最新MLPerf 1.1测试:英伟达多个服务器合作厂商亮相
2021-12-03
14:02:50
来源: 互联网
点击
MLPerf是由学术界、研究实验室和业界人士共同组成组织,旨在打造公正且能够反映实际应用情境的AI运算测试基准,最近发表的成绩为AI训练1.1版。在最新的MLPerf 1.1训练效能测试中,NVIDIA在全部8个项目中都变现亮眼,并且其AI在过去3年的时间内性能表现提升了20倍。

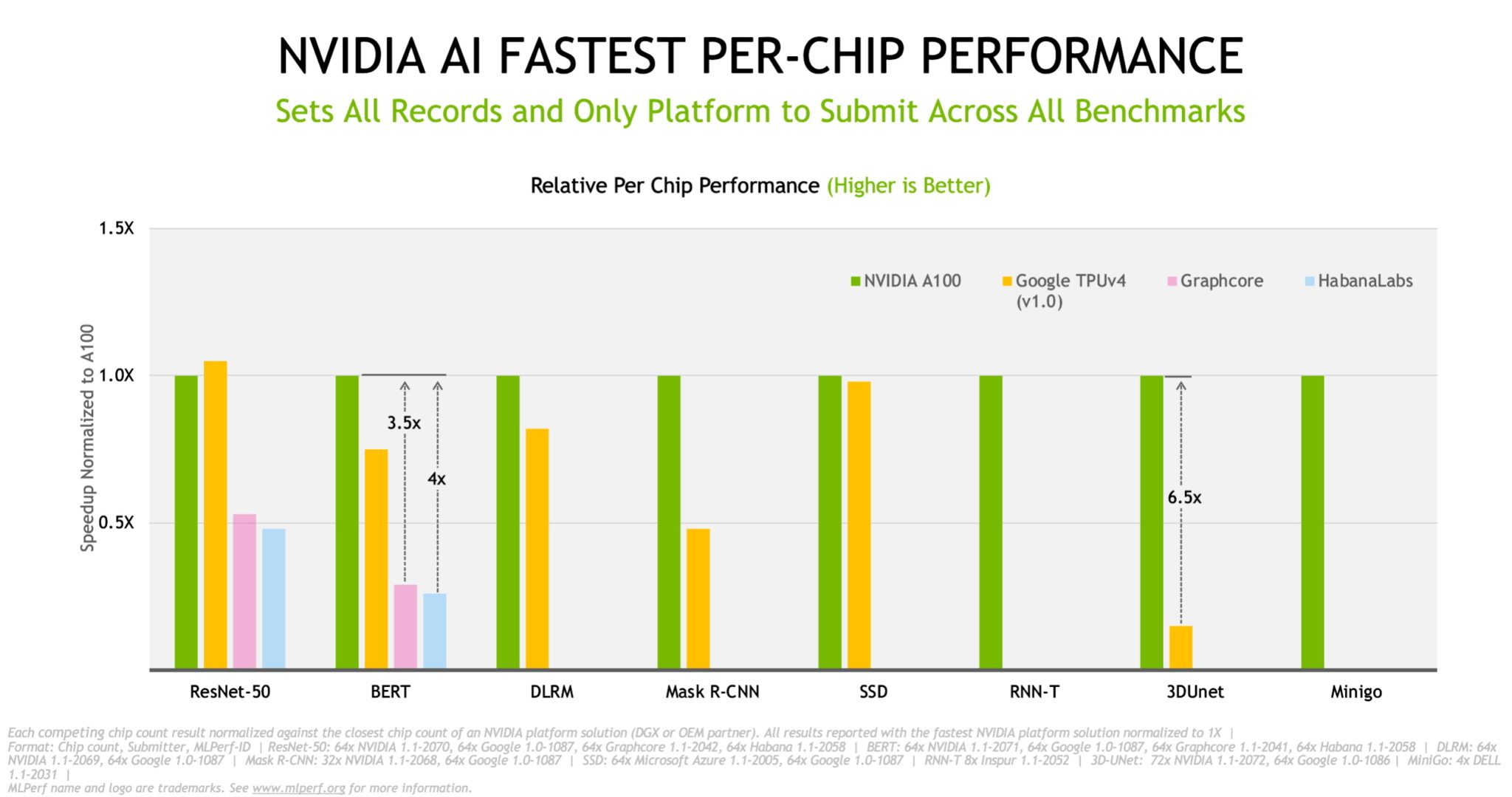
图:NVIDIA A100 GPU 在所有八项 MLPerf 1.1 测试中均实现最好的每单芯片训练性能
10家服务器厂商提交MlPerf测试
在今天宣布的 MLPerf 训练 1.1 结果中,共有 10 家 NVIDIA 合作伙伴提交了本轮测试结果,其中包含 8 家 OEM 和 2 家云服务提供商。它们占所有提交的 90% 以上。他们提交的范围展示了 NVIDIA 平台的广度和成熟度,该平台为各种规模的企业提供最佳的解决方案。
8家OEM厂商是百度 PaddlePaddle、戴尔科技、富士通、技嘉科技、慧与、浪潮、联想和 Supermicro ,他们提交了基于本地数据中心的结果(单节点和多节点任务)。其中浪潮凭借其八路GPU服务器NF5688M6 和NF5488A5液冷服务器在单节点性能方面创下了最多记录。戴尔和 Supermicro 在四路 A100 GPU 系统上创下了记录。
云服务提供商微软的Azure在MLPerf 基准测试中首次亮相,在训练 AI 模型方面,Azure 的 NDm A100 v4 实例的速度遥遥领先。在英伟达的加持下,云服务厂商将更上一层楼。它运行了新一轮的每项测试,扩展到多达 2,048 个 A100 GPU,如下图所示。Azure不仅展示了出色性能,而且在美国的六个地区,现在所有人都可以租借和使用其出色性能。

图:在新一轮的测试中,NVIDIA AI 训练所有模型的速度都快于替代方案。

图:微软AZURE NDm A100 V4 -世界上最快的云实例
在上图1中我们还可以看到,英伟达A100在Selene上的优越性能。Selene 是NVIDIA内部基于模块化NVIDIA DGX SuperPOD架构构建的AI超级计算机,借助NVIDIA InfiniBand网络和NVIDIA软件栈进行扩展,A100在Selene上实现了最快的AI训练速度。NVIDIA加速运算资深总监Paresh Kharya也在会后访谈中表示,Selene是以超级计算机为基础的运算平台,而Microsoft Azure NDm A100 v4则是云端虚拟机器,二者的架构截然不同,但都可透过A100运算卡达成运算需求,可见NVIDIA的硬件产品与软件堆栈可以满足各种尺度的使用需求。
值得一提的是,仅在过去 18 个月,NVIDIA A100 GPU 的性能就提升了 5 倍以上。这要归功于软件的持续创新,这也是NVIDIA目前工作的重心。

图:NVIDIA A100 GPU 的性能就提升了 5 倍以上
AI 训练是一项需要大量投入的大型工作。NVIDIA希望用户借助他们选择的服务或系统以创纪录的速度训练模型。因此,NVIDIA将 NVIDIA AI 与面向云服务、主机托管服务、企业和科学计算中心的产品相结合。
NVIDIA的合作伙伴之所以积极参与,是因为他们知道 MLPerf 是唯一符合行业标准、经过同行评审的 AI 训练和推理基准测试。对于评估 AI 平台和供应商的客户来说,这是一个有价值的工具。
AI性能3年提高20倍,英伟达做了哪些工作?
而纵观英伟达AI过去的表现,自从三年前 MLPerf 测试首次亮相,NVIDIA 的性能提高了 20 倍以上。这种大规模加速源于NVIDIA在全栈 GPU、网络、系统和软件方面取得的进步。

图示:NVIDIA AI 在三年内实现了 20 倍以上的改进
而英伟达取得这样新进展,主要是多项软件改进。例如,借助一类新的内存复制操作,NVIDIA在针对医学成像的 3D-UNet 基准测试中实现 2.5 倍的操作加速。
再者,得益于微调 GPU 以进行并行处理的方式,NVIDIA在针对物体检测的 Mask R-CNN 测试中实现 10% 的速度提升,而在针对推荐系统的测试中实现了 27% 的提升。NVIDIA只是重叠了独立操作,这种技术尤其适合跨多个 GPU 运行的作业。
除此之外,NVIDIA扩展了 CUDA 图形的使用范围,尽可能减少与主机 CPU 的通信。得益于此,NVIDIA在针对图像分类的 ResNet-50 基准测试中实现了 6% 的性能提升。
NVIDIA在 NCCL 上实施了两种新技术。NCCL 是NVIDIA的库,用于优化 GPU 之间的通信。对于 BERT 等大型语言模型,这样可以将结果加速高达 5%。
NVIDIA使用的所有软件均在 MLPerf 仓库提供,因此每个人都可以获得NVIDIA的出色结果。NVIDIA不断将这些优化整合到 NGC(NVIDIA的 GPU 应用程序软件中心)上的容器。它是全栈平台的一部分,已在新的行业基准测试中得到验证,可从各种合作伙伴处获得,能够处理当今真正的 AI 作业。
自 MLPerf 基准测试开始以来,人工智能训练性能的提升“成功地大大超过了摩尔定律” 。晶体管密度的增加将使早期版本的 MLPerf 基准测试与 2021 年 6 月之后的基准测试之间的性能提高一倍多一点。但是软件、处理器和计算机架构的改进使 MLPerf 基准测试的速度提高了 6.8-11 倍。在1.1 版的最新测试中,最佳结果比 6 月份提高了 2.3 倍。人工智能训练正在超越摩尔定律,英伟达AI性能的提升提供了有利的证明。
责任编辑:sophie
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 NVIDIA重磅出击:三台计算机助力人形机器人飞跃
- 2 TSN芯片,上车!
- 3 奕行智能(EVAS Intelligence)完成数亿元A轮融资,加速推出RISC-V计算芯片产品,共同助力新时代到来
- 4 智能驾驶拐点将至,地平线:向上捅破天,向下扎深根
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号