
硬核国产EDA,已跨入智算创新时代
2024-09-25
16:54:45
来源: 李寿鹏
点击
在算力即国力的智算时代,算力芯片设计规模和复杂度大幅提升,封装、工艺和系统设计也都面临着前所未有的挑战。尤其恰逢日益激烈的竞争态势、日趋严苛的投资环境以及风险剧增的地缘政治带来的叠加影响,国产EDA面临着多重且紧迫的时代考题。与此同时,EDA行业自身的特点也带来了诸多挑战,如较高的技术壁垒、专家人才的紧缺以及实际部署的迭代演进等。
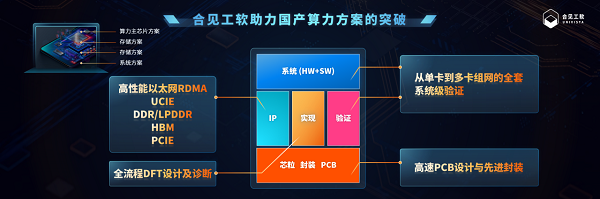
合见工软的高速接口IP解决方案已实现了国产化技术突破,引领智算、HPC、通信、自动驾驶、工业物联网等领域大算力芯片的性能突破及爆发式发展。
为此,本土EDA从业者也正在思考,如何能将国产EDA工具推向先进水平,并在国际竞争中占据一席之地。特别是在以人工智能驱动的智算时代科技比拼的当下,EDA工具对于支撑中国智算时代驱动的集成电路产业发展至关重要。
面对这些挑战,国产EDA需要持之以恒的攻坚,则无旁骛的专注技术创新,坚持以客户为中心,加速产品迭代,以应对变化并抓住机遇。
智能时代,对国产EDA提出新需求
生成式AI引爆了智算产业的高速扩张,算力已成为数字时代的关键源动力,也是国家科技实力的基石与体现。智算系统中,芯片为整个架构提供算力基础支撑,每一次大模型的训练和推理参数量正在呈现指数级增长,带动着作为算力基础设施的算力芯片GPU和CPU芯片爆发式的自主化需求。同时,智算领域为芯片设计也带来了多重挑战,芯片的复杂度呈现大幅的提升,严苛的面世时间要求设计和验证工作更加准确而高效,对系统级设计及软硬件协同的要求也更为复杂。这些新的挑战颠覆了既往的传统芯片设计方法,同时持续推升EDA工具研发的复杂度。
以GPU、AI芯片为主的智能算力,效率更高,满足大量数据的并发处理需求,采用400G/800G高带宽,低延迟的网络,支持大量数据传输。同时海量算力需求依托 AI 服务器,增配高算力 GPU 芯片。在系统级,PCB 作为算力芯片基座与信号传输通道,对服务器性能提升至关重要。
智算时代的爆发对国产EDA的支撑提出了严苛的时间表,时不我待。为了迎接智算时代带来的高需求推动力,国产超算/智算芯片行业面临着设计、工具与制造多重限制,以及复杂的系统的应用软硬件需求,和非常严苛的产品面世时间。中国芯片设计领域对EDA的需求已经不同于往日, 如何破局给整个产业链带来了全新的挑战,国产EDA产业作为芯片行业的核心环节,既面临严峻挑战,也迎来了巨大发展机遇和广阔成长空间。
以上种种因素,都驱动着中国高端数字芯片设计面临三个迫切的需求:第一、毫无疑问的国产EDA工具问题;第二、系统级上改善芯片性能,以及解决软硬件协同的挑战,从更早期的阶段开始系统联动设计的考量;第三,更好的支撑国内数字大芯片客户的需求,包括芯粒(Chiplet)时代所带来的最新高速接口IP和系统级设计工具等领域。
作为国内领先的集成电路设计EDA及工业软件企业,上海合见工业软件集团有限公司(简称“合见工软”)以三年推出20余款产品的创新速度、硬核的技术实力获得了国内集成电路行业的广泛认可。公司在回答时代给予的考题的同时,也引领了产业发展、技术创新和生态完善的国产EDA新态势。合见工软的创新战略,也从解决关键卡脖子问题,提升为打造技术领先优势,对标国际垄断产品性能,以应对目前智算大芯片所带来的技术挑战,提供高水平的数字芯片EDA及IP解决方案。
9月24日,在IDAS 2024设计自动化产业峰会期间隆重召开了“2024合见工软年度新产品发布会”,会上重磅发布了多款国产自主自研EDA及IP产品,其中多项产品技术达到了国际先进性能水平,为中国本土EDA技术突破提供了强大的推动力。

合见工软产品发布会现场
EDA和IP齐发,11款产品震撼亮相
在本次发布会上,合见工软发布的产品包括国产硬件仿真器中首台可扩展至460亿逻辑门设计的硬件仿真平台UVHP、新一代单系统先进原型验证平台、DFT全流程平台、电子系统设计工具和五款高速接口IP产品在内的11款创新产品。
此次一年一度的产品发布,正是合见工软坚守初心、识势而为、多措并举的扎实发展道路的体现。合见工软针对大规模算力集群高速发展给数字大芯片设计带来的多重挑战,发布了多个创新产品以供应对,包括算力主芯片方案、存储方案、互联方案和系统方案。
EDA²副理事长、深圳市海思半导体有限公司CIO刁焱秋,清华大学、复旦大学、上海大学等学界代表,以及知名半导体公司高管及客户共计超过400位代表,共同出席了合见工软新产品发布会。
发布会上,合见工软董事长潘建岳先生作开幕致辞,EDA²副理事长刁焱秋先生进行特邀致辞。合见工软董事长潘建岳先生表示,合见工软以世界级EDA公司为远景,目标为中国集成电路行业提供国际领先水平的创新EDA工具,契合国家加快发展新质生产力的重要要求。纵览历史,EDA发展始终走在集成电路行业的最前端,引领创新。从创立伊始,合见工软始终以产品技术为核心,保持着闭关研发、夯实基础,几年间合见工软已从一家初创企业,发展为国内数字芯片EDA的领导企业,同时更跨越到系统级和IP多个领域,推出的EDA及IP产品以迭代到具有全球竞争力为目标。目前合见工软成为国内首家可以为数字大芯片设计提供“EDA+IP+系统级”联合解决方案的供应商,刷新了EDA研发的中国速度,引领了国产EDA创新时代。潘建岳强调,合见工软一路走来得到了很多用户及合作伙伴的支持,未来合见工软将继续保持技术攻坚和产品创新,助力国内集成电路设计企业乃至全球产业的进步。

合见工软董事长潘建岳致辞
本次发布会的重磅环节是由合见工软首席技术官贺培鑫先生带领的合见工软技术专家团队发布EDA创新趋势和全新的十一款产品。这些产品覆盖了数字前端、数字后端、系统级和接口IP多个领域。面对全球掀起的AI算力中心竞赛,我国也在大力规划数据中心算力集群,智算中心建设为芯片设计和系统带来了更为复杂和紧迫的挑战,CTO贺培鑫先生阐释了EDA技术的发展趋势和合见工软的创新战略布局。

合见工软首席技术官贺培鑫主题演讲
具体而言,合见工软本次发布的十一款创新产品如下所示:
数字验证全新硬件平台:
数据中心级全场景超大容量硬件仿真加速验证平台UniVista Hyperscale Emulator(简称“UVHP”)
全新一代商用级、单系统先进原型验证平台PHINE DESIGN Advanced Solo Prototyping(简称“PD-AS”)
数字实现EDA工具:国产自主知识产权的可测性设计(DFT)全流程平台UniVista Tespert:
高效缺陷诊断软件工具UniVista Tespert DIAG
高效的存储单元内建自测试软件工具UniVista Tespert MBIST
PCB板级设计工具:新一代电子系统设计平台UniVista Archer
一体化PCB设计环境UniVista Archer PCB
板级系统电路原理设计输入环境UniVista Archer Schematic
全国产自主知识产权高速接口IP解决方案:
UniVista UCIe IP——突破互联边界、下一代Chiplet集成创新的全国产UCIe IP解决方案
UniVista HBM3/E IP——拓展大算力新应用、加速存算一体化的全国产HBM3/E IP解决方案
UniVista DDR5 IP——突破数据访问瓶颈、灵活适配多元应用需求的全国产DDR5 IP解决方案
UniVista LPDDR5 IP——大容量高速率低功耗的全国产LPDDR5 IP解决方案
UniVista RDMA IP——助力智算万卡互联、200G和400G高性能的全国产RDMA IP解决方案
数据中心级全场景超大容量硬件仿真加速验证平台UniVista Hyperscale Emulator(简称“UVHP”)
全新一代商用级、单系统先进原型验证平台PHINE DESIGN Advanced Solo Prototyping(简称“PD-AS”)
数字实现EDA工具:国产自主知识产权的可测性设计(DFT)全流程平台UniVista Tespert:
高效缺陷诊断软件工具UniVista Tespert DIAG
高效的存储单元内建自测试软件工具UniVista Tespert MBIST
PCB板级设计工具:新一代电子系统设计平台UniVista Archer
一体化PCB设计环境UniVista Archer PCB
板级系统电路原理设计输入环境UniVista Archer Schematic
全国产自主知识产权高速接口IP解决方案:
UniVista UCIe IP——突破互联边界、下一代Chiplet集成创新的全国产UCIe IP解决方案
UniVista HBM3/E IP——拓展大算力新应用、加速存算一体化的全国产HBM3/E IP解决方案
UniVista DDR5 IP——突破数据访问瓶颈、灵活适配多元应用需求的全国产DDR5 IP解决方案
UniVista LPDDR5 IP——大容量高速率低功耗的全国产LPDDR5 IP解决方案
UniVista RDMA IP——助力智算万卡互联、200G和400G高性能的全国产RDMA IP解决方案
合见工软自成立以来一直以国际先进水平为目标,多产品线并行研发,在数字芯片EDA技术达到创新引领的同时,在技术更为领先、挑战更复杂的数字芯片设计和验证领域已有多项创新成果,填补了部分国产EDA工具关键点的技术空白,展现了合见工软强大的研发实力和对客户的支持能力。特别是在IP领域实现快速覆盖,现已成为国内首家同时布局EDA+IP,并已得到多家商业客户的成功流片,数百家客户的商业部署。
全场景验证硬件系统彰显自主创新力
AI智算、HPC超算、AD/ADAS智驾、5G、以及超大规模网络等应用领域,正推动芯片设计的规模、功能集成度和软硬件系统级复杂度大幅提升。这对验证工具的能力提出了更高要求,并带来了多样化场景验证的挑战。验证工具除了必须为芯片设计开发提供更快速准确的编译和更高效的调试能力外,还必须具备更灵活、更统一的全场景验证平台。这不仅可提升故障纠错效率和验证吞吐量,还能降低大规模复杂芯片流片的风险,并为软硬件协同仿真验证提供强大的数字孪生能力。
合见工软宣布推出数据中心级全场景超大容量硬件仿真加速验证平台UniVista Hyperscale Emulator(简称“UVHP”),为国产自研硬件仿真器中首台可扩展至460亿逻辑门设计的产品,并支持多系统进一步扩展,可大幅提升仿真验证效率,缩短超大规模芯片的仿真验证周期。超大容量硬件仿真加速平台UVHP基于合见工软自主研发的新一代专有硬件仿真架构,采用先进的商用FPGA芯片、独创的高效能RTL综合工具UVSyn、智能化全自动编译器,以及丰富的高低速接口和存储模型方案,为超大规模ASIC/SOC的仿真验证提供强大支持。
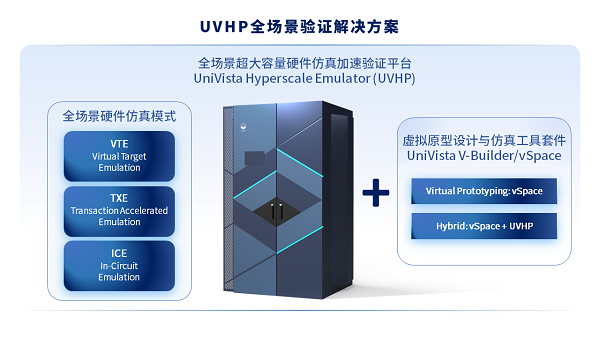
合见工软全新推出的硬件仿真加速验证平台UVHP,达成了国产自研硬件仿真加速平台的能效和容量新高度。该平台将硬件仿真系统的算力提升至数据中心级别,系统规模支持1.6亿门到460亿门可调,是目前国产同类产品中容量最大的,同时其性能可对标国际先进产品。全场景验证模式包括纯硬件环境、XTOR和Hybrid等多种方案,为芯片系统级软硬件协同设计及验证提供了强大的算力支撑。
合见工软全新推出的硬件仿真加速验证平台UVHP,达成了国产自研硬件仿真加速平台的能效和容量新高度。该平台将硬件仿真系统的算力提升至数据中心级别,系统规模支持1.6亿门到460亿门可调,是目前国产同类产品中容量最大的,同时其性能可对标国际先进产品。全场景验证模式包括纯硬件环境、XTOR和Hybrid等多种方案,为芯片系统级软硬件协同设计及验证提供了强大的算力支撑。
客户评价:
燧原科技COO张亚林表示:“我们与合见工软是长期的战略合作伙伴。在我们之前的算力芯片项目中,合见工软的UVHS双模工具作为主要验证平台,凭借出色性能和全面的智算解决方案,大幅提升了我们AI软件算法的开发效率,获得工程团队的一致好评。我们一直期望合见工软推出更高集成度的大容量硬件加速器,如今UVHP平台的问世,填补了国产商用硬件加速器在千片FPGA规模级别的空白。我们期待UVHP以及其配套虚拟平台和hybrid方案在未来项目中的表现,会继续与合见工软携手,共同推动国产算力平台的发展。”
国内首发!创新商用级单系统先进原型验证平台
FPGA原型验证平台能够实现更快的软件运行速度,大幅缩短软件运行时间和验证迭代周期,同时也使得软硬件协同数字孪生设计开发成为可能,助力加速芯片上市。随着用户设计的复杂度、灵活度等需求的挑战不断涌现,芯片验证亟需更大规模且兼具灵活性、易用性及更高性能的单系统原型验证平台。
合见工软推出全新一代商用级、单系统先进原型验证平台PHINE DESIGN Advanced Solo Prototyping(简称“PD-AS”),搭载AMD新一代超大自适应SoC——AMD Versal™ Premium VP1902 Adaptive SoC,采用先进工艺,整体设备性能提升两倍以上,并配套灵活便捷的操作界面、丰富多种的接口方案,可覆盖更大规模的芯片验证场景,将广泛应用于5G-WIFI通讯、智算、AIoT、智能汽车、RF-导航、RSIC-V IP、VR/AR等行业领域。

客户评价:
赛昉科技董事长兼CEO徐滔表示:“在开发和验证过程中,效率至关重要。赛昉科技通过先进的设计环境,能够快速定制符合客户需求的CPU,而验证和软件验证是确保质量的关键环节。客户对高质量产品的期望,促使我们对所有RISC-V IP进行全面的验证工作,包括功能验证、回归测试以及整个软件栈的验证。为此,我们借助合见工软单系统先进原型验证平台PD-AS系列1902平台和全场景验证硬件系统UVHS开展这些任务。前者用于单核和双核的开发,后者则适用于规模更大的四核以上系统。通过这些平台,赛昉每天能够执行数万亿次周期,大大提升了开发过程中的验证效率和问题识别速度。
随着产品复杂度和规模的不断提升,合见工软超大容量硬件仿真加速验证平台UVHP将持续支持赛昉未来的项目开发。UVHP卓越的性能和RTL调试能力,将帮助赛昉在更复杂的设计中实现快速验证和调试,加速复杂RISC-V核心的开发流程。”
合见工软全新一代PD-AS原型验证平台,可用于SoC、IP等芯片验证领域,适配各种验证场景需求,缩减测试进程,加快芯片面市,平台具有更大容量,等效逻辑门数约1亿门,比起上一代产品扩大了两倍以上;更快的速度及更丰富的接口扩展方案,覆盖了尽可能多的应用场景。
自研DFT全流程平台,助力半导体测试迈向新高度
为了满足人工智能、数据中心、自动驾驶等场景对大算力的需求,芯片尺寸和规模越来越大,单芯片晶体管多达百亿甚至千亿级别。同时,高阶工艺和先进封装如Chiplet等技术的应用,也大大增加了芯片的集成度与复杂度,设计与制造过程中芯片出现故障的几率大幅提升,对芯片测试DFT解决方案也提出了更高的要求。需要快速精准地发现故障,修复或者避开故障从而提升良率。同时需要进一步提升测试覆盖率,将一些测试流程左移,以减少缺陷逃逸率,避免增加成本或延误产品上市时间。
合见工软宣布推出国产自主知识产权的可测性设计(DFT)全流程平台UniVista Tespert。该平台集成了一系列高效工具,包括最新推出的高效缺陷诊断软件工具UniVista Tespert DIAG、高效的存储单元内建自测试软件工具UniVista Tespert MBIST,以及合见工软此前推出的测试向量自动生成工具UniVista Tespert ATPG。UniVista Tespert致力于为工程师提供更高效、更高质量的完整芯片测试平台化工具,满足现代芯片设计复杂度和封装技术挑战,助力客户提升产品质量和市场竞争力。
最新推出的UniVista Tespert DIAG是一款创新高效的缺陷诊断软件工具,自主研发了高效准确的诊断引擎,采用新一代数据结构,支持压缩和非压缩的测试向量诊断技术。其图形化界面提供了缺陷全景对照,帮助工程师快速定位和解决系统性缺陷,大幅提升芯片测试效率,加速产品上市时间。
同时推出的UniVista Tespert MBIST是一款先进存储单元自测试工具,集成了先进的IJTAG接口协议,提供直观易用的图形界面,支持多种测试算法和灵活的设计规则检查引擎。通过UVTespert Shell自动化平台,它有效提高了测试设置的效率和可靠性,特别针对先进工艺如FinFET进行了优化,为客户提供了全面的存储单元测试解决方案。
客户评价:
类比半导体高级总监王海金表示:“合见工软DFT全流程平台UniVista Tespert为我们在测试领域提供了全面的解决方案,极大地提升了我们的产品测试效率和可靠性。更值得一提的是,UniVista Tespert DIAG的图形化界面和高效的诊断引擎让我们能够更快速地定位和解决芯片缺陷,这对我们的项目进展至关重要。类比半导体作为模拟及数模混合芯片和解决方案供应商,专注于汽车智能驱动、线性产品、数据转换器等领域的芯片设计,产品主要面向工业和汽车等市场。与合见工软的深化合作,将帮助类比致力于为客户提供高品质芯片,为世界科技化和智能化发展提供底层的芯片支持。”
青芯半导体科技(上海)有限公司DFT技术总监吕寅鹏表示:“合见工软UniVista Tespert平台为我们提供了强大的DFT工具,帮助我们应对复杂芯片设计和测试的挑战,提高了产品质量和市场竞争力。我们在使用UniVista Tespert MBIST时,发现该工具对存储单元的测试管理非常有力,为我们的芯片设计团队提供了更多的设计自由度。我们相信这款工具能够得到更多的广泛应用,为芯片制造业带来更加精准、高效的解决方案。”
UniVista Tespert是合见工软更广泛的数字实现EDA产品组合的重要产品之一,目前已经实现了在汽车电子、高阶工艺芯片等领域的国内头部IC企业中的成功部署,应用于超过50多个不同类型芯片测试。
HBM3e领衔,完整IP组合打造大算力芯片强力引擎
合见工软宣布推出五款全新全国产自主知识产权高速接口IP解决方案,为用户提供了创新、高可靠性、高性能的网络IP、存储IP及Chiplet接口IP解决方案,应对智算时代所带来的网络互联、先进封装集成、高数据吞吐量等诸多挑战。
· UniVista UCIe IP——突破互联边界、下一代Chiplet集成创新的全国产UCIe IP解决方案
随着各类前沿高性能应用对算力、内存容量、存储速度和高效互连的需求持续攀升,传统大芯片架构的设计和能力越来越难以及时满足这些需求。Chiplet集成技术的出现开辟了一条切实可行的路径,使得各个厂商能够在芯片性能、成本控制、能耗降低和设计复杂性等方面实现新的突破。
作为Chiplet集成的关键标准之一,UCIe以开放、灵活、高性能的设计框架为核心,实现了采用不同工艺和制程的芯粒之间的无缝互连和互通。通过统一的接口和协议,UCIe可大幅降低同构和异构芯粒集成的设计复杂度,使设计人员能够更加专注于各个芯粒的功能实现和优化,从而加速产品开发进程。
UniVista UCIe IP产品已在智算、自动驾驶、AI等领域的知名客户的实际项目中得到广泛应用和验证,在真实场景中展现出卓越的性能表现和稳定可靠的品质。合见工软UCIe IP先进制程测试芯片现已成功流片,成为IP领域第二个经由硬件验证过的先进制程UCIe IP产品。
随着智能计算领域的高速发展,数据中心已逐步升级为智算中心,其中高性能计算芯片也已从CPU/DPU过渡到AI/GPU等大算力芯片。为了充分发挥大算力芯片的性能,大容量、高带宽、高速率、低功耗的内存解决方案成为了重要的发展方向。在大算力场景下,内存容量或带宽的限制会导致访存时延高、效率低,严重制约算力芯片性能的发挥。此外,随着数据传输速率的持续提升,芯片不仅需要保证高数据吞吐量,同时还必须兼顾低功耗,这已成为架构设计的关键重点关注点之一。
· UniVista UCIe IP——突破互联边界、下一代Chiplet集成创新的全国产UCIe IP解决方案
随着各类前沿高性能应用对算力、内存容量、存储速度和高效互连的需求持续攀升,传统大芯片架构的设计和能力越来越难以及时满足这些需求。Chiplet集成技术的出现开辟了一条切实可行的路径,使得各个厂商能够在芯片性能、成本控制、能耗降低和设计复杂性等方面实现新的突破。
作为Chiplet集成的关键标准之一,UCIe以开放、灵活、高性能的设计框架为核心,实现了采用不同工艺和制程的芯粒之间的无缝互连和互通。通过统一的接口和协议,UCIe可大幅降低同构和异构芯粒集成的设计复杂度,使设计人员能够更加专注于各个芯粒的功能实现和优化,从而加速产品开发进程。
UniVista UCIe IP产品已在智算、自动驾驶、AI等领域的知名客户的实际项目中得到广泛应用和验证,在真实场景中展现出卓越的性能表现和稳定可靠的品质。合见工软UCIe IP先进制程测试芯片现已成功流片,成为IP领域第二个经由硬件验证过的先进制程UCIe IP产品。
随着智能计算领域的高速发展,数据中心已逐步升级为智算中心,其中高性能计算芯片也已从CPU/DPU过渡到AI/GPU等大算力芯片。为了充分发挥大算力芯片的性能,大容量、高带宽、高速率、低功耗的内存解决方案成为了重要的发展方向。在大算力场景下,内存容量或带宽的限制会导致访存时延高、效率低,严重制约算力芯片性能的发挥。此外,随着数据传输速率的持续提升,芯片不仅需要保证高数据吞吐量,同时还必须兼顾低功耗,这已成为架构设计的关键重点关注点之一。
为保障芯片的高性能、低功耗,应对AI、ML、HPC等应用场景的发展,合见工软推出全国产Memory接口解决方案,包括:
· UniVista HBM3/E IP——拓展大算力新应用、加速存算一体化的全国产HBM3/E IP解决方案
UniVista HBM3/E IP包括HBM3/E内存控制器、物理层接口(PHY)和验证平台,采用低功耗接口和创新的时钟架构,实现了更高的总体吞吐量和更优的每瓦带宽效率,可帮助芯片设计人员实现超小PHY面积的同时支持最高9.6 Gbps的数据速率,解决各类前沿应用对数据吞吐量和访问延迟要求严苛的场景需求问题,可广泛应用于以AI/机器学习应用为代表的数据与计算密集型SoC等多类芯片设计中,已实现在AI/ML、数据中心和HPC等领域的国内头部IC企业中的成功部署应用。
· UniVista DDR5 IP——突破数据访问瓶颈、灵活适配多元应用需求的全国产DDR5 IP解决方案
UniVista DDR5 IP包括DDR5内存控制器、物理层接口(PHY)和验证平台,采用先进的设计架构和优化技术,经过严苛的实际应用场景验证和深度评估,可帮助芯片设计人员实现高达8800 Mbps的数据传输速率,支持单个最高64 Gb容量的内存颗粒,256 GB容量的DIMM并集成ECC功能,解决企业级服务器、云计算、大数据等应用领域对高可靠性、高密度和低延迟内存方案的场景需求问题,可广泛应用于数据中心/服务器、高端消费电子SoC 等多类芯片设计中,已实现在云服务、消费电子、服务器/工作站等领域的国内头部IC企业中的成功部署应用。
· UniVista LPDDR5 IP——大容量、高速率、低功耗的全国产LPDDR5 IP解决方案
UniVista LPDDR5 IP包括LPDDR5内存控制器、物理层接口(PHY)和验证平台,采用优化的设计架构,经过多种实际应用场景验证和评估,可帮助芯片设计人员实现高达8533 Mbps的数据传输速率,支持单个最高32 Gb容量的内存颗粒,并集成ECC功能,解决移动设备、IoT、汽车电子等应用领域对高性能、低功耗和小尺寸内存方案的场景需求问题,可广泛应用于移动设备、IoT和汽车电子SoC等多类芯片设计中,已实现在移动设备和IoT等领域的国内头部IC企业中的成功部署应用。
AI大模型时代,算力集群进行的分布式训练,节点间的通信消耗巨大,这使得通信网络成为了制约大模型训练效率的关键因素。除了训练芯片,推理芯片比以往需要更大规模的组网完成更大token的运算。组网规模、网络性能和可靠性等方面正在成为制约算力集群效率的突出问题。越来越多的芯片正通过基于以太网交换机的RoCEv2网络实现超大规模组网方案。为了保证大算力芯片能拥有完善的网络性能,在设计和验证网络功能上给众多AI芯片公司提出了新的挑战。
· UniVista HBM3/E IP——拓展大算力新应用、加速存算一体化的全国产HBM3/E IP解决方案
UniVista HBM3/E IP包括HBM3/E内存控制器、物理层接口(PHY)和验证平台,采用低功耗接口和创新的时钟架构,实现了更高的总体吞吐量和更优的每瓦带宽效率,可帮助芯片设计人员实现超小PHY面积的同时支持最高9.6 Gbps的数据速率,解决各类前沿应用对数据吞吐量和访问延迟要求严苛的场景需求问题,可广泛应用于以AI/机器学习应用为代表的数据与计算密集型SoC等多类芯片设计中,已实现在AI/ML、数据中心和HPC等领域的国内头部IC企业中的成功部署应用。
· UniVista DDR5 IP——突破数据访问瓶颈、灵活适配多元应用需求的全国产DDR5 IP解决方案
UniVista DDR5 IP包括DDR5内存控制器、物理层接口(PHY)和验证平台,采用先进的设计架构和优化技术,经过严苛的实际应用场景验证和深度评估,可帮助芯片设计人员实现高达8800 Mbps的数据传输速率,支持单个最高64 Gb容量的内存颗粒,256 GB容量的DIMM并集成ECC功能,解决企业级服务器、云计算、大数据等应用领域对高可靠性、高密度和低延迟内存方案的场景需求问题,可广泛应用于数据中心/服务器、高端消费电子SoC 等多类芯片设计中,已实现在云服务、消费电子、服务器/工作站等领域的国内头部IC企业中的成功部署应用。
· UniVista LPDDR5 IP——大容量、高速率、低功耗的全国产LPDDR5 IP解决方案
UniVista LPDDR5 IP包括LPDDR5内存控制器、物理层接口(PHY)和验证平台,采用优化的设计架构,经过多种实际应用场景验证和评估,可帮助芯片设计人员实现高达8533 Mbps的数据传输速率,支持单个最高32 Gb容量的内存颗粒,并集成ECC功能,解决移动设备、IoT、汽车电子等应用领域对高性能、低功耗和小尺寸内存方案的场景需求问题,可广泛应用于移动设备、IoT和汽车电子SoC等多类芯片设计中,已实现在移动设备和IoT等领域的国内头部IC企业中的成功部署应用。
AI大模型时代,算力集群进行的分布式训练,节点间的通信消耗巨大,这使得通信网络成为了制约大模型训练效率的关键因素。除了训练芯片,推理芯片比以往需要更大规模的组网完成更大token的运算。组网规模、网络性能和可靠性等方面正在成为制约算力集群效率的突出问题。越来越多的芯片正通过基于以太网交换机的RoCEv2网络实现超大规模组网方案。为了保证大算力芯片能拥有完善的网络性能,在设计和验证网络功能上给众多AI芯片公司提出了新的挑战。
合见工软全新推出国内领先的高带宽、低延迟、高可靠性的智算网络IP解决方案UniVista RDMA IP,助力智算万卡集群,主要功能包括支持200G、400G带宽的完整RoCEv2传输层、网络层、链路层、物理编码层,可帮助芯片设计人员实现快速的RDMA功能集成,解决智算芯片的高带宽需求问题,可广泛应用于AI、GPU、DPU等多类芯片设计中,相比于传统25G/50G RDMA互联方案,性能更领先,已实现在AI和GPU等领域的国内头部IC企业中的成功部署应用。
UniVista RDMA IP——助力智算万卡互联、200G和400G高性能的全国产RDMA IP解决方案。UniVista RDMA IP的四大优势包括:
更高的带宽利用率:支持超频点应用,比标准以太网提供多10%的带宽;支持灵活支持可配置报文头,包括可配置前导码、IPG、MAC帧头;支持超长报文,报文长度最高可达32K bytes。
更高的可靠性:支持RDMA的传输层的端到端重传,重传完成时间达到10us量级;提供基于以太网MAC层的端到端重传,重传完成时间达到us量级;支持以太网PHY层的点到点重传,重传完成时间达到100ns量级。
更灵活的组网方式:支持基于以太网PHY层协议的点到点直连;支持以太网PHY配置1拆2、1拆4,灵活支持8卡、16卡、32卡全互联;RDMA QP数量,WQE数量可配置,与直连协议可切换。
更低的延迟:优化FEC低延迟模式,在已有的RS272算法上进一步降低FEC的解码延迟;提供PAXI直连模式,通过以太网物理层实现C2C连接,降低延迟;简化UDP/IP以及MAC层协议,提供简化包头模式。
UniVista RDMA IP——助力智算万卡互联、200G和400G高性能的全国产RDMA IP解决方案。UniVista RDMA IP的四大优势包括:
更高的带宽利用率:支持超频点应用,比标准以太网提供多10%的带宽;支持灵活支持可配置报文头,包括可配置前导码、IPG、MAC帧头;支持超长报文,报文长度最高可达32K bytes。
更高的可靠性:支持RDMA的传输层的端到端重传,重传完成时间达到10us量级;提供基于以太网MAC层的端到端重传,重传完成时间达到us量级;支持以太网PHY层的点到点重传,重传完成时间达到100ns量级。
更灵活的组网方式:支持基于以太网PHY层协议的点到点直连;支持以太网PHY配置1拆2、1拆4,灵活支持8卡、16卡、32卡全互联;RDMA QP数量,WQE数量可配置,与直连协议可切换。
更低的延迟:优化FEC低延迟模式,在已有的RS272算法上进一步降低FEC的解码延迟;提供PAXI直连模式,通过以太网物理层实现C2C连接,降低延迟;简化UDP/IP以及MAC层协议,提供简化包头模式。
合见工软的高速接口IP解决方案已实现了国产化技术突破,引领智算、HPC、通信、自动驾驶、工业物联网等领域大算力芯片的性能突破及爆发式发展。
解决高速、多层PCB设计挑战:国产首款高端大规模PCB设计平台
随着电子系统技术的不断发展,产品的核心功能极大程度地依赖于高性能大规模集成电路实现,大规模、高性能集成电路的广泛应用,将电子系统的信号种类、数量、系统互连关系变得异常复杂。要实现复杂系统的精确描述,以确保电子系统设计的正确性与可靠性,对PCB及原理图设计方法与流程的更新换代提出了更严苛的要求,大规模、小型化、高密度、高速率已经成为板级系统的重要发展趋势。UniVista Archer平台是首款国产自主自研的高性能大规模PCB和原理图设计工具,支持的PCB设计规模已达到国内先进水平,能够实现更高密度的布局布线,并保障更快的软件运行速度,助力更智能化电子系统产品的发展。
合见工软宣布推出新一代电子系统设计平台UniVista Archer,作为自主知识产权的国产首款高端大规模PCB设计平台,满足日益复杂的电子系统设计需求,解决高速、多层PCB设计中带来的设计与仿真挑战,为电子系统和PCB板级设计工程师带来更高的性能与可靠性,并支持客户历史设计数据导入,易学易用。UniVista Archer平台包括领先的一体化PCB设计环境UniVista Archer PCB和板级系统电路原理设计输入环境UniVista Archer Schematic两款产品,采用全新的先进数据架构,部分产品性能大幅提升,精准洞察用户的需求习惯,大幅提升用户体验,满足用户的复杂功能需求,为现代复杂电子系统提供一体化的智能设计环境。
客户评价:
华勤通讯技术有限公司高级副总裁吴振海表示:“合见工软UniVista Archer PCB 、UniVista Archer Schematic产品在我们多个产品线进行了设计、验证。在使用合见工软的工具设计周期中,设计数据精准,符合我们公司的设计要求。另外合见工软的PCB工具支持导入行业内主流的PCB设计数据,其导入数据的完整性和还原度也非常优秀。除了产品本身,合见工软技术团队的支持力度和响应速度,让我们充分感受到EDA工具本土化的优势。”
合见工软现可提供覆盖“元器件库+数据管理+流程管理+设计工具”的电子系统级EDA的全流程解决方案。在系统级EDA工具的高端市场上,全面展示了合见工软公司产品的竞争。
欲了解更多详情或购买相关产品,欢迎垂询:sales@univista-isg.com
关于合见工软
上海合见工业软件集团有限公司(简称“合见工软”)作为自主创新的高性能工业软件及解决方案提供商,以EDA(电子设计自动化,Electronic Design Automation)领域为首先突破方向,致力于帮助半导体芯片企业解决在创新与发展过程中所面临的严峻挑战和关键问题,并成为他们值得信赖的合作伙伴。
了解更多详情,请访问:www.univista-isg.com
责任编辑:Ace
相关文章
-

- 半导体行业观察
-

- 摩尔芯闻
最新新闻
热门文章 本日 七天 本月
- 1 东方晶源YieldBook 3.0 “BUFF叠满” DMS+YMS+MMS三大系统赋能集成电路良率管理
- 2 NVIDIA重磅出击:三台计算机助力人形机器人飞跃
- 3 奕行智能(EVAS Intelligence)完成数亿元A轮融资,加速推出RISC-V计算芯片产品,共同助力新时代到来
- 4 智能驾驶拐点将至,地平线:向上捅破天,向下扎深根
热门评论
©2023 半导体行业观察
Copyright©2023 上海爱思尔教育科技有限公司 皖ICP备19011903号-2 皖公网安备 34019202000656号