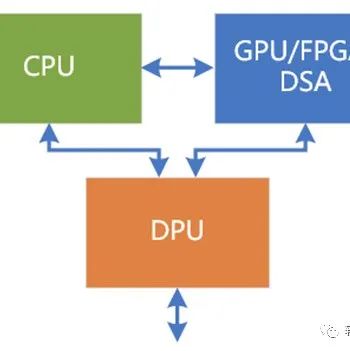
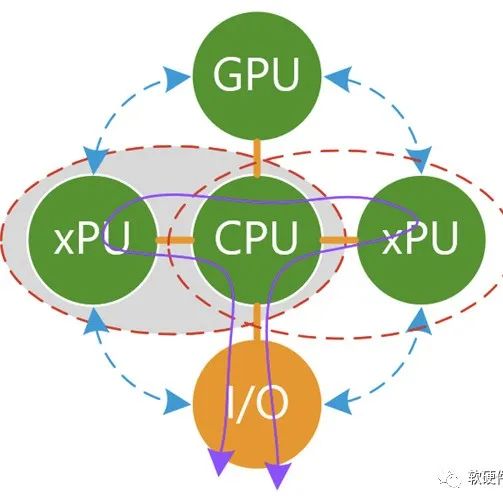
CPU将进入新时代:押注计算芯片的极限协同设计
2020-03-31
14:00:09
来源: 半导体行业观察
来源:内容由半导体行业观察(icbank)
编译自「
nextplatform
」,作者:Timothy Prickett Morgan,
谢谢。
我们现在进入了一个时代,那就是IT行业的计算引擎将需要比以往任何时候都更需要更低的价格,更好的性能以及更好的散热特性。这将需要一种在更大范围的工作负载和设备上进行协同设计系统(co-designing systems )的进化方法。
让我们从显而易见的地方开始。越来越清楚的是,尽管世界上所有软件工程师都可能使您相信,但通用计算的美好时代是一个简单的X86指令集和操作系统内核是他们唯一需要的画布。绘制他们的代码。
X86计算生态系统的兴起使我们在分布式计算和各种运行时中实现了出色的寒武纪爆炸式增长,以执行可跨X86变体以及Arm和Power等其他体系结构移植的高级代码。数据存储、数据库,应用程序框架,虚拟机和运行时的数量惊人,多样化且美观。如果确实发生了寒武纪大爆炸,那就是分布式计算模型和计算硬件的多样性(过去十年中一直在增长)确实是通用X86引擎的功能,后者可以完成所有工作,或者有时很多,虽然他们不是支持各种工作负载的最佳方法。
当工作负载,框架和硬件都对齐时,这是一件很美的事情。2012年就是这种情况,大约在HPC开始过渡到将代码的并行组件卸载到GPU加速器的五年之后,机器学习算法最终找到了足够的数据并具有足够的并行处理能力以采用数学上早在1980年代就听起来不错的算法,并将它们用于图像识别,语音识别,语音到文本翻译,视频识别和其他工作负载的测试。而且,lo和hehold,他们工作了。
现在AI的机器学习版本已经彻底改变了我们思考软件编写以及管理业务和个人生活许多方面的方式。HPC和AI统一对供应商和用户而言都非常方便,因为可以执行一组工作负载的相同系统也可以完成另一组工作,在某些情况下,它们可以串行或并行地交织以创建AI增强的HPC。但是,正如我们之前指出的那样,HPC和AI之间这种谐波收敛(harmonic convergence)的便利并不一定要保持,而只有在软件和经济朝着相同的方向推动时才如此。
在2020年的这一点上,很难说它是否会成立,但是很明显的是,橡树岭国家实验室的1.5 exaflops的“Frontier” 系统将于2021年到期,劳伦斯·利弗莫尔国家实验室的2 exaflops的“ El Capitan”系统定于2022年问世。相关资料显示,这个系统混合了CPU-GPU,两者之间具有紧密耦合的计算和一致的内存。他们指出,将AMD Epyc CPU和Radeon Instinct GPU加速器混合使用是正确的选择,这对新贵X86和GPU芯片制造商来说是福音。话虽如此,劳伦斯·利弗莫尔(Lawrence Livermore)绝对清楚,El Capitan主要是一台HPC机器,具有一些相对较小的AI职责。
现代的单片CPU或使用单个插槽中的小芯片(chiplets)之间的互连创建虚拟CPU的插槽,确实是一个奇迹。当我们看这些芯片中的一种时,我们正在看的是仅仅几十年前的超级计算机,它们将需要如此多的单个芯片来构建,以至于让人难以置信。让我们花点时间看一下这些艺术品,从英特尔的28核“ Skylake” Xeon SP 裸片开始:
甚至西摩·克雷(Seymour Cray)都会拿出放大镜,花几个小时观察这种美丽。克雷(Cray)将花费我们预期的等量时间,研究IBM的24核“ Nimbus” Power9处理器:
我们还没有Ampere的“ Quicksilver” Altra或Marvell的“ Triton” ThunderX3 这些Arm服务器CPU的裸片图,但是就组件数量而言,毫无疑问,它们将同样复杂。我们也没有构成AMD“罗马” Epyc 7002系列的九中芯片的集合,但是我们稍后将在此查看一些Rome原理图。
如果您细心看,你会发现现代服务器CPU就像二十年前的大型iron NUMA的外观,只是所有组件都缩减为一个裸片,他不仅包含CPU(今天称为内核),还包括L3缓存,PCI- Express和以太网控制器以及用于加密、数据压缩、内存压缩、矢量数学和十进制数学的各种加速器(IBM Power和System z都有)。如果您已经像我们一样从事了很长时间的行业,那么从大型NUMA服务器缩减到单个插槽的缩影确实是一个了不起的旅程。
有几件事很清楚。一方面,AMD在Rome方面的成功提供了一种设计良好的小芯片体系结构,即使从单片芯片迁移到小芯片设计时,即使对延迟产生影响,也可以提供性能和性价比方面的优势。在罗马走一走,看看:
Rome使用的Zen2内核的所有功能都优于Naples首次推出的Zen1内核,并且通过创建围绕单个I / O和内存控制器中枢的专用内核模块,大大改善了小芯片的互连体系结构。AMD这样做的所有意图和目的都是在单个14纳米管芯上混合了I / O和存储器控制器的NUMA控制器,该管芯由Globalfoundries制造,具有83.4亿个晶体管。
据了解,核心小芯片在单个裸片上具有两个四核核心复合体,其中八个裸片(骰子?)构成了总共64个核心,这些I / O核心都包裹在其中。每个核心小芯片都有39亿个晶体管,这些晶体管是由台积电在其7纳米工艺中蚀刻的,总共有322亿个晶体管用于计算。
全部加进去 Rome Epyc 7002小芯片工厂总共拥有395.4亿个晶体管,这肯定会超出任何代工厂的标线限制,而且要获得如此大芯片的良率也将变得更加疯狂。封装小芯片的麻烦,成本和风险不如制造标线片破坏单片服务器芯片的麻烦成本和风险大,至少对于拥有附属PC芯片业务的AMD而言,无论如何它都需要制造更小的芯片。
所有服务器CPU制造商迟早都将使用小芯片,但我们希望更加激进。我们希望将CPU分解为核心串行,整数处理要点,并撕裂所有已放置在芯片上的矢量引擎和加速器(这些整数引擎现在或在其旁边或在环形或网状互连中)。它们位于其他芯片中,它们属于一个世界,该世界将具有一致的系统间(CXL)和系统内(Gen-Z)一致协议集,以将计算元素捆绑在一起,以便它们可以以非对称方式共享内存或存储或symmetric fashion。
如果GPU加速器可以在64位或32位浮点处理上提供最佳的每瓦性能和每美元性能,那就可以了。将向量单元从CPU中取出,然后有两种选择:使芯片更小,更便宜,添加更多内核或提高时钟频率以创建性能更高或成本更低的串行整数计算引擎。
如果客户需要混合精度或更高精度的数据流引擎以及仅少量串行数据,主机计算,则可以将精简的CPU与FPGA紧密连接。并且假设至少要进行一些服务器虚拟化,尤其是在云和企业中,则应尽可能从服务器CPU上卸载这项工作。这意味着我们绝对假设每台服务器中都将有一个SmartNIC,可以像基板管理控制器(尚未发生的融合),服务器虚拟化或容器平台主机,以及可以运行虚拟网络和虚拟存储的地方一样工作,就像Amazon Web Services和Microsoft Azure一样。加密,解密,数据压缩和其他功能也可以从主机CPU中提取出来,并放入SmartNIC中,它们可以归为SmartNIC,并且可以用更少的钱完成。
最终,我们要优化专用芯片上的所有芯片性能,使其具有各种尺寸和容量,并具有互连功能,从而允许系统设计师以比超规模化者和云构建者所拥有的以太网更细粒度,更低的层次来混合它们。
试图做到这一点。这可能意味着socket的协议标准化,这可能将引致一些芯片制造商的抵制。但是有了这样的标准,系统架构师和芯片(实际上是socket)制造商可以拥有更广泛的计算选项板,用它们来绘制他们的许多工作负载,无论是在socket还是跨系统,或是它们的某种混合。
诚然,仍然会有那些想要通用服务器CPU的人,瑞士军刀可以完成所有工作。但是,我们谈论的是拥有一把剑,一把非常好的剪刀和一把无用的手锯,而是一系列微型版本的集合,这些版本最终并没有看上去有用。
*点击文末阅读原文,可阅读
英文
原文
。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第2265期内容,欢迎关注。
『
半导体第一垂直媒体
』
实时 专业 原创 深度
识别二维码
,回复下方关键词,阅读更多
存储|传感器
|IGBT
|
ARM
|FPGA
|中兴|苹果|半导体股价|IP
回复
投稿
,看《如何成为“半导体行业观察”的一员 》
回复
搜索
,还能轻松找到其他你感兴趣的文章!
责任编辑:Sophie