来源:内容由半导体行业观察(ID:icbank)编译自「
anandtech
」,谢谢。
在过去的几年中,大量的处理器进入市场,其唯一目的是加速人工智能和机器学习工作负载。由于可能使用不同类型的机器学习算法,因此这些处理器通常专注于几个关键领域,但有一个局限性限制了它们,那就是您可以将处理器制造多大。
两年前,Cerebras揭开了芯片设计领域的一场革命:他推出的处理器与您的头部一样大——在12英寸晶圆上使用的面积与矩形设计所允许的面积一样大。据介绍,这个基于16纳米工艺打造的芯片可同时专注于AI和HPC工作负载。
今天,该公司正在发布其基于台积电7nm的第二代产品,其内核数量增加了一倍以上,而所有产品的数量都增加了一倍以上。
第二代WSE(Wafer Scale Engine)
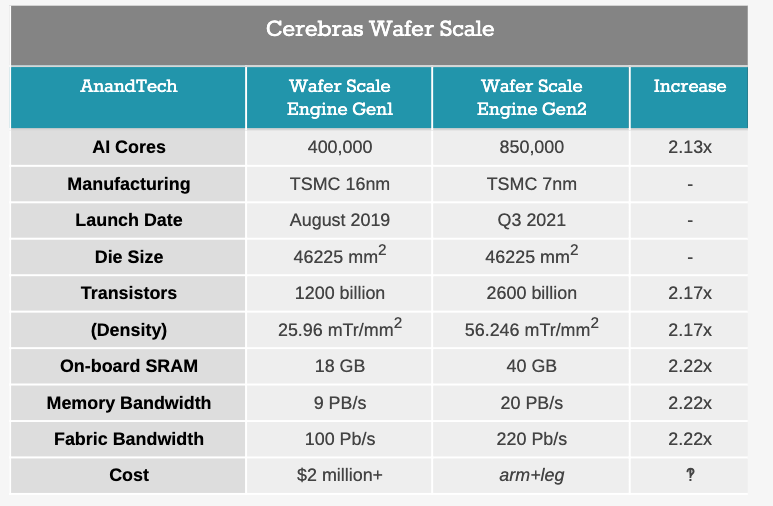
来自Cerebras的新处理器是基于台积电(TSMC)的N7工艺打造的。这使得逻辑可以按比例缩小,并在一定程度上缩小了SRAM,现在新芯片上具有850,000个AI内核。
从下图我们可以看到,基本上,有关新芯片的所有内容都超过了2倍:
与最初的处理器(称为晶圆级引擎(Wafer Scale Engine,WSE-1))一样,新的WSE-2在46225 mm 2的面积上集成了成千上万的AI核。在这个空间里,Cerebras集成了2.6万亿个晶体管,构建了850000个AI内核。相比之下,市场上第二大AI CPU约为826 mm 2,具有0.054万亿个晶体管。Cerebras还引用了1000倍的板载内存,带有40 GB的SRAM,而Ampere A100则为40 MB。
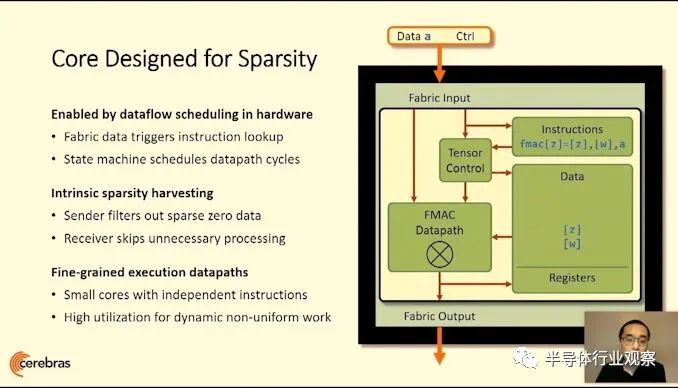
核心与带有FMAC数据路径的2D Mesh连接。Cerebras通过设计一种可以绕开任何制造缺陷的系统来实现100%的良率。
最初,Cerebras拥有1.5%的额外核心来容纳缺陷,但由于台积电(TSMC)的工艺如此成熟,因此我们被告知这太多了。Cerebras与WSE的目标是提供一个通过创新专利设计的单一平台,该平台允许用于AI计算的更大处理器,但也已扩展到更广泛的HPC工作负载中。
设计的关键是自定义的图形编译器,它采用pyTorch或TensorFlow并将每一层映射到芯片的物理部分,从而允许在数据流过时进行异步计算。拥有如此大的处理器意味着数据永远不必掉队,也不需要在内存中等待,不浪费功率,并且可以以流水线的方式连续地移至计算的下一个阶段。编译器和处理器的设计还考虑到了稀疏性,无论批处理大小如何都可以实现高利用率,或者可以使参数搜索算法同时运行。
Cerebras的第一代WSE作为CS-1的完整系统的一部分一起打包出售,该公司有数十个已部署并运行了已部署系统的客户,其中包括许多研究实验室,制药公司,生物技术研究,军事以及石油和天然气行业。天然气工业。劳伦斯·利弗莫尔(Lawrence Livermore)将一台CS-1与其23 PFLOP“拉森”超级计算机配对。匹兹堡超级计算机中心以500万美元的价格购买了两个系统,并将这些系统连接到他们的Neocortex超级计算机上,以实现同步AI和增强的计算能力。
Cerebras现在以15U盒的形式出售完整的CS-1系统,其中包含一个WSE-1和12x100 GbE,十二个4 kW电源(6个冗余,峰值功率约23 kW),并且在某些机构中的部署与HPE的SuperDome Flex配对。新的CS-2系统共享相同的配置,尽管内核数量增加了一倍以上,板载内存也增加了一倍,但功耗仍然相同。与其他平台相比,这些处理器在15U设计中垂直排列,以便在如此大的处理器上易于访问以及内置的液体冷却。还应该注意的是,这些前门是用单块铝加工而成的。
Cerebras设计的独特性能够超越通常在制造过程中出现的物理制造限制,即标线限制。处理器的设计限制为芯片的最大尺寸,因为很难通过十字线连接两个区域。这是Cerebras带到桌上的秘密的一部分,该公司仍然是唯一一家提供这种规模处理器的公司-Cerebras开发并获得了用于制造这些大型芯片的相同专利仍在这里发挥作用,第二代WSE将内置于CS-2系统中,其在连通性和视觉方面与CS-1相似。
相同的编译器和带有更新的软件包使已在第一个系统上试用AI工作负载的任何客户在部署它们时都可以使用第二个系统。Cerebras一直在进行更高级别的实现,以通过添加三行代码并使用Cerebras的图形编译器,使具有标准化TensorFlow和PyTorch模型的客户非常快速地同化其现有的GPU代码。然后,编译器将整个850,000个内核划分为每层的各个段,从而允许以流水线方式进行数据流而不会造成停顿。芯片还可以同时用于多个网络以进行参数搜索。
Cerebras指出,拥有如此庞大的单芯片解决方案意味着跨100多个AI芯片的分布式训练方法的障碍现在已经远远地移开了,以至于在大多数情况下都不需要这种过多的复杂性–为此,我们看到了CS- 1部署到超级计算机的单个系统。
但是,Cerebras指出,两个CS-2系统将在一个标准的42U机架中提供170万个AI内核,或者三个系统在一个更大的46U机架中提供255万个(假设一次有足够的功率!)来替换一打机架的替代计算硬件。
在Hot Chips 2020,该公司首席硬件架构师Sean Lie表示,Cerebras对客户的主要好处之一是能够简化工作负载,以前需要使用GPU / TPU机架,而是可以以计算相关的方式在单个WSE上运行。
作为一家公司,Cerebras在多伦多,圣地亚哥,东京和旧金山拥有约300名员工。该公司首席执行官安德鲁·费尔德曼(Andrew Feldman)表示,作为一家公司,他们已经实现了盈利,已经部署了CS-1的客户很多,并且在启动商业系统时已经有更多的客户在远程试用CS-2。
除了AI之外,由于芯片的灵活性使流体动力学和其他计算仿真成为可能,因此Cerebras在典型的商业高性能计算市场(例如,石油和天然气和基因组学)中引起了很多客户。CS-2的部署将于今年晚些时候在第三季度进行,价格已从2-3百万美元升至“几百万”美元。

使用哥斯拉以获得尺寸参考
★ 点击文末
【阅读原文】
,可查看本文原文链接!
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2652内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
晶圆|集成电路|设备|封测
|射频|存储|美国|台积电
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!