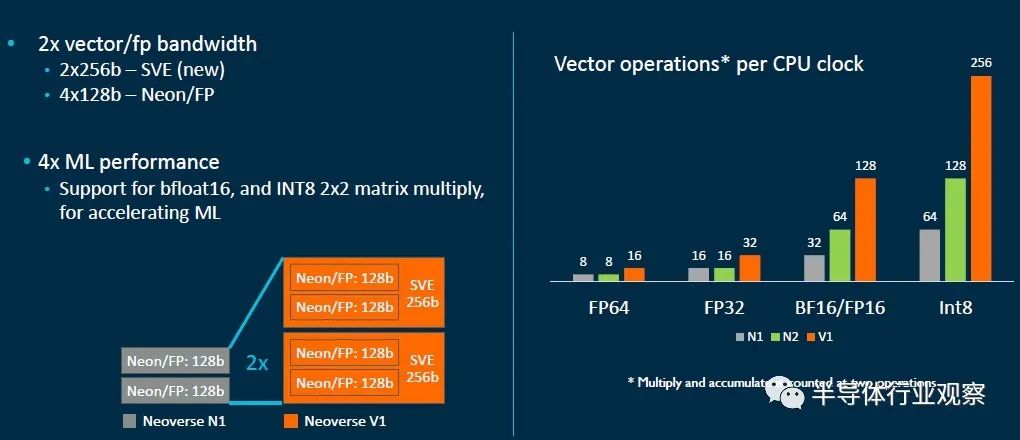
与Ares N1内核相比,Zeus V1内核在整数工作负载上可提供50%的单线程性能提高,这比Arm承诺的每代平均30%的性能还要好。V1设计具有SVE向量引擎的Armv8-A实现,在这种情况下,它将支持一对256位宽的向量,这些向量可以执行Bfloat16以及并行进行浮点和整数运算的混合。这将基本上与每个Intel Xeon SP内核中的AVX-512矢量单元以及AMD“ Milan” Epyc 7003内核中的一对256位FMA单元相匹配。
这是一个整洁的小图表,解释了N1,V1和N2内核中使用的向量单位的差异:
V1内核中的宽矢量与GPU加速器的并行度不高,但是它们运行得相当快,并且性能差异并不像您想象的那么小。如果您可以获得GPU的带宽(大约是GPU的计算密度的一半),并且没有任何混合编程麻烦,那么也许这是一种更聪明(或者至少更容易)的方式。大家似乎非常清楚,矢量化代码是性能的未来,而不管它是如何完成的以及使用哪种设备。
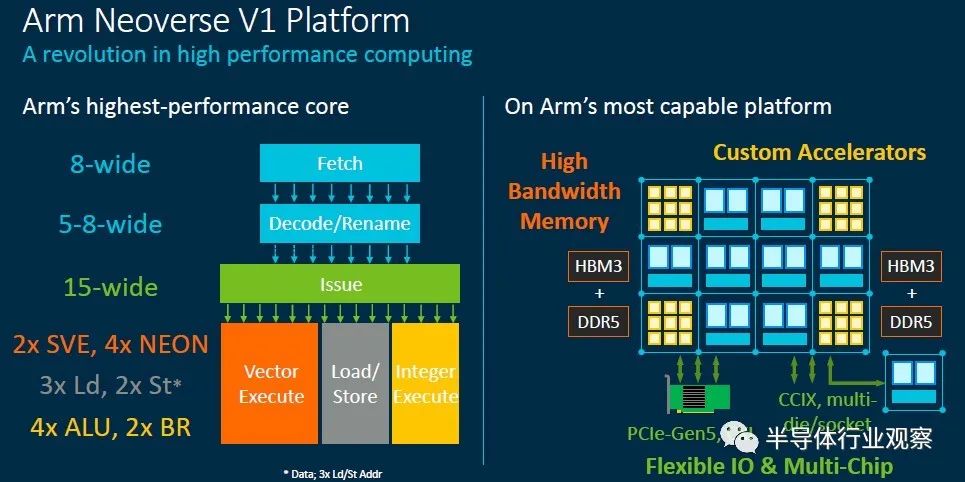
Zeus V1平台将为需要高带宽的用户提供HBM2E堆栈存储器的DDR5主存储器支持,并支持PCI-Express 5.0外围设备以及CCIX 1.1协议用于加速器和NUMA互连。这将或多或少地取决于这些技术的比率,并与英特尔未来的 “Sapphire Rapids”Xeon SP和AMD的“ Genoa” Epyc 7004s相提并论。
这些芯片公司必须在7纳米和5纳米工艺之间做出非常谨慎的选择,因此如果我们看到一些使厂商使用CCIX进行小芯片互连的小芯片实现,并不会感到惊讶。按照Arm的设计,允许使用7纳米或5纳米工艺实现核心,对于非核心区域,则可能允许使用14纳米或7纳米工艺蚀刻,因为减小晶体管尺寸会最大程度地降低其电压泄漏问题。然而鉴于现在对芯片的巨大需求以及7纳米或5纳米制造能力的局限,做出这些呼吁将非常困难。
Zeus V1在技术上符合Armv8.4 ISA和AMBA CHI.D片上互连规范,这意味着它支持SVE向量。实际上,这是Arm的第一个本地化SVE实现,它支持将这对256位SVE单元作为128位NEON加速器的四路运行,这对于那些将应用程序调整为在Arm GPU加速器上运行的用户来说非常有用。V1核心增强了nested virtualization,内存分区和加密技术,并在可靠性和可伸缩性方面进行了许多改进。它还从Armv8.5规范以及Armv8.6规范的SVE引擎中的Bfloat16和Int8处理中拉开了深远的持久性和推测障碍。可以肯定的是,V1内核中的内容比N1内核中的更多。
在设计中,没有提到的的是同时多线程或SMT。Arm已从其许多服务器芯片许可证持有者的观点出发,认为良好的围墙不会减少嘈杂的邻居,并且不会对其内核进行线程化,因此出于性能和安全性原因,可以隔离最小的计算单元(即内核)。
此设计中的许多内容都针对百亿级HPC,而SiPearl为欧洲第一台使用V1内核的百亿级计算机设计加速器并非巧合。
“在考虑百亿亿次级系统时,我们在CMN-700互连和核心中都牢记了一些设计目标,” Arm基础设施产品管理高级总监Brian Jeff告诉The Next Platform。“最重要的是性能,这很重要,因为在这些系统中,通常您连接到具有真正强大功能的GPU或其他加速器,但根据Amdahl’s law,它们通常可以等待单线程工作负载。但是性能对于在这些计算机上运行的工作负载也很重要。”
内存和I / O带宽显然也很重要,因此保持所有这些平衡也很重要,因此没有一个组件会等待很多时间。
考虑到所有这些,V1内核是Arm进入该领域以来性能最高的内核,该平台也将把带宽限制推到了极限。
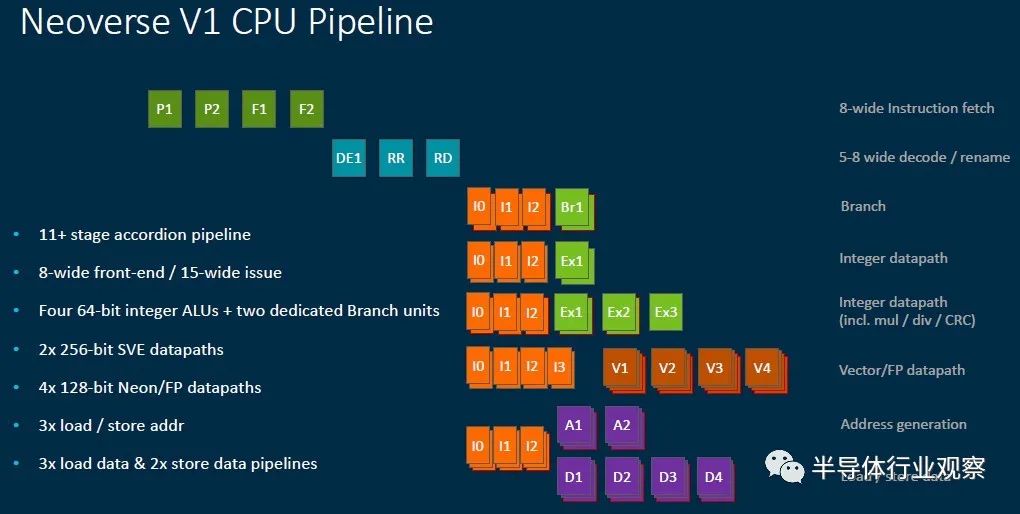
这是深入研究内核以及大规模芯片中V1设计元素的理论用法:
“这一切都始于一个非常好的前端,”在Arm中央工程部门从事内核工作的杰出工程师Chris Abernathy解释说。
“ V1分支预测器与N1内核中的分支预测器一样,已与指令提取分离,这使得分支预测可以提前运行并将指令预取到L1指令缓存中。这是我们微体系结构的一个非常重要的特征。为了提高基准测试和实际工作负载的性能,我们扩大了分支预测带宽。”
分支预测器每个周期有两个32字节的flights
,其分支目标缓冲区(BTB)增大了33%,达到8 KB。
Abernathy说,这个想法是要捕获更多具有更大指令足迹的分支,同时还可以为更紧凑,更小的内核降低分支等待时间。
其他提高分支准确性以及将可跟踪的代码区域数量加倍的调整,确实有助于Java工作负载和其他具有较大且稀疏代码区域的应用程序。
新的V1前端的最终结果是分支错误预测减少了90%,前端停滞减少了50%。
根据Abernathy的说法,V1设计也在推动宽度和深度的极限。内核每个周期可以发送8条指令,是N1内核的两倍,并且指令高速缓存的解码带宽每个周期提高4倍至5倍。内核中的指令解码延迟也减少了1个周期。V1内核中的乱序执行窗口大小也要大一倍,这为内核暴露了更多的指令并行性,以使自己能够处理任务。整数分支执行单元增加了一倍(到两个),算术逻辑单元(ALU)的数量每个内核增加了25%,达到四个。加载/存储单元和缓冲区都得到了提升,许多功能的宽度或带宽(或两者)加倍,最终结果是V1内核比N1内核的流传输带宽性能提高了45%。
最终结果是,在相同的频率下,V1内核在N70内核上具有比N1内核高50%的每个内核(IPC)指令,如果客户希望在时钟速度上牺牲一点性能,他们可以从根本上减少功率。我们不希望客户购买基于V1内核的服务器CPU来做到这一点。这是一辆有肌肉的汽车,它将运行迅速且充满激情。
现在,我们谈一下Perseus N2的内核和CPU设计,该设计针对每美元性能和每瓦性能进行了优化,而不仅仅是像V1内核和CPU那样不惜一切代价提高性能极限。如果V1是肌肉车,则N2是跨界运动型多功能车。
Abernathy说N2内核上的前端与V1内核上的前端相似,但是该内核将基于Armv9-A架构,该架构具有各种有趣的安全功能,坦率地说,这些功能很少用于百亿亿次计算设施。
V1设计针对具有32到128个内核且散热范围在80瓦到350瓦之间的CPU,而N2内核则针对可能具有12到36个内核,运行功率在30瓦到80瓦之间的主流基础架构服务器。但这并不是说不会有N2芯片无法突破核心限制,我们认为Ampere Computing,AWS以及Nvidia可能会在某些设备中使用N2内核。(Ampere和AWS不太可能在各自的Altra或Graviton芯片中使用V1内核。)
N2确实是对N1的升级,在恒定频率下IPC提高了40%,功耗与N1大致相同,但其时钟速度提高了10%,并且内核和缓存可能更多,这得益于N1缩小到5纳米。
N2设计具有5个宽的调度单元,并且较少依赖于深度和宽度攻击来驱动V1内核具有的最佳性能。正如Abernathy所言,与N1相比,N2设计中的性能特征必须在功率效率和面积效率上“付出代价”,而这实际上是对采用新型Armv9-A架构的N1的优化,以及V1前端嫁接到了它上。可以将分支预测视为燃料喷射,并且V1的气缸比N2的多得多,并且还具有更多的燃料喷射器。一种是进行拉力赛,其中燃料费并不重要,但到达终点线的时间却很重要;另一种是在度假时进行长途旅行,而不用花费比在廉价旅馆更多的汽油费。
N2内核将占用多达30%的面积,并消耗更多的功率以提供40%的吞吐量,重要的是,N2内核将比V1内核小25%,因此您可以将更多的N2内核塞入给定的芯片中尺寸。那些繁琐的向量和繁琐的缓存不是免费的。CPU架构中没有任何东西。而且,除了Armv9-A架构中的所有安全功能之外,这就是为什么我们希望云构建人员希望N2设计胜于V1设计。如果他们(或者他们的芯片合作伙伴,如果他们不像AWS那样设计自己的芯片,或者微软正在这样做),我们不会感到惊讶,可以使用小芯片设计,再一次使用CCIX作为小芯片互连,并且可能将其核心限制提高到128个以上的内核像AMD的Epyc X86服务器CPU一样,突破了I / O和内存中心的局面。
这就是我们要做的,也许是在单插槽设计中,这实际上可以降低系统成本,并增加云实例的大小以及您可以分割的切片数量。
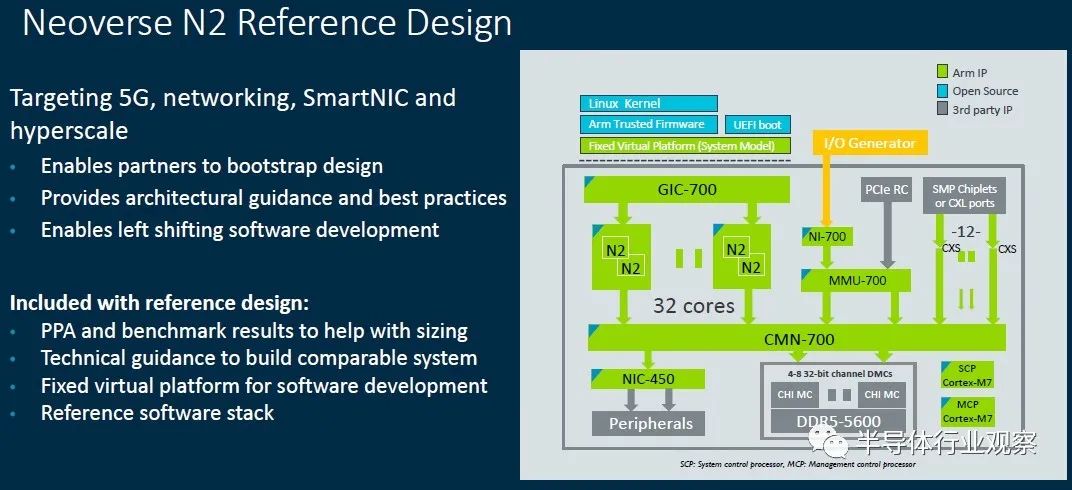
这是针对32核单芯片的,具有四到八个DDR5内存通道(运行频率为5.6 GHz,是的)和十二个用于NUMA扩展或用作CXL端口的端口。该参考资料没有施加任何限制,但是其模拟器将帮助公司为N2和硬件工程师编写软件,以考虑他们可能会做出的更改,以创建自己的N2设计。
★ 点击文末
【阅读原文】
,可查看本文原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2659内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备|封测
|射频|存储|美国|台积电
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!